





深度学习算法模型
In the last article, we looked at models that deal with non-time-series data. Time to turn our heads towards some other models. Here we will be discussing deep sequential models. They are predominantly used to process/predict time series data.
在上一篇文章中 ,我们研究了处理非时间序列数据的模型。 是时候转向其他一些型号了。 在这里,我们将讨论深度顺序模型。 它们主要用于处理/预测时间序列数据。
Link to Part 1, in case you missed it.
链接到第1部分 ,以防您错过它。
简单递归神经网络(RNN)/ Elman网络 (Simple Recurrent Neural Networks (RNNs)/Elman Networks)
Simple recurrent neural networks (referred to also as RNNs) are to time-series problems as CNNs to computer vision. In a time-series problem, you feed a sequence of values to a model and ask it to predict the next n values of that sequence. RNNs go through each value of the sequence while building up memory of what it has seen which helps it to predict what the future will look like. (Learn more about RNNs [1] [2])
简单的递归神经网络(也称为RNN)将时间序列问题视为计算机视觉的CNN。 在时间序列问题中,您将一个值序列提供给模型,并要求其预测该序列的下n个值。 RNN会遍历序列的每个值,同时建立对已见结果的记忆,这有助于它预测未来的情况。 (了解有关RNN的更多信息[1] [2] )
打个比方:新的和改进的秘密火车 (Analogy: New and improved secret train)
I’ve played this game as a kid and you might know this by a different name. Kids are asked to stand in a line and you whisper the first kid in the line a random word. The kid should add an appropriate word to that word and whisper that to the next kid, and so on. By the time the message reaches the last kid, you should have an exciting story brewed up by kid’s imagination.
我小时候玩过这个游戏,您可能会用另一个名字知道这一点。 要求孩子们站成一排,然后您在行中的第一个孩子低声说悄悄话。 孩子应该在该单词上添加一个适当的单词,然后对下一个孩子说悄悄话,依此类推。 等到消息传到最后一个孩子的时候,您应该有了一个激动人心的故事,这个故事是由孩子的想象力酝酿的。
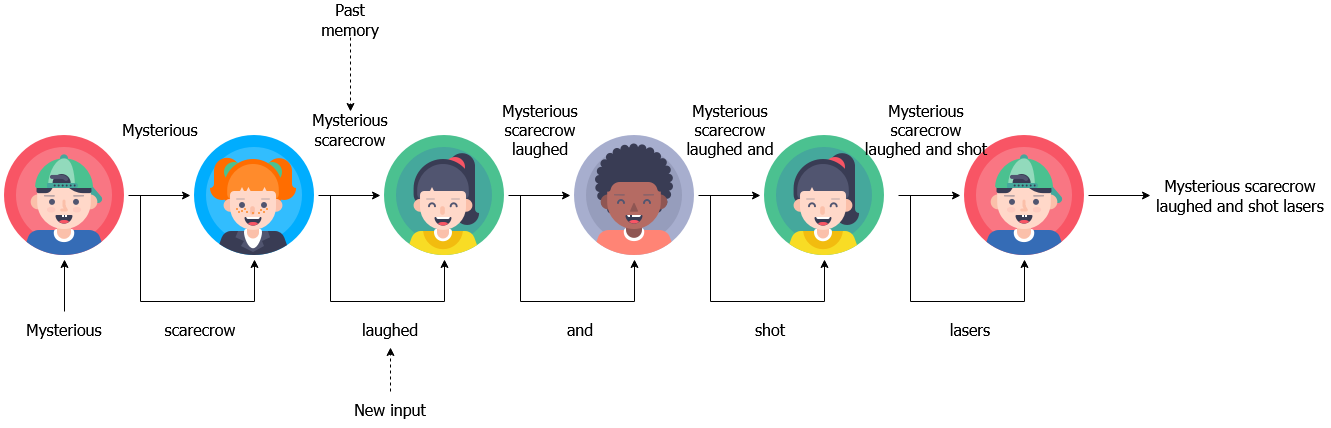
Enter simple RNNs! This is the crux of a RNN. It takes some input at time t — x(t) (new word from last kid) and a state from time t-1 — h(t-1) (previous words of the message) as inputs and produce an output — y(t) (previous message + new word from last kid + your new word).
输入简单的RNN! 这是RNN的关键。 它以时间t_x (t) (最后一个孩子的新单词)的输入和时间t-1 - h(t-1) (消息的先前单词)的状态作为输入,并产生输出y( t) (先前的讯息+最后一个孩子的新词+您的新词)。
Once you train a RNN, you can (but generally you won’t) keep predicting forever, because the prediction of time t (i.e. y(t)) becomes the input at t+1 (i.e. y(t)=x(t+1)). Here’s what an RNN looks like in real world.
训练完RNN后,您可以(但通常不会)永远预测,因为时间t的预测(即y(t) )成为t + 1的输入(即y(t)= x(t +1) )。 这是RNN在现实世界中的样子。

