





火星开发板
数据科学家来自火星,软件开发人员来自金星(第1部分) (Data Scientists are from Mars and Software Developers are from Venus (Part 1))
Mars and Venus are very different planets. Mars’s atmosphere is very thin and it can get very cold; while Venus’s atmosphere is very thick and it can get very hot — hot enough to melt lead!. Yet they are our closest sister planets. They have a number of similarities too. Both have a high concentration of carbon-dioxide in their atmosphere and are exposed to solar radiation with no protective magnetic field.
火星和金星是非常不同的行星。 火星的气氛很稀薄,会变得很冷。 金星的气氛非常浓密,可能会变得非常热-足以熔化铅! 但是它们是我们最接近的姊妹行星。 它们也有许多相似之处。 两者在其大气中均具有高浓度的二氧化碳,并且暴露于无保护磁场的太阳辐射下。
Software Engineers and Data Scientists come from two different worlds — one from Venus and the other from Mars. They have different backgrounds mindsets, and deal with different sets of issues. They have a number of things in common too. In this and subsequent blogs we will look at the key differences (and similarities) between them and why those differences exist and what kind of bridge we need to create between them. In this blog, we explore the fundamental differences between software and models.
软件工程师和数据科学家来自两个不同的世界,一个来自金星,另一个来自火星。 他们具有不同的背景思维方式,并处理不同的问题。 他们也有很多共同点。 在本博客及其后续博客中,我们将研究它们之间的主要差异(和相似之处),为什么存在这些差异以及我们需要在它们之间建立什么样的桥梁。 在此博客中,我们探讨了软件和模型之间的根本差异。
软件与模型 (Software vs Models)
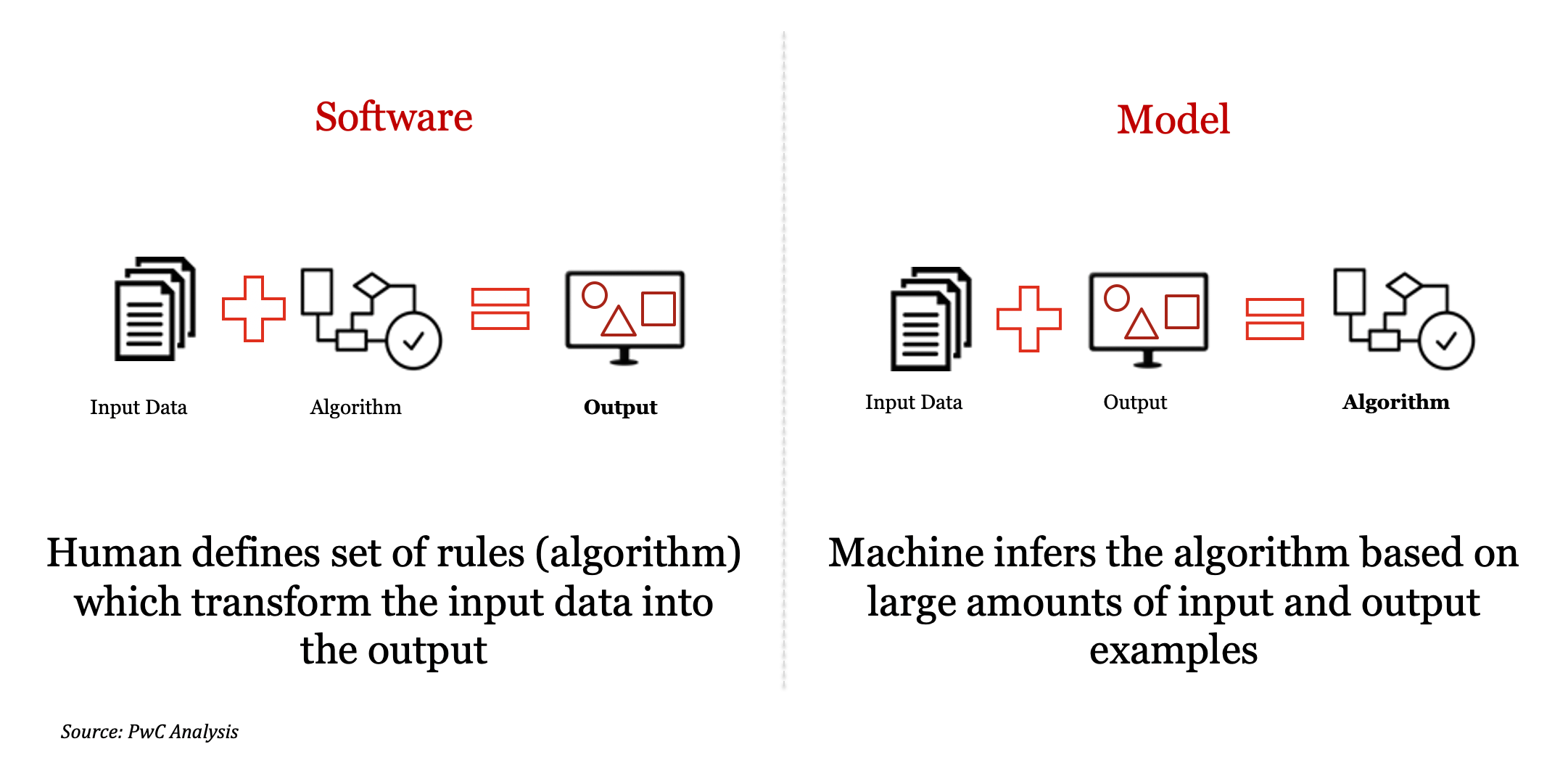
In traditional programming, one provides line-by-line instructions (often called an algorithm)for a computer to process the input data to produce the desired output that matches a given software specification. The line-by-line instructions can be in one of many computer languages e.g., Lisp, Prolog, C++, Java, Python, Julia etc.
