





Doesn’t matter what kind of intelligence you have — be it artificial or natural — after this detailed analysis no captcha will be an obstacle. At the end of the article, you can find the simplest and most effective workaround solution.
无论您拥有哪种智能-不管是人造的还是自然的-在进行了详细的分析之后,验证码都不会成为障碍。 在本文的结尾,您可以找到最简单,最有效的解决方法。
CAPTCHA is a completely automated public Turing test to tell computers and humans apart by automatically setting up specific tasks that are difficult for computers but simple for human. This technology has become the security standard used to prevent automatic voting, registration, spam, brute-force attacks on websites, etc.
CAPTCHA是一种完全自动化的公共Turing测试,通过自动设置计算机难以执行但对人类而言简单的特定任务来区分计算机和人类。 该技术已成为用于防止自动投票,注册,垃圾邮件,网站上的暴力攻击等的安全标准。
1.验证码的类别 (1. Categories of captcha)
Existing captchas are divided into three categories: text, graphic and audio/video. Below we will look at how various captchas are generated and what successes now are with their bypassing. Do not scold for the quality of images — we took them from scientific publications, to which we provide links =) A full list of publications taken for analysis is given at the end of the article.
现有的验证码分为三类:文本,图形和音频/视频。 下面我们将看看如何生成各种验证码,以及绕过这些验证码现在有什么成功。 不要为图像的质量而责骂-我们从科学出版物中获取了它们,并提供了链接=)本文末尾提供了用于分析的出版物的完整列表。
1.1。 文字验证码 (1.1. Text captcha)
Text captchas are the most commonly used, but due to their simple structure they are also the most vulnerable. This type of captcha usually requires recognition of a geometrically distorted sequence of letters and numbers.
文本验证码是最常用的,但是由于其结构简单,它们也是最易受攻击的。 这种类型的验证码通常需要识别字母和数字的几何变形序列。
To increase security, various protection mechanisms are used, which can be divided into anti-segmentation and anti-recognition. The first group of mechanisms is aimed at complicating the process of characters separation, while the second group — at recognizing the characters themselves. Fig. 1 shows examples of various approaches to captchas defence.
为了提高安全性,使用了各种保护机制,可以将其分为反分段和反识别。 第一组机制旨在使字符分离过程复杂化,而第二组机制旨在识别字符本身。 图1显示了各种验证码防御方法的示例。
Fig. 1: Captcha defence types
图1:验证码防御类型
1.1.1。 空心符号 (1.1.1. Hollow symbols)
In the captcha-creating strategy “hollow symbols”, contour lines are used to form each symbol.
在验证码创建策略“空心符号”中,轮廓线用于形成每个符号。

Fig. 2. Hollow captcha
图2.空心验证码
Such characters are difficult to segment, but they are easily visible to people. Unfortunately, this mechanism is not as secure as expected. In Gao’s research [1], the convolutional neural network successfully recognizes from 36% to 89% of images (depending on the type of distortion and the training sample).
这样的字符很难分割,但是人们很容易看到它们。 不幸的是,这种机制并不像预期的那样安全。 在高的研究中[1],卷积神经网络成功识别了36%至89%的图像(取决于失真的类型和训练样本)。
1.1.2。 一起打字符 (1.1.2. Crowing characters together)
Crowing characters together (CCT) complicate segmentation, but also reduce the readability for the user. That is, even human sometimes can not successfully solve such a captcha.
将字符放在一起(CCT)会使分段复杂化,但也会降低用户的可读性。 也就是说,即使人类有时也无法成功解决这种验证码。

Fig. 3. Overlap and CCT
图3.重叠和CCT
Researchers from China and Pakistan managed to crack the CCT with a probability of 27.1% to 53.2% [2].
来自中国和巴基斯坦的研究人员设法以27.1%至53.2%的概率破解了CCT [2]。
1.1.3。 背景噪音 (1.1.3. Background noises)

Fig. 4. Background noises
图4.背景噪声
Google’s reCAPTCHA, using images from Street View, breaks in 96% of cases [3].