应用领域 (Applications)
- Time series prediction (e.g. weather / sales predictions) 时间序列预测(例如天气/销售预测)
- Sentiment analysis — Given a movie/product review ( a sequence of words), predict if that’s negative/positive/neutral. 情绪分析-给定电影/产品评论(一系列单词),预测其是否为负面/正面/中性。
Language modelling — Given a part of a story, imagine the rest of the story / Generate code from descriptions
语言建模-考虑到故事的一部分,请想象故事的其余部分/ 根据描述生成代码
长短期记忆网络 (Long Short-term memory networks)
LSTM is the cool new kid in RNN-ville. LSTM is a complicated beast than RNNs and able to remember things longer than RNNs. LSTMs would also go through each value of the sequence while building up memory of what it has seen which helps it to predict what the future will look like. But remember RNNs had a single state (that represented memory)? LSTMs have two states (one long-term and one short-term), thus the name LSTMs. (Learn more: LSTMs)
LSTM是RNN-ville的酷新手。 LSTM比RNN复杂,并且比RNN记忆的时间更长。 LSTM还将遍历序列的每个值,同时建立对所见内容的记忆,这有助于它预测未来的情况。 但是还记得RNN具有单一状态(代表内存)吗? LSTM具有两种状态(一种是长期的,一种是短期的),因此命名为LSTM。 (了解更多: LSTM )
打个比方:快餐连锁店 (Analogy: Fast-food chain)
All this explaining is making me hungry! So let’s go to a fast-food chain. This is a literal chain because, if you order a meal, one shop makes the burger, the other chips, and so on. In this fast-food drive through, you go to the first shop and say the following.
所有这些解释使我感到饥饿! 因此,让我们进入快餐连锁店。 这是一个字面意义上的连锁店,因为如果您点餐,那么一个店就在做汉堡,其他店在做汉堡,等等。 在这次快餐之旅中,您去了第一家商店,然后说了以下话。
I need a burger with a toasted tiger bun and grilled chicken.
我需要一个带烤老虎面包和烤鸡肉的汉堡。
There’s one person that takes the order (green), and would send that information to the red person, let’s say he toasted the bun. When communicating with the blue person, he can drop the toasted part and say,
有一个人下订单(绿色),然后将信息发送给红色人,比方说他敬酒了面包。 与蓝色人物交流时,他可以放下烘烤的部分,然后说:
a burger with a tiger bun and grilled chicken
一个汉堡,配老虎面包和烤鸡
(we still need the grilled part because the next shop decides the sauce based on that). Then you drive to the next shop and say,
(我们仍然需要烤制部分,因为下一家商店将根据烤制部分决定酱料)。 然后您开车去下一家商店,说:
Add cheddar, large chips and I’m wearing a green t-shirt
加上切达干酪,大薯条,我穿着绿色T恤
Now, the green person knows his t-shirt color is completely irrelevant and drops that part. The shop also gets information from both red and blue from the previous shop. Next they would add the sauce, prepare the chips. The red person in the second shop will hold most of the order instructions, in case we need that later (if the customer complaints). But he’ll only say,
现在,绿色人知道他的T恤颜色完全无关紧要,因此放弃了该部分。 该商店还从先前的商店中获得红色和蓝色的信息。 接下来,他们将加入酱汁,准备薯片。 如果我们以后需要(如果客户投诉),第二家商店的红色人员将持有大部分订购说明。 但是他只会说
A burger and large chips
汉堡和大薯条
to the blue person as that’s all he needs to do his job. And finally, you get your order from the output terminal of the second shop.
对蓝人来说,这就是他要做的全部工作。 最后,您可以从第二家商店的输出终端获得订单。