在传统编程中,人们为计算机提供逐行指令(通常称为算法),以处理输入数据以产生与给定软件规范匹配的所需输出。 逐行指令可以使用多种计算机语言之一,例如Lisp,Prolog,C ++,Java,Python,Julia等。
In data science, one provides the input data and in some cases (e.g., supervised machine learning) a sample of the output data to build a model that can recognize the patterns in the input data. Unlike traditional programming, data science models are trained by providing input data (or input and output data) to recognize patterns or make inferences. When fully trained, validated, and tested they perform predictions or inferences on new data.
在数据科学中,人们提供输入数据,在某些情况下(例如,受监督的机器学习)提供输出数据的样本,以构建可以识别输入数据中的模式的模型。 与传统编程不同,数据科学模型是通过提供输入数据(或输入和输出数据)以识别模式或进行推论来训练的。 经过充分培训,验证和测试后,他们会对新数据进行预测或推断。
A model is a formal mathematical representation that can be applied to or calibrated to fit data. Scott Page provides a number of examples of models and how they are used to make decisions. Models can be machine learning models, system dynamic models, agent-based models, discrete event models or a number of other different types of mathematical representations. In this article, we will focus primarily on machine learning (ML) models.
模型是一种形式化的数学表示形式,可以应用于或校准以适合数据 。 Scott Page提供了许多模型示例以及如何将其用于决策。 模型可以是机器学习模型,系统动态模型,基于代理的模型,离散事件模型或许多其他不同类型的数学表示形式。 在本文中,我们将主要关注机器学习(ML)模型。
Software and models differ by five key dimensions. These dimensions are shown in Figure 3.
软件和模型在五个关键方面有所不同。 这些尺寸如图3所示。

输出量 (Output)
The output of software is certain. For example, consider an algorithm (e.g., bubblesort) for sorting an array of numbers. The bubblesort algorithm takes as input an array of numbers and iteratively goes through a series of steps to produce an output array that is sorted by ascending or descending order. Given any array the bubblesort algorithm will always produce a sorted array as output. There is no uncertainty in its output. If the program has been properly tested the algorithm will always produce the result and the result will be 100% accurate.
软件的输出是确定的 。 例如,考虑一种用于对数字数组进行排序的算法(例如,冒泡排序)。 bubbleort算法将一个数字数组作为输入,并反复执行一系列步骤以生成一个输出数组,该数组按升序或降序排序。 给定任何数组,bubblesort算法将始终生成排序后的数组作为输出。 它的输出没有不确定性。 如果程序已正确测试,则算法将始终产生结果,并且结果将是100%准确的。
In contrast, take a deep learning model that has been trained on a large number of images and is capable of recognizing different breeds of cats. When the model is provided as input a cat image, it uses the model to predict the breed of the cat. However, it may not always provide an answer with 100% accuracy — in fact, more often than not the accuracy will be less than 100%. Figure 3 illustrates the input, the deep learning network layers, and the output of a deep learning model. The model predicts that the image contains a tabby cat with 45% accuracy and could be an egyptian cat with 23% accuracy. In other words, the predictions from models are often uncertain. This uncertainty in predictions is a challenging concept for businesses to grasp. We will come back to the implications of this dimension to model development in a subsequent blog.
