





nlp word2vec
摘要 (Summary)
In this article, using NLP and Python, I will explain 3 different strategies for text multiclass classification: the old-fashioned Bag-of-Words (with Tf-Idf ), the famous Word Embedding (with Word2Vec), and the cutting edge Language models (with BERT).
在本文中,我将使用NLP和Python来说明3种不同的文本多类分类策略:老式的词袋 (使用Tf-Idf) ,著名的词嵌入(使用Word2Vec)和最先进的语言型号 (带有BERT)。
NLP (Natural Language Processing) is the field of artificial intelligence that studies the interactions between computers and human languages, in particular how to program computers to process and analyze large amounts of natural language data. NLP is often applied for classifying text data. Text classification is the problem of assigning categories to text data according to its content.
NLP(自然语言处理)是人工智能领域,它研究计算机与人类语言之间的相互作用,尤其是如何对计算机进行编程以处理和分析大量自然语言数据。 NLP通常用于对文本数据进行分类。 文本分类是根据文本数据的内容为文本数据分配类别的问题。
There are different techniques to extract information from raw text data and use it to train a classification model. This tutorial compares the old school approach of Bag-of-Words (used with a simple machine learning algorithm), the popular Word Embedding model (used with a deep learning neural network), and the state of the art Language models (used with transfer learning from attention-based transformers) that have completely revolutionized the NLP landscape.
有多种技术可以从原始文本数据中提取信息,并使用它来训练分类模型。 本教程将比较传统的袋式单词方法 (与简单的机器学习算法一起使用),流行的单词嵌入模型(与深度学习神经网络一起使用)以及最新的语言模型 (与转移一起使用)向基于注意力的变压器学习)彻底改变了NLP的格局。
I will present some useful Python code that can be easily applied in other similar cases (just copy, paste, run) and walk through every line of code with comments so that you can replicate this example (link to the full code below).
我将展示一些有用的Python代码,这些代码可以轻松地应用于其他类似情况(只需复制,粘贴,运行),并在每行代码中添加注释,以便您可以复制此示例(链接至下面的完整代码)。
I will use the “News category dataset” in which you are provided with news headlines from the year 2012 to 2018 obtained from HuffPost and you are asked to classify them with the right category, therefore this is a multiclass classification problem (link below).
我将使用“ 新闻类别数据集 ”,向您提供从HuffPost获得的2012年至2018年的新闻标题,并要求您对它们进行正确的类别分类,因此这是一个多类别分类问题(下面的链接)。
In particular, I will go through:
特别是,我将经历:
- Setup: import packages, read data, Preprocessing, Partitioning. 设置:导入包,读取数据,预处理,分区。
Bag-of-Words: Feature Engineering & Feature Selection & Machine Learning with scikit-learn, Testing & Evaluation, Explainability with lime.
词袋:使用scikit-learn进行特征工程和特征选择以及机器学习,测试和评估,使用石灰进行解释 。
Word Embedding: Fitting a Word2Vec with gensim, Feature Engineering & Deep Learning with tensorflow/keras, Testing & Evaluation, Explainability with the Attention mechanism.
词嵌入:使用Gensim拟合Word2Vec ,使用tensorflow / keras进行特征工程和深度学习,测试和评估,使用Attention机制的可解释性 。
Language Models: Feature Engineering with transformers, Transfer Learning from pre-trained BERT with transformers and tensorflow/keras, Testing & Evaluation.
语言模型:具有变压器的特征工程,从具有变压器和tensorflow / keras的预训练BERT转移学习,测试和评估。
建立 (Setup)
First of all, I need to import the following libraries:
首先,我需要导入以下库:
## for dataimport jsonimport pandas as pd
import numpy as np## for plotting
import matplotlib.pyplot as plt
import seaborn as sns## for bag-of-words
from sklearn import feature_extraction, model_selection, naive_bayes, pipeline, manifold, preprocessing## for explainer
from lime import lime_text## for word embedding
import gensimimport gensim.downloader as gensim_api## for deep learning
from tensorflow.keras import models, layers, preprocessing as kprocessing
from tensorflow.keras import backend as K## for bert language model
import transformersThe dataset is contained into a json file, so I will first read it into a list of dictionaries with json and then transform it into a pandas Dataframe.
该数据集包含在一个json文件中,因此我将首先将其读取到带有json的词典列表中,然后将其转换为pandas Dataframe。
lst_dics = []
with open('data.json', mode='r', errors='ignore') as json_file:
for dic in json_file:
lst_dics.append( json.loads(dic) )## print the first one
lst_dics[0]
The original dataset contains over 30 categories, but for the purposes of this tutorial, I will work with a subset of 3: Entertainment, Politics, and Tech.
原始数据集包含30多个类别,但是出于本教程的目的,我将使用以下3个子集:娱乐,政治和科技。
## create dtf
dtf = pd.DataFrame(lst_dics)## filter categories
dtf = dtf[ dtf["category"].isin(['ENTERTAINMENT','POLITICS','TECH']) ][["category","headline"]]## rename columns
dtf = dtf.rename(columns={"category":"y", "headline":"text"})## print 5 random rows
dtf.sample(5)
In order to understand the composition of the dataset, I am going to look into the univariate distribution of the target by showing labels frequency with a bar plot.
为了理解数据集的组成,我将通过使用条形图显示标签频率来研究目标的单变量分布 。
fig, ax = plt.subplots()
fig.suptitle("y", fontsize=12)
dtf["y"].reset_index().groupby("y").count().sort_values(by=
"index").plot(kind="barh", legend=False,
ax=ax).grid(axis='x')
plt.show()
The dataset is imbalanced: the proportion of Tech news is really small compared to the others, this will make for models to recognize Tech news rather tough.
数据集不平衡:与其他新闻相比,技术新闻的比例确实很小,这将使模型很难识别技术新闻。
Before explaining and building the models, I am going to give an example of preprocessing by cleaning text, removing stop words, and applying lemmatization. I will write a function and apply it to the whole data set.
在解释和构建模型之前,我将给出一个预处理示例,该示例包括清理文本,删除停用词并应用词形化。 我将编写一个函数并将其应用于整个数据集。
'''
Preprocess a string.
:parameter
:param text: string - name of column containing text
:param lst_stopwords: list - list of stopwords to remove
:param flg_stemm: bool - whether stemming is to be applied
:param flg_lemm: bool - whether lemmitisation is to be applied
:return
cleaned text
'''
def utils_preprocess_text(text, flg_stemm=False, flg_lemm=True, lst_stopwords=None):
## clean (convert to lowercase and remove punctuations and
characters and then strip)
text = re.sub(r'[^\w\s]', '', str(text).lower().strip())
## Tokenize (convert from string to list)
lst_text = text.split() ## remove Stopwords
if lst_stopwords is not None:
lst_text = [word for word in lst_text if word not in
lst_stopwords]
## Stemming (remove -ing, -ly, ...)
if flg_stemm == True:
ps = nltk.stem.porter.PorterStemmer()
lst_text = [ps.stem(word) for word in lst_text]
## Lemmatisation (convert the word into root word)
if flg_lemm == True:
lem = nltk.stem.wordnet.WordNetLemmatizer()
lst_text = [lem.lemmatize(word) for word in lst_text]
## back to string from list
text = " ".join(lst_text)
return textThat function removes a set of words from the corpus if given. I can create a list of generic stop words for the English vocabulary with nltk (we could edit this list by adding or removing words).
该函数会从语料库中删除一组单词(如果有的话)。 我可以使用nltk为英语词汇创建通用停用词的列表(我们可以通过添加或删除单词来编辑此列表)。
lst_stopwords = nltk.corpus.stopwords.words("english")
lst_stopwords
Now I shall apply the function I wrote on the whole dataset and store the result in a new column named “text_clean” so that you can choose to work with the raw corpus or the preprocessed text.
现在,我将在整个数据集上应用我编写的函数,并将结果存储在名为“ text_clean ”的新列中,以便您可以选择使用原始语料库或预处理的文本。
dtf["text_clean"] = dtf["text"].apply(lambda x:
utils_preprocess_text(x, flg_stemm=False, flg_lemm=True,
lst_stopwords=lst_stopwords))dtf.head()
If you are interested in a deeper text analysis and preprocessing, you can check this article. With this in mind, I am going to partition the dataset into training set (70%) and test set (30%) in order to evaluate the models performance.