Google的reCAPTCHA使用街景视图中的图像,在96%的案例中都中断了[3]。
1.1.4。 两级结构 (1.1.4. Two-level structure)
The two-level structure is a vertical combination of two horizontal captchas, which complicates the segmentation of the image.
二级结构是两个水平验证码的垂直组合,这使图像的分割变得复杂。

Fig. 5. Two-level structure
图5.两层结构
Gao [4] proposed a segmentation approach for separating captcha images both vertically and horizontally, and achieved 44.6% success (9 seconds per image) using a convolutional neural network.
Gao [4]提出了一种用于垂直和水平分离验证码图像的分割方法,并使用卷积神经网络获得了44.6%的成功率(每幅图像9秒)。
1.2。 基于图片的验证码 (1.2. Captcha based on image)
1.2.1。 基于选择的验证码 (1.2.1. Selection based captcha)
In the case of captcha based on selection, users must select the correct answers according to the prompt provided to this captcha. This is the simplest image based captcha form. For example, you need to highlight all the cars, all traffic signs or all traffic lights among the presented images.
对于基于选择的验证码,用户必须根据提供给该验证码的提示选择正确的答案。 这是最简单的基于图像的验证码形式。 例如,您需要突出显示所显示图像中的所有汽车,所有交通标志或所有交通灯。

Fig. 6. Various examples of image captchas, based on selection
图6.基于选择的图像验证码的各种示例
Gaulle [5] proposed using the support vector machine (SVM) to distinguish images of cats and dogs in Asirra captcha with a probability of successful recognition of 82.7%.
Gaulle [5]提出使用支持向量机(SVM)来区分猫科动物验证码中猫和狗的图像,成功识别的可能性为82.7%。
Gao’s team [6] used OpenCV to detect faces in FR-CAPTCHA. It was possible to obtain a detection probability from 8% to 42% with image processing in less than 14 seconds. FaceDCAPTCH was recognized with a probability of 48% on average in 6.2 seconds.
Gao的团队[6]使用OpenCV来检测FR-CAPTCHA中的人脸。 在不到14秒的时间内进行图像处理,有可能获得8%至42%的检测概率。 FaceDCAPTCH在6.2秒内的平均概率为48%。
Columbia University employees beat reCAPTCHA and Facebook CAPTCHA with a probability of 70.78% and 83.5%, respectively.
哥伦比亚大学的员工击败reCAPTCHA和Facebook CAPTCHA的概率分别为70.78%和83.5%。
1.2.2。 基于点击的验证码 (1.2.2. Click-based Captcha)
In 2008, Richard Chow with his colleagues [7] first proposed click-based captcha. It requires users to click on symbols that are on a complex background in accordance with the prompt, as it shown on Fig. 7.
2008年,Richard Chow和他的同事[7]首次提出了基于点击的验证码。 它要求用户根据提示单击复杂背景上的符号,如图7所示。
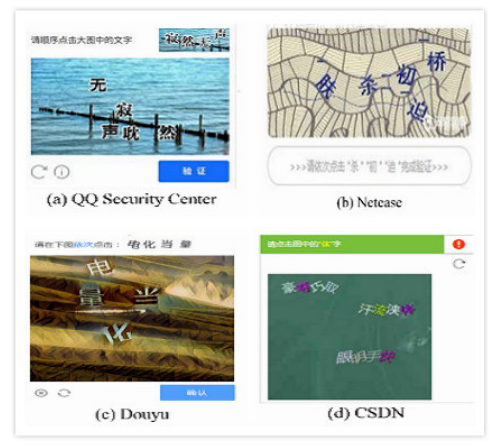
Fig. 7. Click-based captcha
图7.基于点击的验证码
Such click based captcha have two protective mechanisms: anti-detection and anti-recognition. Proper character recognition with the development of machine learning is no longer a difficult task. Therefore, almost all protection mechanisms are designed to prevent attackers from correctly identifying characters.