LSTMs are not far from how this chain operated. At a given time t, it takes,
LSTM与该链的运作方式相距不远。 在给定的时间t,
- an input x(t) (the customer in the example), 输入x(t)(在示例中为客户),
- an output state h(t-1) (the blue person from the previous shop) and 输出状态h(t-1)(先前商店的蓝色人物)和
- a cell state c(t-1) (the red person from the previous shop). 单元格状态c(t-1)(先前商店的红色人物)。
and produces,
并产生,
- an output state h(t) (the blue person in this shop) and 输出状态h(t)(这家商店中的蓝人),并且
- a cell state c(t) (the red person in this shop) 单元格状态c(t)(这家商店中的红色人)
But rather than doing direct computations on these elements, the LSTM has a gating mechanism, that it can use to decide how much information from these elements it allows to flow through. For example, remember what happened when the customer said “I’m wearing a green t-shirt at the second shop”, the green person (the input gate) dropped that information because it’s not important for the order. Another example is when the red person drops the part that the bun is toasted in the first shop. There are many gates in an LSTM cell. Namely,
但是,LSTM具有门控机制,而不是对这些元素进行直接计算,它可以用来确定允许这些元素从中流过多少信息。 例如,记住当客户说“我在第二家商店里穿着绿色的T恤”时,发生了什么情况,绿色的人(输入门)丢弃了该信息,因为这对订单并不重要。 另一个例子是,当红色的人掉下第一家商店里烤面包的部分时。 LSTM单元中有许多门。 即
- An input gate (the green person) — discard information that’s not useful in the input. 输入门(绿色人)-丢弃对输入无用的信息。
- A forget gate (part of red person) — discard information that’s not useful in the previous cell state 忘记门(红人的一部分)-丢弃在先前的电池状态下无用的信息
- An output gate (part of blue person)- Discard information that’s not useful from cell state, to generate the output state 输出门(蓝色人物的一部分)-丢弃对单元格状态无用的信息,以生成输出状态
As you can see, the interactions are complicated. But the main takeaway is that,
如您所见,交互非常复杂。 但主要的收获是,
An LSTM maintains two states (an output — short-term state and a cell state — long-term state) and uses gating to discard information when computing final and interim outputs.
LSTM维护两个状态(输出-短期状态和单元状态-长期状态),并在计算最终和临时输出时使用门控来丢弃信息。
Here’s what an LSTM would look like.
这就是LSTM的样子。

应用领域 (Applications)
- Same as RNNs 与RNN相同
门控循环单元(GRU) (Gated Recurrent Units (GRUs))
Phew! LSTMs really took a toll on time I got left. GRU is a successor to LSTMs that simplifies the mechanics of LSTMs future without jeopardising performance too much. (Learn more: GRUs [1] [2])
! 我离开时,LSTM确实造成了损失。 GRU是LSTM的后继产品,它简化了LSTM未来的机制,而又不会损害性能。 (了解更多:GRU [1] [2] )
打个比方:快餐连锁店v2.0 (Analogy: Fast-food chain v2.0)
Not to be a food critic, but the fast-food chain we saw earlier looks pretty inefficient. Is there a way to make it more efficient? Here’s one way.
不要成为食品评论家,但是我们前面看到的快餐连锁店看起来效率很低。 有办法提高效率吗? 这是一种方法。

- Get rid of the red person (cell state). Now both long and short term memories are managed by the green person (output state). 摆脱红色的人(细胞状态)。 现在,长期记忆和短期记忆都由绿色人员(输出状态)管理。
- There’s only an input gate and an output gate (i.e. no forget gate) 只有一个输入门和一个输出门(即,不要忘记门)
You can think of GRU as an inbetweener between simple RNN and LSTMs. Here’s what a GRU looks like.
您可以将GRU视为简单RNN和LSTM之间的中间人。 这就是GRU的样子。

应用范围: (Applications:)
- Same as RNNs 与RNN相同
结论 (Conclusion)
We looked at simple RNNs, LSTMs and GRUs. Here are the main take-aways.
我们研究了简单的RNN,LSTM和GRU。 这是主要的要点。
- Simple RNNs — A simple model that goes from one time step to the other while generating an output state on every step (no gating mechanism) 简单的RNN-一种简单的模型,它从一个时间步长过渡到另一个时间步长,同时在每个步骤上生成输出状态(无门控机制)
- LSTMs — Quite complicated. Has two states; a cell state (long-term) and an output state (short-term). It also has a gating mechanism to control how much information flows through the model. LSTM-非常复杂。 有两个状态; 单元状态(长期)和输出状态(短期)。 它还具有控制机制,可以控制有多少信息流过该模型。
- GRUs — An compromise between RNNs and LSTMs. Has only one output state but still has the gating mechanism. GRU — RNN和LSTM之间的折衷方案。 仅具有一种输出状态,但仍具有门控机制。
Next up would include the hottest topic in deep learning; the Transformers.
下一步将包括深度学习中最热门的话题; 变形金刚 。
以前的文章 (Previous articles)
Part 1: Feedforward models
第1部分 :前馈模型
深度学习算法模型















 7332
7332

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