如果您对更深入的文本分析和预处理感兴趣,可以查看本文 。 考虑到这一点,我将数据集划分为训练集(70%)和测试集(30%),以评估模型的性能。
## split dataset
dtf_train, dtf_test = model_selection.train_test_split(dtf, test_size=0.3)## get target
y_train = dtf_train["y"].values
y_test = dtf_test["y"].valuesLet’s get started, shall we?
让我们开始吧,好吗?
言语袋 (Bag-of-Words)
The Bag-of-Words model is simple: it builds a vocabulary from a corpus of documents and counts how many times the words appear in each document. To put it another way, each word in the vocabulary becomes a feature and a document is represented by a vector with the same length of the vocabulary (a “bag of words”). For instance, let’s take 3 sentences and represent them with this approach:
“ 单词袋”模型很简单:它从文档语料库构建词汇表,并计算单词在每个文档中出现的次数。 换句话说,词汇表中的每个单词都成为一个特征,并且文档由具有相同词汇量长度的矢量(“单词袋”)表示。 例如,让我们用3个句子并用这种方法表示它们:

As you can imagine, this approach causes a significant dimensionality problem: the more documents you have the larger is the vocabulary, so the feature matrix will be a huge sparse matrix. Therefore, the Bag-of-Words model is usually preceded by an important preprocessing (word cleaning, stop words removal, stemming/lemmatization) aimed to reduce the dimensionality problem.
可以想象,这种方法会导致一个严重的维度问题:您拥有的文档越多,词汇量就越大,因此特征矩阵将是一个巨大的稀疏矩阵。 因此,“词袋”模型通常先进行重要的预处理(词清除,停用词去除,词干/词义化),以减少维数问题。
Terms frequency is not necessarily the best representation for text. In fact, you can find in the corpus common words with the highest frequency but little predictive power over the target variable. To address this problem there is an advanced variant of the Bag-of-Words that, instead of simple counting, uses the term frequency–inverse document frequency (or Tf–Idf). Basically, the value of a word increases proportionally to count, but it is inversely proportional to the frequency of the word in the corpus.
术语频率不一定是文本的最佳表示。 实际上,您可以在语料库中找到频率最高但对目标变量的预测能力很小的常用词。 为了解决这个问题,有一个词袋的高级变体,而不是简单的计数,而是使用频率-文档倒频 (或Tf-Idf ) 。 基本上,一个单词的值与计数成正比地增加,但是它与该单词在语料库中的出现频率成反比。
Let’s start with the Feature Engineering, the process to create features by extracting information from the data. I am going to use the Tf-Idf vectorizer with a limit of 10,000 words (so the length of my vocabulary will be 10k), capturing unigrams (i.e. “new” and “york”) and bigrams (i.e. “new york”). I will provide the code for the classic count vectorizer as well:
让我们从特征工程开始,该过程是通过从数据中提取信息来创建特征的过程。 我将使用Tf-Idf矢量化程序,其限制为10,000个单词(因此,我的词汇量将为10k),捕获unigram(即“ new ”和“ york ”)和bigrams(即“ new york ”)。 我还将提供经典计数矢量化器的代码:
## Count (classic BoW)vectorizer = feature_extraction.text.CountVectorizer(max_features=10000, ngram_range=(1,2))## Tf-Idf (advanced variant of BoW)
vectorizer = feature_extraction.text.TfidfVectorizer(max_features=10000, ngram_range=(1,2))Now I will use the vectorizer on the preprocessed corpus of the train set to extract a vocabulary and create the feature matrix.
现在,我将在火车集的预处理语料库上使用矢量化程序提取词汇表并创建特征矩阵。
corpus = dtf_train["text_clean"]vectorizer.fit(corpus)
X_train = vectorizer.transform(corpus)
dic_vocabulary = vectorizer.vocabulary_The feature matrix X_train has a shape of 34,265 (Number of documents in training) x 10,000 (Length of vocabulary) and it’s pretty sparse:
特征矩阵X_train的形状为34,265(正在训练的文档数)x 10,000(词汇长度),并且非常稀疏:
sns.heatmap(X_train.todense()[:,np.random.randint(0,X.shape[1],100)]==0, vmin=0, vmax=1, cbar=False).set_title('Sparse Matrix Sample')
In order to know the position of a certain word, we can look it up in the vocabulary:
为了知道某个单词的位置,我们可以在词汇表中查找它:
word = "new york"dic_vocabulary[word]If the word exists in the vocabulary, this command prints a number N, meaning that the Nth feature of the matrix is that word.
如果单词存在于词汇表中,则此命令将打印数字N ,这意味着矩阵的第N个特征就是该单词。
In order to drop some columns and reduce the matrix dimensionality, we can carry out some Feature Selection, the process of selecting a subset of relevant variables. I will proceed as follows:
为了删除某些列并降低矩阵维数,我们可以执行一些Feature Selection ,即选择相关变量子集的过程。 我将进行如下操作:
- treat each category as binary (for example, the “Tech” category is 1 for the Tech news and 0 for the others); 将每个类别都视为二进制(例如,“技术”类别对于“技术新闻”来说是1,对于其他新闻是0);
perform a Chi-Square test to determine whether a feature and the (binary) target are independent;
执行卡方检验以确定特征和(二进制)目标是否独立;
- keep only the features with a certain p-value from the Chi-Square test. 仅保留卡方检验中具有特定p值的要素。
y = dtf_train["y"]
X_names = vectorizer.get_feature_names()
p_value_limit = 0.95dtf_features = pd.DataFrame()
for cat in np.unique(y):
chi2, p = feature_selection.chi2(X_train, y==cat)
dtf_features = dtf_features.append(pd.DataFrame(
{"feature":X_names, "score":1-p, "y":cat}))
dtf_features = dtf_features.sort_values(["y","score"],
ascending=[True,False])
dtf_features = dtf_features[dtf_features["score"]>p_value_limit]X_names = dtf_features["feature"].unique().tolist()I reduced the number of features from 10,000 to 3,152 by keeping the most statistically relevant ones. Let’s print some:
我保留了统计上最相关的功能,将功能的数量从10,000个减少到3,152个。 让我们打印一些:
for cat in np.unique(y):
print("# {}:".format(cat))
print(" . selected features:",
len(dtf_features[dtf_features["y"]==cat]))
print(" . top features:", ",".join(
dtf_features[dtf_features["y"]==cat]["feature"].values[:10]))
print(" ")
We can refit the vectorizer on the corpus by giving this new set of words as input. That will produce a smaller feature matrix and a shorter vocabulary.
我们可以通过提供这组新的单词作为输入来在语料库上重新设置矢量化程序。 这将产生较小的特征矩阵和较短的词汇表。
vectorizer = feature_extraction.text.TfidfVectorizer(vocabulary=X_names)vectorizer.fit(corpus)
X_train = vectorizer.transform(corpus)
dic_vocabulary = vectorizer.vocabulary_The new feature matrix X_train has a shape of is 34,265 (Number of documents in training) x 3,152 (Length of the given vocabulary). Let’s see if the matrix is less sparse:
新特征矩阵X_train的形状为34265(正在训练的文档数)x 3152(给定词汇的长度)。 让我们看看矩阵是否稀疏:

It’s time to train a machine learning model and test it. I recommend using a Naive Bayes algorithm: a probabilistic classifier that makes use of Bayes’ Theorem, a rule that uses probability to make predictions based on prior knowledge of conditions that might be related. This algorithm is the most suitable for such large dataset as it considers each feature independently, calculates the probability of each category, and then predicts the category with the highest probability.
现在该训练机器学习模型并对其进行测试了。 我建议使用朴素贝叶斯算法:一种利用贝叶斯定理的概率分类器,该规则使用概率基于对可能相关条件的先验知识进行预测。 该算法最适合此类大型数据集,因为它独立考虑每个特征,计算每个类别的概率,然后以最高概率预测该类别。
classifier = naive_bayes.MultinomialNB()I’m going to train this classifier on the feature matrix and then test it on the transformed test set. To that end, I need to build a scikit-learn pipeline: a sequential application of a list of transformations and a final estimator. Putting the Tf-Idf vectorizer and the Naive Bayes classifier in a pipeline allows us to transform and predict test data in just one step.