这样的基于点击的验证码具有两种保护机制:反检测和反识别。 随着机器学习的发展,正确的字符识别不再是一项艰巨的任务。 因此,几乎所有保护机制都旨在防止攻击者正确识别角色。
1.2.3。 拖放验证码 (1.2.3. Drag-and-Drop Captcha)
Dragging-based captcha determines whether the user is a person by analyzing the mouse trail, pointer movement speed, and response time.
基于拖动的验证码通过分析鼠标轨迹,指针移动速度和响应时间来确定用户是否为人。
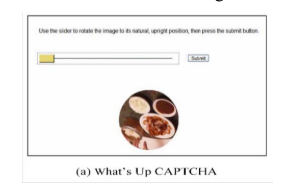
Fig. 8. Drag-and-Drop Captcha
图8.拖放验证码
Users need to rotate the image of the subject so that it will take it’s a natural position. For example, rotate the image of the table until it is on its legs. It is simple for humans, but difficult for bots.
用户需要旋转拍摄对象的图像,以使其处于自然位置。 例如,旋转桌子的图像,直到它靠在腿上。 它对人类来说很简单,但对机器人来说却很难。
1.3。 音频/视频验证码 (1.3. Audio/video captcha)
1.3.1音频验证码 (1.3.1 Audio captcha)
This captcha is usually considered as an alternative to visual captcha in the case of users with vision impairments. Listeners are invited to complete the task on the basis of what they heard, for example, to determine a specific sound, for example, the sound of a bell or piano [8].
对于有视力障碍的用户,通常认为此验证码可以替代视觉验证码。 邀请听众根据听到的声音完成任务,例如确定特定的声音,例如铃铛或钢琴的声音[8]。
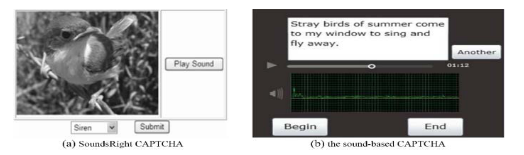
Fig. 9. Audio captcha
图9.音频验证码
There is another type of audio-based captcha in which users are required to not only listen, but to pronounce. For example, Gao [9] proposed a sound captcha (Fig. 9), in which the user should read out a sentence selected randomly from a book. The generated audio file is analyzed to determine if the user is human.
还有另一种基于音频的验证码,要求用户不仅要听,而且要发音。 例如,Gao [9]提出了一个声音验证码(图9),用户应该读出从书中随机选择的句子。 分析所生成的音频文件以确定用户是否为人类。
But audio captcha is cracked too: scientists from Stanford University have learned to crack audio captcha with a probability of 75%.
但是音频验证码也被破解了:斯坦福大学的科学家们学会了以75%的概率破解音频验证码。
1.3.2视频验证码 (1.3.2 Video-captcha)
In the video-captcha a video file is provided to users, and they must select a sentence that describes the movement of the person in the video.
在视频验证码中,视频文件提供给用户,他们必须选择一个描述视频中人物移动的句子。
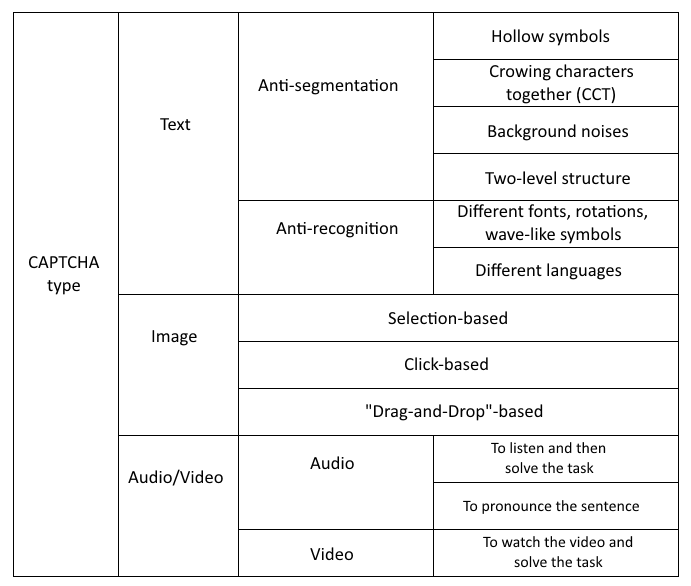
Fig. 10. Summary table. Types of captcha
图10.摘要表。 验证码的类型
Japanese researchers used a solution based on HMM (hidden Markov model) and obtained an accuracy of 31.75%.