相反,采用深度学习模型,该模型已经在大量图像上进行了训练,并且能够识别不同种类的猫。 当提供模型作为输入的猫图像时,它将使用该模型预测猫的品种。 但是,它不一定总能提供100%的准确率的答案-实际上,准确率往往会低于100%。 图3展示了深度学习模型的输入,深度学习网络层和输出。 该模型预测该图像包含精度为45%的虎斑猫,并且可能是精度为23%的埃及猫。 换句话说,来自模型的预测通常是不确定的。 预测中的不确定性对于企业来说是一个具有挑战性的概念。 在后面的博客中,我们将回到这个维度对模型开发的含义。

决策空间 (Decision Space)
The second dimension of difference between software and models is the decision space. What we mean by decision space is the context in which the software or model is used for making decisions. When we build software we typically have a specification or a user need that is coded as an algorithm. The software is tested and when fully tested is available for use. The software gets executed to produce an outcome. This decision space is fixed or is static. If the needs of the user changes the algorithm has to be modified or rebuilt and tested. There is no promise of the algorithm learning or modifying itself. Figure 4 illustrates the context around how software gets used (an adaptation of how models are used from the book on Prediction Machines)
软件和模型之间差异的第二个维度是决策空间。 决策空间是指使用软件或模型进行决策的环境。 当我们构建软件时,通常会有规范或用户需求被编码为算法。 该软件已经过测试,可以在经过全面测试后使用。 执行该软件以产生结果。 该决策空间是固定的或静态的 。 如果用户的需求发生变化,则必须对算法进行修改或重建和测试。 该算法无法学习或自行修改。 图4说明了如何使用软件的上下文(对《 预测机器 》一书中模型的使用方式的改编)

When it comes to models the decision space is more dynamic. Consider a machine learning based chatbot that has been trained to provide first level support for queries related to smartphones. When the model was trained it would have been trained with historical data on make, model, accessories of different smartphones. Once deployed the chatbot will be able to answer customer queries on all the smartphones in the market. Let’s assume that when the chatbot is unable to answer queries beyond a certain level of accuracy it bounces the queries to a human customer service agent. Such a chatbot will work fine for a few months, but when new models and accessories are introduced in the market, the chatbot will be unable to respond to customer queries and will progressively transfer more and more calls to the human agent, eventually making the chatbot useless.
当涉及到模型时,决策空间更加动态 。 考虑一个基于机器学习的聊天机器人,该机器人已被训练为与智能手机相关的查询提供第一级支持。 训练模型时,将使用有关不同智能手机的制造商,模型,配件的历史数据进行训练。 一旦部署,聊天机器人将能够回答市场上所有智能手机上的客户查询。 假设聊天机器人无法回答超出一定准确度的查询时,会将查询反弹给人工客户服务代理。 这样的聊天机器人可以正常工作几个月,但是当市场上推出新型号和配件时,该聊天机器人将无法响应客户的查询,并将逐渐将越来越多的呼叫转移给人工代理,最终使该聊天机器人成为现实。无用。
Models rely on historical data and when that historical data is no longer relevant they need to be refreshed with newer data. This makes the context in which models operate more dynamic. While user needs or software specifications can also change, they happen less frequently. Moreover, there is no expectation that the software will continue to function when the specification changes. In the case of models there is a clear expectation that when the performance of the model deteriorates, at the very least we get alerted to this deterioration (often called model drift), or at best the outcomes and new data are used to continuously improve the model (we will come back to this issue of continuous improvement in a susbequent blog). Figure 5 illustrates the context around how models get used. Note the feedback loop from outcome to training (the red dotted lines have been added from the original diagram in Prediction Machines for emphasis). It is this feedback process that makes the decision space for models more dynamic.
模型依赖于历史数据,而当历史数据不再相关时,则需要使用更新的数据进行刷新。 这使得模型操作的环境更加动态。 尽管用户需求或软件规格也可以更改,但发生频率却较低。 此外,不期望在规格更改时软件将继续运行。 对于模型,有一个明确的期望,那就是当模型的性能下降时,至少我们会警惕这种下降(通常称为模型漂移),或者最好是将结果和新数据用于不断改进模型(我们将在一个持续不断的博客中讨论这个持续改进的问题)。 图5说明了如何使用模型的上下文。 注意从结果到训练的反馈循环(红色虚线已从Prediction Machines中的原始图中添加,以强调)。 正是这种反馈过程使模型的决策空间更加动态。

推理 (Inference)
Traditional software typically uses a deductive inferencing mechanism while machine learning models are based on inductive inferencing. As shown in Figure 6 a software specification acts as the theory from which the code is developed. The code can be viewed as the hypothesis that needs to be confirmed with the theory based on the observations. Observations are nothing but the output produced by the code that needs to be repeated tested against the specification.
传统软件通常使用演绎推理机制,而机器学习模型则基于归纳推理。 如图6所示,软件规范是从中开发代码的理论。 可以将代码视为假设,需要根据基于观察的理论来确认该假设。 观察仅是代码产生的输出,需要根据规范进行重复测试。
Models are patterns derived from observational data. The initial model acts like the hypothesis that needs to be iteratively refined to ensure that the model best matches the observational data. The trained model when validated captures the theory underlying the data. Sufficient care needs to be taken to ensure that the model does not over-fit or under-fit the data.