我将在特征矩阵上训练此分类器,然后在转换后的测试集上对其进行测试。 为此,我需要构建一个scikit-learn管道:一个转换列表和一个最终估计器的顺序应用程序。 将Tf-Idf矢量化器和朴素贝叶斯分类器放在一条管道中,使我们只需一步即可转换和预测测试数据。
## pipeline
model = pipeline.Pipeline([("vectorizer", vectorizer),
("classifier", classifier)])## train classifiermodel["classifier"].fit(X_train, y_train)## testX_test = dtf_test["text_clean"].values
predicted = model.predict(X_test)
predicted_prob = model.predict_proba(X_test)We can now evaluate the performance of the Bag-of-Words model, I will use the following metrics:
现在,我们可以评估话语袋模型的性能,我将使用以下指标:
- Accuracy: the fraction of predictions the model got right. 准确性:模型预测正确的分数。
- Confusion Matrix: a summary table that breaks down the number of correct and incorrect predictions by each class. 混淆矩阵:汇总表,按每个类别细分正确和不正确的预测数。
- ROC: a plot that illustrates the true positive rate against the false positive rate at various threshold settings. The area under the curve (AUC) indicates the probability that the classifier will rank a randomly chosen positive observation higher than a randomly chosen negative one. ROC:说明在各种阈值设置下,真实阳性率与假阳性率的关系图。 曲线下的面积(AUC)表示分类器将随机选择的阳性观察结果的排名高于随机选择的阴性观察结果的概率。
- Precision: the fraction of relevant instances among the retrieved instances. 精度:相关实例在检索到的实例中所占的比例。
- Recall: the fraction of the total amount of relevant instances that were actually retrieved. 回忆:实际检索到的相关实例总数的一部分。
classes = np.unique(y_test)
y_test_array = pd.get_dummies(y_test, drop_first=False).values
## Accuracy, Precision, Recall
accuracy = metrics.accuracy_score(y_test, predicted)
auc = metrics.roc_auc_score(y_test, predicted_prob,
multi_class="ovr")
print("Accuracy:", round(accuracy,2))
print("Auc:", round(auc,2))
print("Detail:")
print(metrics.classification_report(y_test, predicted))
## Plot confusion matrix
cm = metrics.confusion_matrix(y_test, predicted)
fig, ax = plt.subplots()
sns.heatmap(cm, annot=True, fmt='d', ax=ax, cmap=plt.cm.Blues,
cbar=False)
ax.set(xlabel="Pred", ylabel="True", xticklabels=classes,
yticklabels=classes, title="Confusion matrix")
plt.yticks(rotation=0)
fig, ax = plt.subplots(nrows=1, ncols=2)## Plot roc
for i in range(len(classes)):
fpr, tpr, thresholds = metrics.roc_curve(y_test_array[:,i],
predicted_prob[:,i])
ax[0].plot(fpr, tpr, lw=3,
label='{0} (area={1:0.2f})'.format(classes[i],
metrics.auc(fpr, tpr))
)
ax[0].plot([0,1], [0,1], color='navy', lw=3, linestyle='--')
ax[0].set(xlim=[-0.05,1.0], ylim=[0.0,1.05],
xlabel='False Positive Rate',
ylabel="True Positive Rate (Recall)",
title="Receiver operating characteristic")
ax[0].legend(loc="lower right")
ax[0].grid(True)
## Plot precision-recall curvefor i in range(len(classes)):
precision, recall, thresholds = metrics.precision_recall_curve(
y_test_array[:,i], predicted_prob[:,i])
ax[1].plot(recall, precision, lw=3,
label='{0} (area={1:0.2f})'.format(classes[i],
metrics.auc(recall, precision))
)
ax[1].set(xlim=[0.0,1.05], ylim=[0.0,1.05], xlabel='Recall',
ylabel="Precision", title="Precision-Recall curve")
ax[1].legend(loc="best")
ax[1].grid(True)
plt.show()
The BoW model got 85% of the test set right (Accuracy is 0.85), but struggles to recognize Tech news (only 252 predicted correctly).
BoW模型获得了85%的测试设置权(准确度为0.85),但难以识别技术新闻(只有252个正确预测)。
Let’s try to understand why the model classifies news with a certain category and assess the explainability of these predictions. The lime package can help us to build an explainer. To give an illustration, I will take a random observation from the test set and see what the model predicts and why.
让我们尝试了解模型为何将新闻分类为特定类别,并评估这些预测的可解释性 。 石灰包可以帮助我们构建解释器。 为了举例说明,我将从测试集中进行随机观察,并查看模型的预测结果以及原因。
## select observationi = 0
txt_instance = dtf_test["text"].iloc[i]## check true value and predicted value
print("True:", y_test[i], "--> Pred:", predicted[i], "| Prob:", round(np.max(predicted_prob[i]),2))## show explanation
explainer = lime_text.LimeTextExplainer(class_names=
np.unique(y_train))
explained = explainer.explain_instance(txt_instance,
model.predict_proba, num_features=3)
explained.show_in_notebook(text=txt_instance, predict_proba=False)

That makes sense: the words “Clinton” and “GOP” pointed the model in the right direction (Politics news) even if the word “Stage” is more common among Entertainment news.
这是有道理的:“ 克林顿 ”和“ 共和党 ”一词将模型指向正确的方向(政治新闻),即使在娱乐新闻中更常见“ 舞台 ”一词。
词嵌入 (Word Embedding)
Word Embedding is the collective name for feature learning techniques where words from the vocabulary are mapped to vectors of real numbers. These vectors are calculated from the probability distribution for each word appearing before or after another. To put it another way, words of the same context usually appear together in the corpus, so they will be close in the vector space as well. For instance, let’s take the 3 sentences from the previous example:
词嵌入是特征学习技术的统称,其中词汇表中的词映射到实数向量。 这些矢量是根据出现在另一个单词之前或之后的每个单词的概率分布计算得出的。 换句话说,具有相同上下文的单词通常在语料库中一起出现,因此它们在向量空间中也很接近。 例如,让我们从前面的示例中提取3个句子:

In this tutorial, I’m going to use the first model of this family: Google’s Word2Vec (2013). Other popular Word Embedding models are Stanford’s GloVe (2014) and Facebook’s FastText (2016).
在本教程中,我将使用该系列的第一个模型:Google的Word2Vec (2013)。 其他流行的单词嵌入模型是斯坦福大学的GloVe (2014年) 和Facebook的FastText (2016)。
Word2Vec produces a vector space, typically of several hundred dimensions, with each unique word in the corpus such that words that share common contexts in the corpus are located close to one another in the space. That can be done using 2 different approaches: starting from a single word to predict its context (Skip-gram) or starting from the context to predict a word (Continuous Bag-of-Words).
Word2Vec生成一个矢量空间,通常具有几百个维度,而语料库中的每个唯一单词都使得在语料库中共享公共上下文的单词在空间中彼此靠近。 这可以使用两种不同的方法来完成:从单个单词开始以预测其上下文( Skip-gram )或从上下文开始以预测一个单词( Continuous Bag-of-Words )。
In Python, you can load a pre-trained Word Embedding model from genism-data like this:
在Python中,您可以从genism-data加载预训练的词嵌入模型 像这样:
nlp = gensim_api.load("word2vec-google-news-300")Instead of using a pre-trained model, I am going to fit my own Word2Vec on the training data corpus with gensim. Before fitting the model, the corpus needs to be transformed into a list of lists of n-grams. In this particular case, I’ll try to capture unigrams (“york”), bigrams (“new york”), and trigrams (“new york city”).
我将不使用预先训练的模型,而是使用gensim将我自己的Word2Vec拟合到训练数据语料库中。 在拟合模型之前,需要将语料库转换为n-gram列表。 在这种情况下,我将尝试捕获单字组(“ 纽约 ”),二元组(“ 纽约 ”)和三字组(“ 纽约城 ”)。
corpus = dtf_train["text_clean"]
## create list of lists of unigrams
lst_corpus = []
for string in corpus:
lst_words = string.split()
lst_grams = [" ".join(lst_words[i:i+1])
for i in range(0, len(lst_words), 1)]
lst_corpus.append(lst_grams)
## detect bigrams and trigrams
bigrams_detector = gensim.models.phrases.Phrases(lst_corpus,
delimiter=" ".encode(), min_count=5, threshold=10)
bigrams_detector = gensim.models.phrases.Phraser(bigrams_detector)trigrams_detector = gensim.models.phrases.Phrases(bigrams_detector[lst_corpus],
delimiter=" ".encode(), min_count=5, threshold=10)
trigrams_detector = gensim.models.phrases.Phraser(trigrams_detector)When fitting the Word2Vec, you need to specify:
在安装Word2Vec时,您需要指定:
- the target size of the word vectors, I’ll use 300; 字向量的目标大小,我将使用300;
- the window, or the maximum distance between the current and predicted word within a sentence, I’ll use the mean length of text in the corpus; 窗口,或句子中当前词与预测词之间的最大距离,我将使用语料库中文本的平均长度;
- the training algorithm, I’ll use skip-grams (sg=1) as in general it has better results. 训练算法中,我将使用skip-grams(sg = 1),因为通常情况下效果更好。
## fit w2v
nlp = gensim.models.word2vec.Word2Vec(lst_corpus, size=300,
window=8, min_count=1, sg=1, iter=30)We have our embedding model, so we can select any word from the corpus and transform it into a vector.