日本研究人员使用了基于HMM(隐马尔可夫模型)的解决方案,其准确度为31.75%。
Let us now examine how exactly neural networks are used to crack captcha.
现在让我们检查一下神经网络是如何被用来破解验证码的。
2.具有DenseNet和DFCR架构的神经网络 (2. Neural networks with DenseNet and DFCR architectures)
In 2017, Gao Huang, Zhuang Liu and others [10] built 4 deep convolutional neural networks with an architecture now called DenseNet. Dense blocks of neural networks alternated with skip-connection layers (Fig. 10). The input of each layer in the block was the union of the output of all previous layers. This distinguished the new architecture from the traditional at that time neural networks, where the layers were connected in series.
2017年,黄高,刘壮等人[10]建立了4个深度卷积神经网络,其架构现在称为DenseNet。 神经网络的密集块与跳过连接层交替出现(图10)。 块中每一层的输入是所有先前层的输出的并集。 这使新体系结构与当时的传统神经网络(层之间是串联连接)区分开来。
Fig. 11. DenseNet with three dense blocks [11]
图11.具有三个密集块的DenseNet [11]

The DenseNet architecture has several advantages: it solves the dispersion problem and effectively uses the properties of all previous convolutional layers, reducing the computational complexity of network parameters and demonstrating good classification performance.
DenseNet体系结构具有几个优点:它解决了色散问题,有效地利用了所有以前卷积层的属性,降低了网络参数的计算复杂度,并展示了良好的分类性能。
An example of a variation of the DenseNet architecture is the DFCR neural network. The original captcha images of size 224x224 were passed through the convolution layer and then were combined into pools to output images of size 56x56. After that, 4 “dense” blocks were alternately connected, alternating with transition layers (Fig. 11). The structure of the transition layer made it possible to reduce the dimension of the feature map and speed up the calculations.
DFCR神经网络是DenseNet体系结构变体的一个示例。 尺寸为224x224的原始验证码图像通过卷积层,然后合并为多个池以输出尺寸为56x56的图像。 此后,交替连接4个“密集”块,与过渡层交替出现(图11)。 过渡层的结构可以减小特征图的尺寸并加快计算速度。
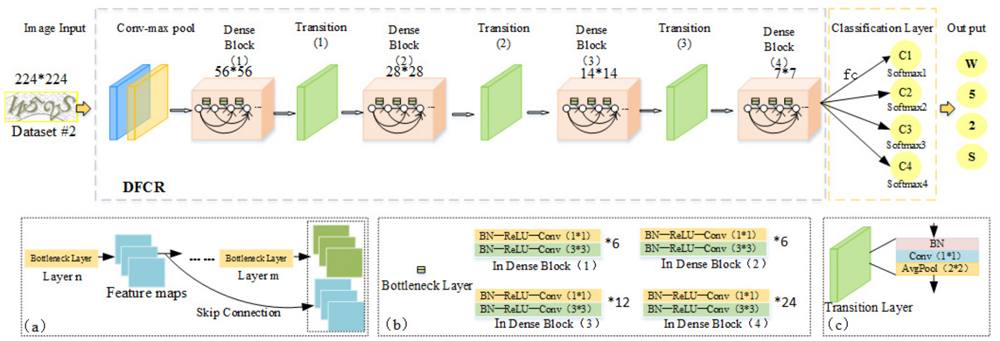
Fig. 12: DFCR architecture by the example of image recognition with the characters «W52S» [11]
图12:带有字符“ W52S”的图像识别示例的DFCR架构[11]
Further, the feature maps were used to check the correspondence of the map and class. The values in each feature map were summed to obtain the average value, which was taken as the class value and displayed in the corresponding softmax classification layer.