模型是从观测数据得出的模式。 初始模型的作用类似于假设,需要对其进行迭代完善以确保模型与观测数据最匹配。 经过验证的训练模型可以捕获数据基础的理论。 需要充分注意以确保模型不会过度拟合或不足拟合数据。
Moving from theory to observation as done by software is arguably easier than moving from observation to theory as done by models. This also highlights the challenge around the the certainty/uncertainty of the output as discussed in the first dimension.
可以说,由软件完成从理论到观察的转换要比模型完成从观察到理论的转换容易。 这也凸显了在第一维度中讨论的围绕输出的确定性/不确定性的挑战。

开发过程 (Development Process)
The process by which software is developed is also fundamentally different to the way models are typically developed. Software development typically follows a waterfall approach or an agile approach. The waterfall approach goes through a series of steps from specification to design to coding to testing and deployment. In the case of an agile approach the software development process is iterative and often embodies a set of principles centered around user needs and self-organizing, cross-functional teams. Software is typically developed in one to four week sprints. Each successive sprint encodes additional functionality leading to a minimum viable product that is released to users.
软件开发的过程也与典型的模型开发方法根本不同。 软件开发通常遵循瀑布式方法或敏捷方法。 瀑布式方法经历了从规范到设计再到编码再到测试和部署的一系列步骤。 在采用敏捷方法的情况下,软件开发过程是迭代的,并且通常体现出围绕用户需求和自组织,跨职能团队的一套原则。 软件通常在1-4周的冲刺中开发。 每个连续的sprint都会编码其他功能,从而使发布给用户的产品最少。
The model development process has to follow a somewhat different approach. The availability, quality, and labelling of data and the difficulty of estimating the desired accuracy or more generally the performance of the algorithm means that model development needs to take a portfolio approach. The data scientists need to develop a number of models and a subset of these models may meet the performance criteria. As a result the model development process needs to follow a more scientific process of experimentation, testing, and learning from these experiments to refine the next set of experiments. This process of hypothesize-test-learn does not fit well with an agile software development life cycle. In a subsequent blog, we will revisit the model development process and how it can be integrated with the agile approach.
模型开发过程必须遵循某种不同的方法。 数据的可用性,质量和标签以及估计所需精度的难度,或更普遍地说,算法的性能意味着模型开发需要采用组合方法。 数据科学家需要开发许多模型,这些模型的子集可能符合性能标准。 因此,模型开发过程需要遵循更科学的实验,测试过程以及从这些实验中学习的过程,以完善下一组实验。 假设测试学习的过程与敏捷软件开发生命周期不太吻合。 在随后的博客中,我们将回顾模型开发过程以及如何将其与敏捷方法集成。
心态 (Mindset)
The four dimensions we have addressed so far clearly separates the mindsets of those who build software and those who build models. Software developers typically have an engineering mindset — they work on architectural blueprints, connections between different components, and are typically responsible for production software. Software engineers typically have a computer science, information technology, or computer engineering background or education. They develop software products that create the data.
到目前为止,我们已经解决的四个方面清楚地将构建软件的人和构建模型的人的心态分开。 软件开发人员通常具有工程思维方式-他们负责架构蓝图,不同组件之间的连接,并且通常负责生产软件。 软件工程师通常具有计算机科学,信息技术或计算机工程背景或教育背景。 他们开发创建数据的软件产品。
Model developers, on the other hand, have more of a scientific mindset — they work on experiments, are better at dealing with ambiguity, and are typically interested in innovation as opposed to production models. A data scientist is someone who has augmented their mathematics and statistics background with programming to analyze data and develop mathematical models. They use data to draw insights and effect outcomes.
另一方面,模型开发人员则具有更多的科学思维方式-他们从事实验工作,更善于处理歧义,并且通常对创新而非生产模型感兴趣。 数据科学家是通过编程来增加数据和数学背景以分析数据和开发数学模型的人。 他们使用数据得出见解并影响结果。
In subsequent blogs, we will see the implication of these differences in how software and models get developed in organizations. We will also look at the model development process in detail, how they can be integrated with agile software development, and the emergence of new roles like ModelOps and MLEngineers.
在随后的博客中,我们将看到这些差异对组织中软件和模型的开发方式的影响。 我们还将详细研究模型开发过程,如何将它们与敏捷软件开发集成以及出现诸如ModelOps和MLEngineers之类的新角色。
Authors: Anand S. Rao and Joseph Voyles
火星开发板
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