我们有嵌入模型,因此我们可以从语料库中选择任何单词并将其转换为向量。
word = "data"
nlp[word].shape
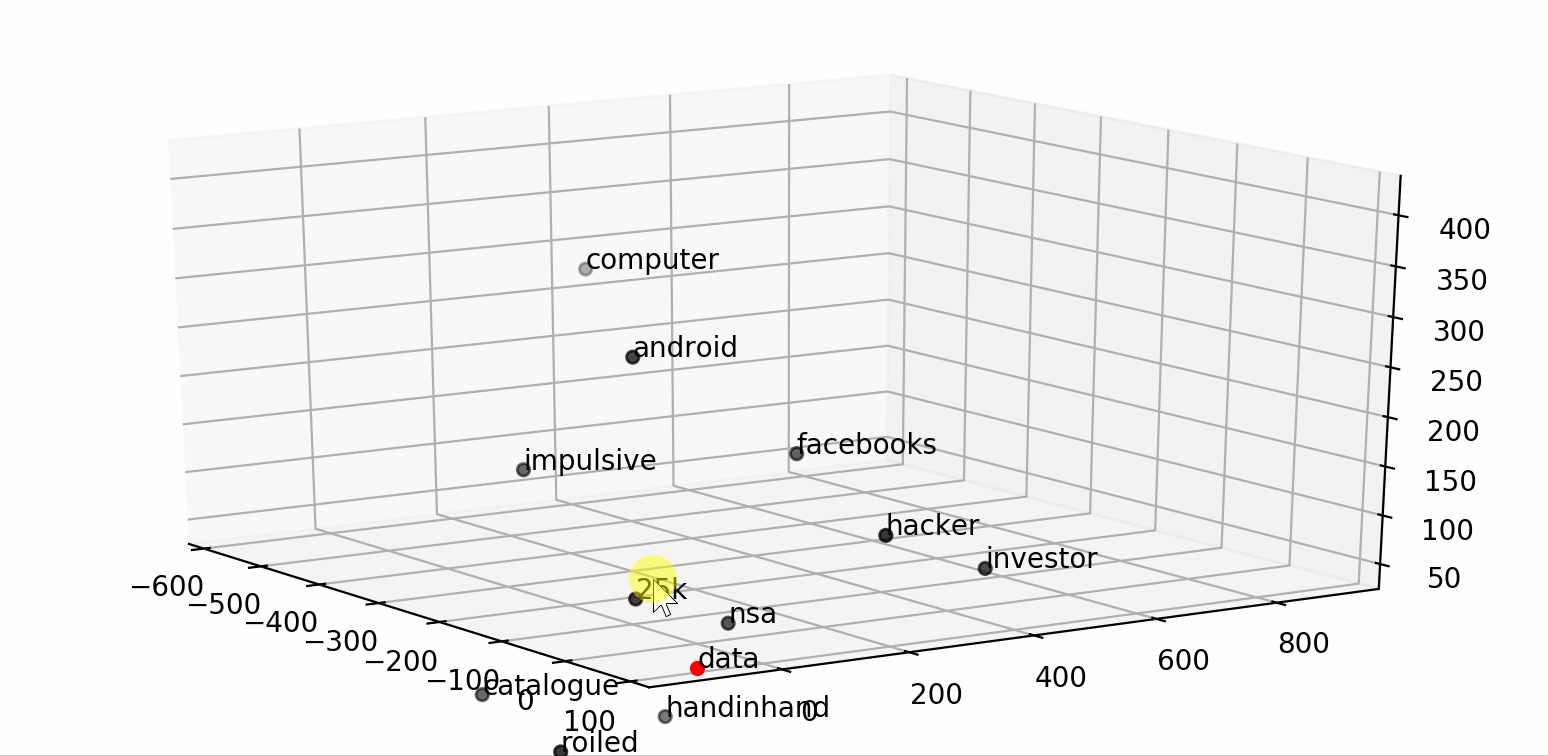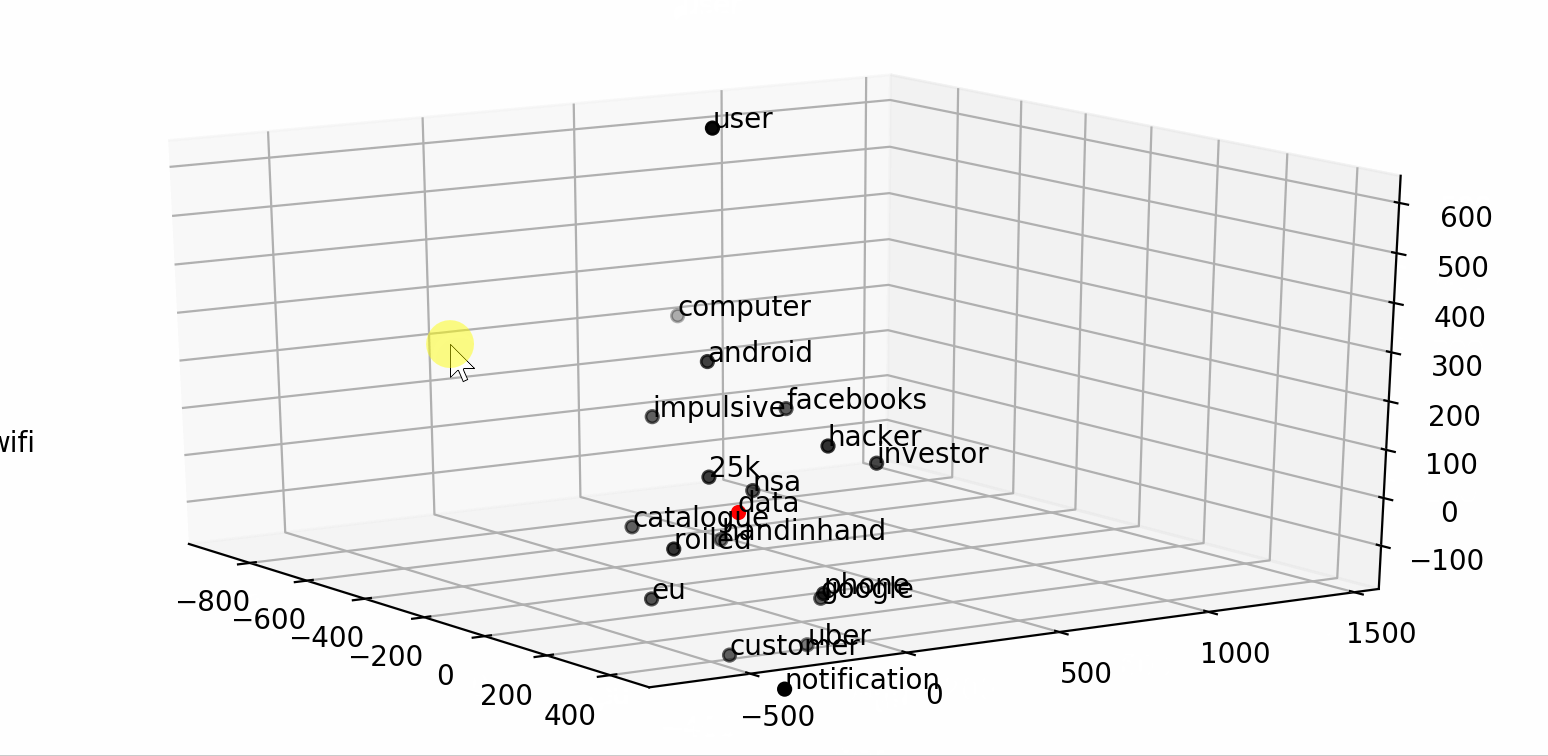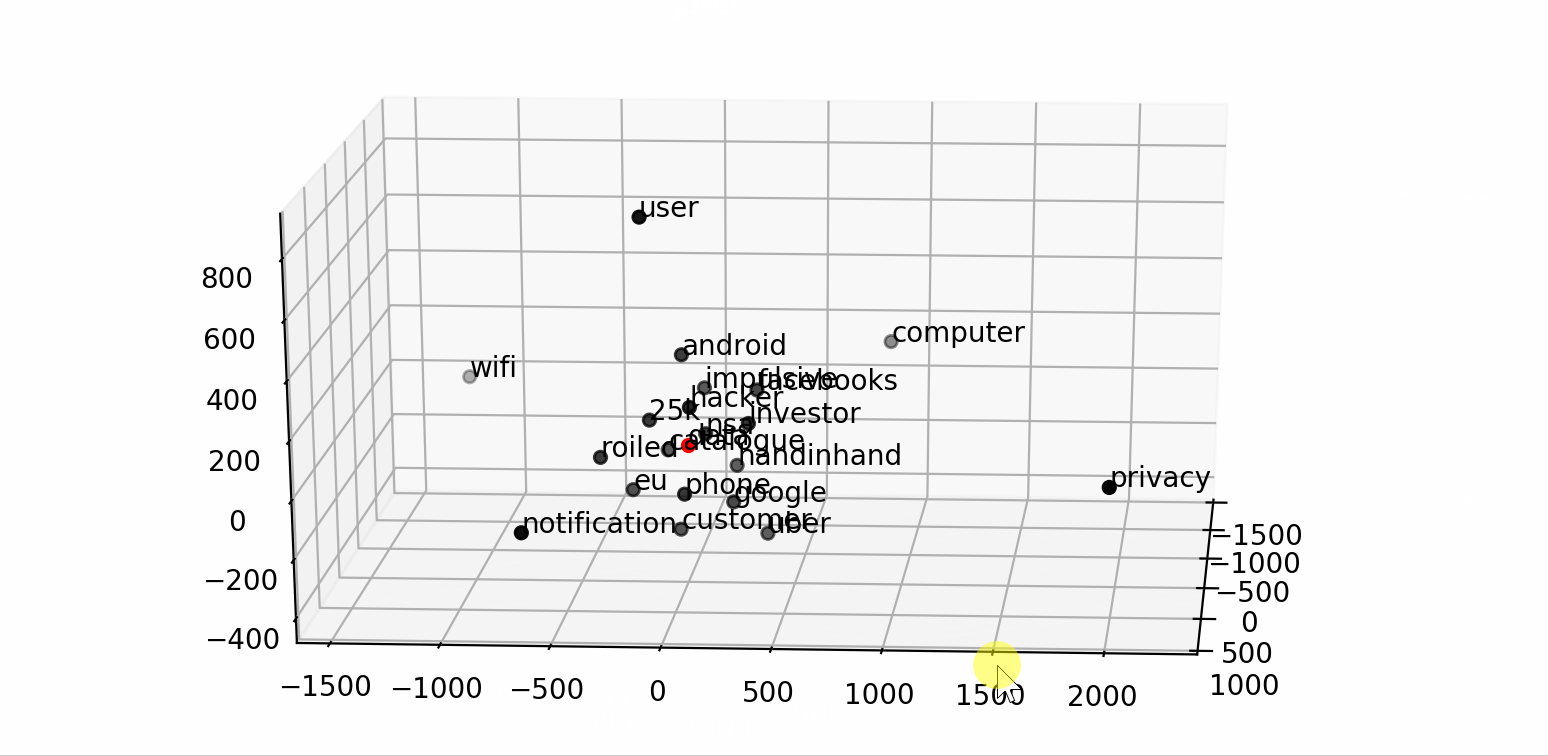