此外,特征图被用来检查地图和类别的对应关系。 将每个特征图中的值相加以获得平均值,将其作为类值并显示在相应的softmax分类层中。
Experiments show that DFCR not only preserves the main advantages of DenseNet, but also reduces memory consumption. In addition, the recognition accuracy of captcha with background noise and superimposed characters is higher than 99.9% [11].
实验表明,DFCR不仅保留了DenseNet的主要优点,而且还减少了内存消耗。 此外,带有背景噪声和重叠字符的验证码的识别精度高于99.9%[11]。
3.生成对抗网络 (3. Generative adversarial network)
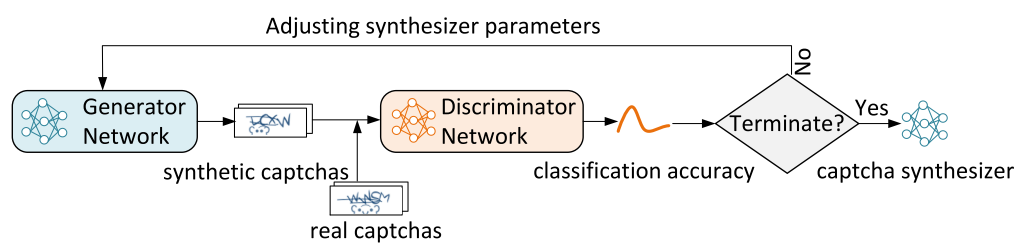
Fig. 13. The learning process of the text captcha generator on the GAN [12]
图13. GAN上的文本验证码生成器的学习过程[12]
A captcha generator on a GAN (generative adversarial network) consist of two parts: 1) a network that creates captchas close to the original; 2) a neural network that distinguishes artificial captcha from the real one (solver).
GAN(生成对抗网络)上的验证码生成器由两部分组成:1)一个网络,其创建的验证码与原始验证码接近。 2)区分人工验证码和真实验证码(求解器)的神经网络。
Before serving the captcha to the solver, the used protective means are removed, and the font is normalized. For example, the hollow characters are filled, and the spaces between them are normalized. The preprocessing model is based on Pix2Pix.
在向验证程序提供验证码之前,请先删除使用的保护工具,然后对字体进行标准化。 例如,空心字符被填充,并且它们之间的间隔被标准化。 预处理模型基于Pix2Pix 。

Fig. 14. The scheme of the algorithm. First, a small real captcha dataset is used to train the captcha synthesizer (1). Next, artificial captchas (2) are generated to train the solver (3). Improvement of the solver (4) [12]
图14.算法方案。 首先,使用一个小的真实验证码数据集来训练验证码合成器(1)。 接下来,生成人工验证码(2)以训练求解器(3)。 求解器的改进(4)[12]
Then a large number of captchas with marks are generated, which are used to train the solver. A trained solver accepts captcha after preprocessing and issues the corresponding characters. Fine tuning of the solver happens with the help of a small set of manually marked captchas that were collected from the target site.
然后会生成大量带有标记的验证码,用于训练求解器。 受过训练的求解器会在预处理后接受验证码,并发出相应的字符。 借助于从目标站点收集的一小组手动标记的验证码,可以对求解器进行微调。
As a specific convolutional neural network, the LeNet-5 architecture, which was originally used to recognize single characters, turned out to be a good option. Adding two convolutional layers and three pooling layers has expanded its capabilities to recognize several characters.