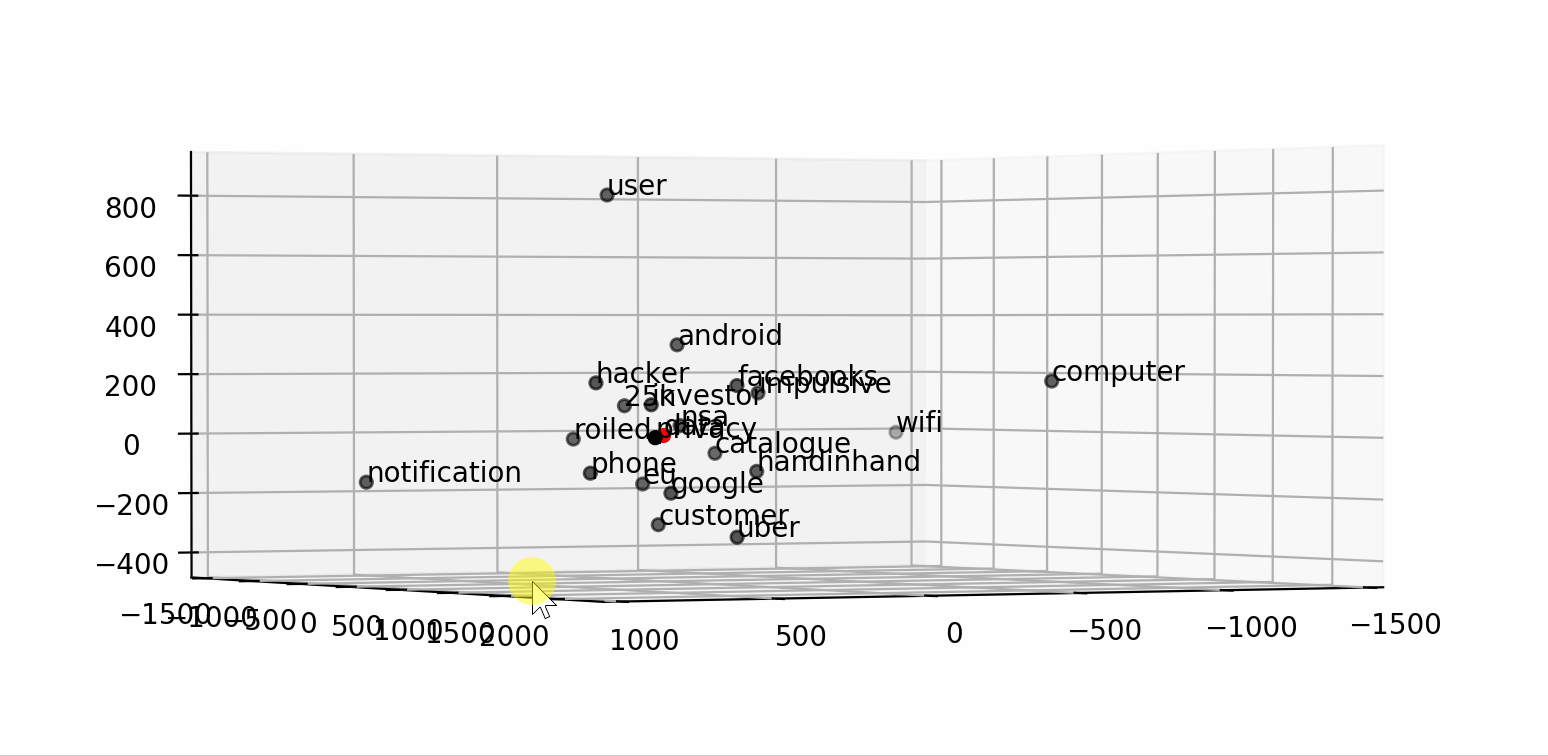
We can even use it to visualize a word and its context into a smaller dimensional space (2D or 3D) by applying any dimensionality reduction algorithm (i.e. TSNE).
通过应用任何降维算法(即TSNE ),我们甚至可以使用它来将单词及其上下文可视化到较小的维空间(2D或3D)中。
word = "data"
fig = plt.figure()## word embedding
tot_words = [word] + [tupla[0] for tupla in
nlp.most_similar(word, topn=20)]
X = nlp[tot_words]## pca to reduce dimensionality from 300 to 3
pca = manifold.TSNE(perplexity=40, n_components=3, init='pca')
X = pca.fit_transform(X)## create dtf
dtf_ = pd.DataFrame(X, index=tot_words, columns=["x","y","z"])
dtf_["input"] = 0
dtf_["input"].iloc[0:1] = 1## plot 3d
from mpl_toolkits.mplot3d import Axes3D
ax = fig.add_subplot(111, projection='3d')
ax.scatter(dtf_[dtf_["input"]==0]['x'],
dtf_[dtf_["input"]==0]['y'],
dtf_[dtf_["input"]==0]['z'], c="black")
ax.scatter(dtf_[dtf_["input"]==1]['x'],
dtf_[dtf_["input"]==1]['y'],
dtf_[dtf_["input"]==1]['z'], c="red")
ax.set(xlabel=None, ylabel=None, zlabel=None, xticklabels=[],
yticklabels=[], zticklabels=[])
for label, row in dtf_[["x","y","z"]].iterrows():
x, y, z = row
ax.text(x, y, z, s=label)That’s pretty cool and all, but how can the word embedding be useful to predict the news category? Well, the word vectors can be used in a neural network as weights. This is how:
那很酷,但是,单词嵌入如何对预测新闻类别有用呢? 好吧,单词向量可以在神经网络中用作权重。 这是这样的:
- First, transform the corpus into padded sequences of word ids to get a feature matrix. 首先,将语料库转换为单词id的填充序列,以获得特征矩阵。
Then, create an embedding matrix so that the vector of the word with id N is located at the Nth row.
然后,创建一个嵌入矩阵,以使ID为N的单词的向量位于第N行。
- Finally, build a neural network with an embedding layer that weighs every word in the sequences with the corresponding vector. 最后,构建一个具有嵌入层的神经网络,该嵌入层将权重序列中的每个单词以及相应的向量。
Let’s start with the Feature Engineering by transforming the same preprocessed corpus (list of lists of n-grams) given to the Word2Vec into a list of sequences using tensorflow/keras:
让我们从特征工程学开始,使用tensorflow / keras将给Word2Vec的相同预处理语料库(n-gram列表的列表)转换为序列列表:
## tokenize text
tokenizer = kprocessing.text.Tokenizer(lower=True, split=' ',
oov_token="NaN",
filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n')
tokenizer.fit_on_texts(lst_corpus)
dic_vocabulary = tokenizer.word_index## create sequence
lst_text2seq= tokenizer.texts_to_sequences(lst_corpus)## padding sequence
X_train = kprocessing.sequence.pad_sequences(lst_text2seq,
maxlen=15, padding="post", truncating="post")The feature matrix X_train has a shape of 34,265 x 15 (Number of sequences x Sequences max length). Let’s visualize it:
特征矩阵X_train的形状为34,265 x 15(序列数x序列最大长度)。 让我们对其进行可视化:
sns.heatmap(X_train==0, vmin=0, vmax=1, cbar=False)
plt.show()
Every text in the corpus is now an id sequence with length 15. For instance, if a text had 10 tokens in it, then the sequence is composed of 10 ids + 5 0s, which is the padding element (while the id for word not in the vocabulary is 1). Let’s print how a text from the train set has been transformed into a sequence with the padding and the vocabulary.
现在,语料库中的每个文本都是一个长度为15的id序列。例如,如果文本中有10个标记,则该序列由10个ids + 5 0s组成,这是padding元素(而单词的id不是词汇中的是1)。 让我们打印如何将训练集中的文本转换为带有填充和词汇的序列。
i = 0## list of text: ["I like this", ...]
len_txt = len(dtf_train["text_clean"].iloc[i].split())
print("from: ", dtf_train["text_clean"].iloc[i], "| len:", len_txt)## sequence of token ids: [[1, 2, 3], ...]
len_tokens = len(X_train[i])
print("to: ", X_train[i], "| len:", len(X_train[i]))## vocabulary: {"I":1, "like":2, "this":3, ...}
print("check: ", dtf_train["text_clean"].iloc[i].split()[0],
" -- idx in vocabulary -->",
dic_vocabulary[dtf_train["text_clean"].iloc[i].split()[0]])
print("vocabulary: ", dict(list(dic_vocabulary.items())[0:5]), "... (padding element, 0)")
Before moving on, don’t forget to do the same feature engineering on the test set as well:
在继续之前,请不要忘记对测试集进行相同的功能设计:
corpus = dtf_test["text_clean"]
## create list of n-grams
lst_corpus = []
for string in corpus:
lst_words = string.split()
lst_grams = [" ".join(lst_words[i:i+1]) for i in range(0,
len(lst_words), 1)]
lst_corpus.append(lst_grams)
## detect common bigrams and trigrams using the fitted detectors
lst_corpus = list(bigrams_detector[lst_corpus])
lst_corpus = list(trigrams_detector[lst_corpus])## text to sequence with the fitted tokenizer
lst_text2seq = tokenizer.texts_to_sequences(lst_corpus)## padding sequence
X_test = kprocessing.sequence.pad_sequences(lst_text2seq, maxlen=15,
padding="post", truncating="post")
We’ve got our X_train and X_test, now we need to create the matrix of embedding that will be used as a weight matrix in the neural network classifier.
我们已经有了X_train和X_test ,现在我们需要创建嵌入矩阵 ,将其用作神经网络分类器中的权重矩阵。
## start the matrix (length of vocabulary x vector size) with all 0s
embeddings = np.zeros((len(dic_vocabulary)+1, 300))for word,idx in dic_vocabulary.items():
## update the row with vector
try:
embeddings[idx] = nlp[word]
## if word not in model then skip and the row stays all 0s
except:
passThat code generates a matrix of shape 22,338 x 300 (Length of vocabulary extracted from the corpus x Vector size). It can be navigated by word id, which can be obtained from the vocabulary.
该代码生成形状为22,338 x 300(从语料库中提取的词汇长度x Vector大小)的矩阵。 可以通过单词id进行导航,可以从词汇表中获取。
word = "data"print("dic[word]:", dic_vocabulary[word], "|idx")
print("embeddings[idx]:", embeddings[dic_vocabulary[word]].shape,
"|vector")
It’s finally time to build a deep learning model. I’m going to use the embedding matrix in the first Embedding layer of the neural network that I will build and train to classify the news. Each id in the input sequence will be used as the index to access the embedding matrix. The output of this Embedding layer will be a 2D matrix with a word vector for each word id in the input sequence (Sequence length x Vector size). Let’s use the sentence “I like this article” as an example:
现在是时候建立深度学习模型了 。 我将在神经网络的第一嵌入层中使用嵌入矩阵,该层将被构建和训练以对新闻进行分类。 输入序列中的每个id将用作访问嵌入矩阵的索引。 此嵌入层的输出将是一个2D矩阵,其中包含输入序列中每个单词id的单词向量(序列长度x向量大小)。 让我们以“ 我喜欢这篇文章 ”为例:

My neural network shall be structured as follows:
我的神经网络的结构如下:
- an Embedding layer that takes the sequences as input and the word vectors as weights, just as described before. 如前所述,将序列作为输入,将词向量作为权重的嵌入层。
A simple Attention layer that won’t affect the predictions but it’s going to capture the weights of each instance and allow us to build a nice explainer (it isn't necessary for the predictions, just for the explainability, so you can skip it). The Attention mechanism was presented in this paper (2014) as a solution to the problem of the sequence models (i.e. LSTM) to understand what parts of a long text are actually relevant.
一个简单的Attention层,它不会影响预测,但是它将捕获每个实例的权重,并允许我们构建一个不错的解释器(预测并不需要,只是为了可解释性,因此可以跳过它) 。 本文 (2014年)提出了注意力机制,以解决序列模型(即LSTM)问题,以了解长文本的哪些部分实际上是相关的。
- Two layers of Bidirectional LSTM to model the order of words in a sequence in both directions. 两层双向LSTM,以双向模拟序列中单词的顺序。
- Two final dense layers that will predict the probability of each news category. 两个最终的密集层将预测每个新闻类别的概率。
## code attention layer
def attention_layer(inputs, neurons):
x = layers.Permute((2,1))(inputs)
x = layers.Dense(neurons, activation="softmax")(x)
x = layers.Permute((2,1), name="attention")(x)
x = layers.multiply([inputs, x])
return x
## input
x_in = layers.Input(shape=(15,))## embedding
x = layers.Embedding(input_dim=embeddings.shape[0],
output_dim=embeddings.shape[1],
weights=[embeddings],
input_length=15, trainable=False)(x_in)## apply attention
x = attention_layer(x, neurons=15)## 2 layers of bidirectional lstm
x = layers.Bidirectional(layers.LSTM(units=15, dropout=0.2,
return_sequences=True))(x)
x = layers.Bidirectional(layers.LSTM(units=15, dropout=0.2))(x)## final dense layers
x = layers.Dense(64, activation='relu')(x)
y_out = layers.Dense(3, activation='softmax')(x)## compile
model = models.Model(x_in, y_out)
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])
model.summary()
Now we can train the model and check the performance on a subset of the training set used for validation before testing it on the actual test set.
现在,我们可以训练模型并在用于验证的训练集的子集上检查性能,然后再在实际测试集上对其进行测试。
## encode y
dic_y_mapping = {n:label for n,label in
enumerate(np.unique(y_train))}
inverse_dic = {v:k for k,v in dic_y_mapping.items()}
y_train = np.array([inverse_dic[y] for y in y_train])## train
training = model.fit(x=X_train, y=y_train, batch_size=256,
epochs=10, shuffle=True, verbose=0,
validation_split=0.3)## plot loss and accuracy
metrics = [k for k in training.history.keys() if ("loss" not in k) and ("val" not in k)]
fig, ax = plt.subplots(nrows=1, ncols=2, sharey=True)ax[0].set(title="Training")
ax11 = ax[0].twinx()
ax[0].plot(training.history['loss'], color='black')
ax[0].set_xlabel('Epochs')
ax[0].set_ylabel('Loss', color='black')
for metric in metrics:
ax11.plot(training.history[metric], label=metric)
ax11.set_ylabel("Score", color='steelblue')
ax11.legend()ax[1].set(title="Validation")
ax22 = ax[1].twinx()
ax[1].plot(training.history['val_loss'], color='black')
ax[1].set_xlabel('Epochs')
ax[1].set_ylabel('Loss', color='black')
for metric in metrics:
ax22.plot(training.history['val_'+metric], label=metric)
ax22.set_ylabel("Score", color="steelblue")
plt.show()
Nice! In some epochs, the accuracy reached 0.89. In order to complete the evaluation of the Word Embedding model, let’s predict the test set and compare the same metrics used before (code for metrics is the same as before).
真好! 在某些时期,准确性达到0.89。 为了完成对Word Embedding模型的评估 ,让我们预测测试集并比较之前使用的相同度量(度量代码与之前相同)。
## test
predicted_prob = model.predict(X_test)
predicted = [dic_y_mapping[np.argmax(pred)] for pred in
predicted_prob]
The model performs as good as the previous one, in fact, it also struggles to classify Tech news.
该模型的性能与上一个模型相同,实际上,它也很难对Tech新闻进行分类。
But is it explainable as well? Yes, it is! I put an Attention layer in the neural network to extract the weights of each word and understand how much those contributed to classify an instance. So I’ll try to use Attention weights to build an explainer (similar to the one seen in the previous section):
但这也是可以解释的吗? 是的! 我在神经网络中放置了一个Attention层,以提取每个单词的权重,并了解这些单词对实例进行分类的贡献。 因此,我将尝试使用注意力权重来构建解释器(类似于上一节中看到的解释器):
## select observationi = 0
txt_instance = dtf_test["text"].iloc[i]## check true value and predicted value
print("True:", y_test[i], "--> Pred:", predicted[i], "| Prob:", round(np.max(predicted_prob[i]),2))
## show explanation
### 1. preprocess inputlst_corpus = []
for string in [re.sub(r'[^\w\s]','', txt_instance.lower().strip())]:
lst_words = string.split()
lst_grams = [" ".join(lst_words[i:i+1]) for i in range(0,
len(lst_words), 1)]
lst_corpus.append(lst_grams)
lst_corpus = list(bigrams_detector[lst_corpus])
lst_corpus = list(trigrams_detector[lst_corpus])
X_instance = kprocessing.sequence.pad_sequences(
tokenizer.texts_to_sequences(corpus), maxlen=15,
padding="post", truncating="post")### 2. get attention weights
layer = [layer for layer in model.layers if "attention" in
layer.name][0]
func = K.function([model.input], [layer.output])
weights = func(X_instance)[0]
weights = np.mean(weights, axis=2).flatten()### 3. rescale weights, remove null vector, map word-weight
weights = preprocessing.MinMaxScaler(feature_range=(0,1)).fit_transform(np.array(weights).reshape(-1,1)).reshape(-1)
weights = [weights[n] for n,idx in enumerate(X_instance[0]) if idx
!= 0]
dic_word_weigth = {word:weights[n] for n,word in
enumerate(lst_corpus[0]) if word in
tokenizer.word_index.keys()}### 4. barplot
if len(dic_word_weigth) > 0:
dtf = pd.DataFrame.from_dict(dic_word_weigth, orient='index',
columns=["score"])
dtf.sort_values(by="score",
ascending=True).tail(top).plot(kind="barh",
legend=False).grid(axis='x')
plt.show()
else:
print("--- No word recognized ---")### 5. produce html visualization
text = []
for word in lst_corpus[0]:
weight = dic_word_weigth.get(word)
if weight is not None:
text.append('<b><span style="background-color:rgba(100,149,237,' + str(weight) + ');">' + word + '</span></b>')
else:
text.append(word)
text = ' '.join(text)### 6. visualize on notebookprint("\033[1m"+"Text with highlighted words")
from IPython.core.display import display, HTML
display(HTML(text))

Just like before, the words “clinton” and “gop” activated the neurons of the model, but this time also “high” and “benghazi” have been considered slightly relevant for the prediction.
就像以前一样,“ 克林顿 ”和“ gop ”这两个词激活了模型的神经元,但这次,“ 高 ”和“本哈兹 ”也被认为与预测有点相关。
语言模型 (Language Models)
Language Models, or Contextualized/Dynamic Word Embeddings, overcome the biggest limitation of the classic Word Embedding approach: polysemy disambiguation, a word with different meanings (e.g. “ bank” or “stick”) is identified by just one vector. One of the first popular ones was ELMO (2018), which doesn’t apply a fixed embedding but, using a bidirectional LSTM, looks at the entire sentence and then assigns an embedding to each word.
语言模型 (即语境化/动态词嵌入)克服了经典词嵌入方法的最大局限:多义消除歧义,仅通过一个向量即可识别具有不同含义的词(例如“ bank ”或“ stick ”)。 ELMO(2018)是第一个流行的应用程序,它没有应用固定的嵌入,而是使用双向LSTM来查看整个句子,然后为每个单词分配一个嵌入。
Enter Transformers: a new modeling technique presented by Google’s paper Attention is All You Need (2017) in which it was demonstrated that sequence models (like LSTM) can be totally replaced by Attention mechanisms, even obtaining better performances.
输入变形金刚:Google论文提出的一种新的建模技术注意就是您所需要的 (2017) 事实证明,序列模型(如LSTM)可以完全被Attention机制取代,甚至可以获得更好的性能。
Google’s BERT (Bidirectional Encoder Representations from Transformers, 2018) combines ELMO context embedding and several Transformers, plus it’s bidirectional (which was a big novelty for Transformers). The vector BERT assigns to a word is a function of the entire sentence, therefore, a word can have different vectors based on the contexts. Let’s try it using transformers:
谷歌的BERT (来自Transformers的双向编码器表示,2018)结合了ELMO上下文嵌入和多个Transformers,以及它的双向功能(这对Transformers来说是一个很大的新颖性)。 BERT分配给单词的向量是整个句子的函数,因此,单词可以基于上下文具有不同的向量。 让我们使用Transformer尝试一下:
txt = "bank river"## bert tokenizer
tokenizer = transformers.BertTokenizer.from_pretrained('bert-base-uncased', do_lower_case=True)## bert model
nlp = transformers.TFBertModel.from_pretrained('bert-base-uncased')## return hidden layer with embeddings
input_ids = np.array(tokenizer.encode(txt))[None,:]
embedding = nlp(input_ids)embedding[0][0]
If we change the input text into “bank money”, we get this instead:
如果将输入文本更改为“ bank money ”,则会得到以下信息:

In order to complete a text classification task, you can use BERT in 3 different ways:
为了完成文本分类任务,您可以通过3种不同的方式使用BERT:
- train it all from scratches and use it as classifier. 从头开始训练所有内容并将其用作分类器。
- Extract the word embeddings and use them in an embedding layer (like I did with Word2Vec). 提取单词嵌入并在嵌入层中使用它们(就像我对Word2Vec所做的那样)。
- Fine-tuning the pre-trained model (transfer learning). 微调预训练模型(转移学习)。
I’m going with the latter and do transfer learning from a pre-trained lighter version of BERT, called Distil-BERT (66 million of parameters instead of 110 million!).
我将使用后者,并从经过预训练的较轻版本的BERT(称为Distil-BERT) (从6千万个参数代替1.1亿个参数!)中转移学习内容。
## distil-bert tokenizer
tokenizer = transformers.AutoTokenizer.from_pretrained('distilbert-base-uncased', do_lower_case=True)As usual, before fitting the model there is some Feature Engineering to do, but this time it’s gonna be a little trickier. To give an illustration of what I’m going to do, let’s take as an example our beloved sentence “I like this article”, which has to be transformed into 3 vectors (Ids, Mask, Segment):
像往常一样,在拟合模型之前,需要进行一些功能工程 ,但这一次会有些棘手。 为了说明我将要执行的操作,让我们以我们喜欢的句子“ 我喜欢这篇文章 ”为例,该句子必须转换为3个向量(Ids,Mask,Segment):

First of all, we need to select the sequence max length. This time I’m gonna choose a much larger number (i.e. 50) because BERT splits unknown words into sub-tokens until it finds a known unigrams. For example, if a made-up word like “zzdata” is given, BERT would split it into [“z”, “##z”, “##data”]. Moreover, we have to insert special tokens into the input text, then generate masks and segments. Finally, put all together in a tensor to get the feature matrix that will have the shape of 3 (ids, masks, segments) x Number of documents in the corpus x Sequence length.
首先,我们需要选择序列的最大长度。 这次我要选择一个更大的数字(即50),因为BERT将未知单词分解为子标记,直到找到已知的字母组合。 例如,如果给出了类似“ zzdata ”的虚构词,则BERT会将其拆分为[“ z ”,“ ## z ”,“ ## data ”]。 此外,我们必须在输入文本中插入特殊标记,然后生成掩码和句段。 最后,将所有元素放在张量中以得到特征矩阵,该特征矩阵的形状将为3(标识,蒙版,句段)x语料库中的文档数x序列长度。
Please note that I’m using the raw text as corpus (so far I’ve been using the clean_text column).
请注意,我使用原始文本作为语料库(到目前为止,我一直在使用clean_text列)。
corpus = dtf_train["text"]
maxlen = 50
## add special tokens
maxqnans = np.int((maxlen-20)/2)
corpus_tokenized = ["[CLS] "+
" ".join(tokenizer.tokenize(re.sub(r'[^\w\s]+|\n', '',
str(txt).lower().strip()))[:maxqnans])+
" [SEP] " for txt in corpus]## generate masks
masks = [[1]*len(txt.split(" ")) + [0]*(maxlen - len(
txt.split(" "))) for txt in corpus_tokenized]
## padding
txt2seq = [txt + " [PAD]"*(maxlen-len(txt.split(" "))) if len(txt.split(" ")) != maxlen else txt for txt in corpus_tokenized]
## generate idx
idx = [tokenizer.encode(seq.split(" ")) for seq in txt2seq]
## generate segments
segments = []
for seq in txt2seq:
temp, i = [], 0
for token in seq.split(" "):
temp.append(i)
if token == "[SEP]":
i += 1
segments.append(temp)## feature matrix
X_train = [np.asarray(idx, dtype='int32'),
np.asarray(masks, dtype='int32'),
np.asarray(segments, dtype='int32')]The feature matrix X_train has a shape of 3 x 34,265 x 50. We can check a random observation from the feature matrix:
特征矩阵X_train的形状为3 x 34265 x50。我们可以从特征矩阵检查随机观察结果:
i = 0print("txt: ", dtf_train["text"].iloc[0])
print("tokenized:", [tokenizer.convert_ids_to_tokens(idx) for idx in X_train[0][i].tolist()])
print("idx: ", X_train[0][i])
print("mask: ", X_train[1][i])
print("segment: ", X_train[2][i])
You can take the same code and apply it to dtf_test[“text”] to get X_test.
您可以采用相同的代码并将其应用于dtf_test [“ text”]以获取X_test 。
Now, I’m going to build the deep learning model with transfer learning from the pre-trained BERT. Basically, I’m going to summarize the output of BERT into one vector with Average Pooling and then add two final Dense layers to predict the probability of each news category.
现在,我将使用来自预训练的BERT的转移学习来构建深度学习模型 。 基本上,我将使用平均池将BERT的输出汇总为一个向量,然后添加两个最终的Dense层以预测每个新闻类别的概率。
If you want to use the original versions of BERT, here’s the code (remember to redo the feature engineering with the right tokenizer):
如果要使用BERT的原始版本,请使用以下代码(请记住,使用正确的令牌生成器重做功能工程):
## inputs
idx = layers.Input((50), dtype="int32", name="input_idx")
masks = layers.Input((50), dtype="int32", name="input_masks")
segments = layers.Input((50), dtype="int32", name="input_segments")## pre-trained bert
nlp = transformers.TFBertModel.from_pretrained("bert-base-uncased")
bert_out, _ = nlp([idx, masks, segments])## fine-tuning
x = layers.GlobalAveragePooling1D()(bert_out)
x = layers.Dense(64, activation="relu")(x)
y_out = layers.Dense(len(np.unique(y_train)),
activation='softmax')(x)## compile
model = models.Model([idx, masks, segments], y_out)for layer in model.layers[:4]:
layer.trainable = Falsemodel.compile(loss='sparse_categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])model.summary()
As I said, I’m going to use the lighter version instead, Distil-BERT:
正如我所说,我将使用较轻的版本Distil-BERT:
## inputs
idx = layers.Input((50), dtype="int32", name="input_idx")
masks = layers.Input((50), dtype="int32", name="input_masks")## pre-trained bert with config
config = transformers.DistilBertConfig(dropout=0.2,
attention_dropout=0.2)
config.output_hidden_states = Falsenlp = transformers.TFDistilBertModel.from_pretrained('distilbert-
base-uncased', config=config)
bert_out = nlp(idx, attention_mask=masks)[0]## fine-tuning
x = layers.GlobalAveragePooling1D()(bert_out)
x = layers.Dense(64, activation="relu")(x)
y_out = layers.Dense(len(np.unique(y_train)),
activation='softmax')(x)## compile
model = models.Model([idx, masks], y_out)for layer in model.layers[:3]:
layer.trainable = Falsemodel.compile(loss='sparse_categorical_crossentropy',
optimizer='adam', metrics=['accuracy'])model.summary()
Let’s train, test, evaluate this bad boy (code for evaluation is the same):
让我们训练,测试,评估这个坏男孩(评估代码相同):
## encode y
dic_y_mapping = {n:label for n,label in
enumerate(np.unique(y_train))}
inverse_dic = {v:k for k,v in dic_y_mapping.items()}
y_train = np.array([inverse_dic[y] for y in y_train])## train
training = model.fit(x=X_train, y=y_train, batch_size=64,
epochs=1, shuffle=True, verbose=1,
validation_split=0.3)## test
predicted_prob = model.predict(X_test)
predicted = [dic_y_mapping[np.argmax(pred)] for pred in
predicted_prob]

The performance of BERT is slightly better than the previous models, in fact, it can recognize more Tech news than the others.
BERT的性能比以前的型号稍好,实际上,它可以识别比其他型号更多的技术新闻。
结论 (Conclusion)
This article has been a tutorial to demonstrate how to apply different NLP models to a multiclass classification use case. I compared 3 popular approaches: Bag-of-Words with Tf-Idf, Word Embedding with Word2Vec, and Language model with BERT. I went through Feature Engineering & Selection, Model Design & Testing, Evaluation & Explainability, comparing the 3 models in each step (where possible).
本文已成为一个教程,以演示如何将不同的NLP模型应用于多类分类用例 。 我比较了3种流行的方法:使用Tf-Idf的单词袋,使用Word2Vec的单词嵌入和使用BERT的语言模型。 我经历了特征工程和选择,模型设计和测试,评估和解释性,比较了每个步骤中的3个模型(如果可能)。
Please note that I haven’t covered explainability for BERT as I’m still working on that, but I will update this article as soon as I can. If you have any useful resources about that, feel free to contact me.
请注意,我仍在研究BERT的可解释性,但是我将尽快更新本文。 如果您有任何有用的资源,请随时与我联系。
翻译自: https://towardsdatascience.com/text-classification-with-nlp-tf-idf-vs-word2vec-vs-bert-41ff868d1794
nlp word2vec















 1312
1312

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