作为特定的卷积神经网络,最初用于识别单个字符的LeNet-5架构被证明是一个不错的选择。 添加两个卷积层和三个池化层已扩展了其识别几个字符的功能。
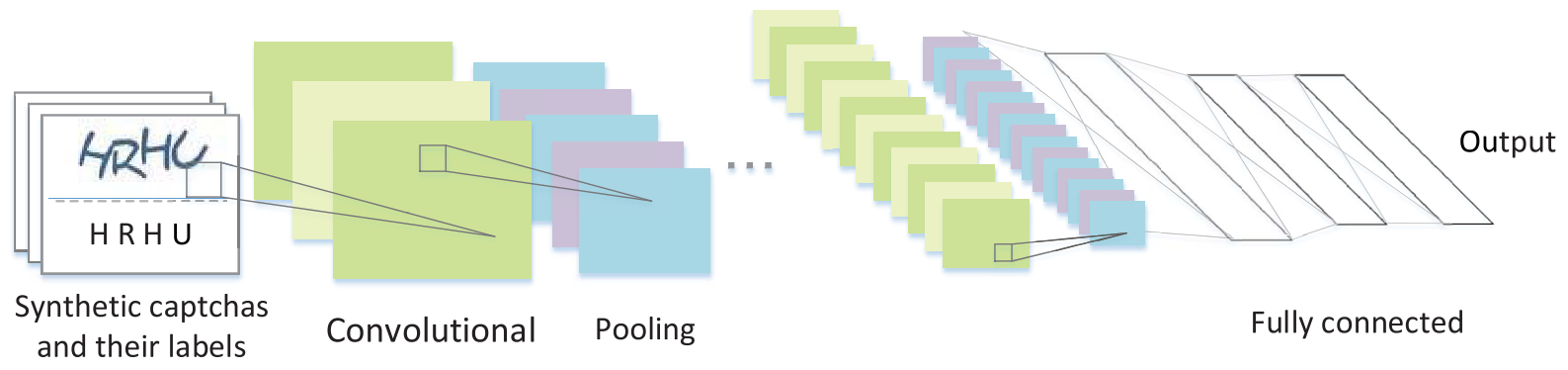
Fig. 15: Solver Training Algorithm [12]
图15:求解器训练算法[12]
Information obtained on the early layers of neural networks is useful for solving many other classification problems. The more distant layers are more specialized. This property is used to calibrate the solver to avoid systematic error or retraining.
在神经网络的早期层获得的信息对于解决许多其他分类问题很有用。 越远的层越专业。 此属性用于校准求解器,以避免系统误差或重新训练。
The output layer of the solver consists of a series of neurons with one neuron per symbol. For example, if there are n characters in the captcha, the output layer will contain n neurons, where each neuron corresponds to a possible symbol. If the number of characters is not fixed, then it is necessary to train the solver for every possible n.
求解器的输出层由一系列神经元组成,每个符号一个神经元。 例如,如果验证码中有n个字符,则输出层将包含n个神经元,其中每个神经元对应一个可能的符号。 如果字符数不固定,则有必要针对每个可能的n训练求解器。
Hacking probability results:
骇客概率结果:
CCT and Overlap (depending on complexity) — from 25.1% to 65%Rotation (15 °, 30 °, 45 °, 60 °) — 100%, 100%, 99.85%, 99.55%Distortion — 92.9%Wave Effect — 98.85%The combination of the above-mentioned — 46.30%
CCT和重叠(取决于复杂度)-从25.1%到65%旋转(15°,30°,45°,60°)-100%,100%,99.85%,99.55%失真-92.9%波浪效应-98.85%上述-46.30%的组合
4.卷积神经网络+长短期记忆(LSTM) (4. Convolutional neural network + long short-term memory (LSTM))
To recognize a sequence of characters without segmentation, you can use a model consisting of a convolutional neural network connected to a neural network with long short-term memory (LSTM) and an attention mechanism.
要识别没有分段的字符序列,可以使用一个模型,该模型由卷积神经网络连接到具有长短期记忆(LSTM)的神经网络,并且具有注意力机制。
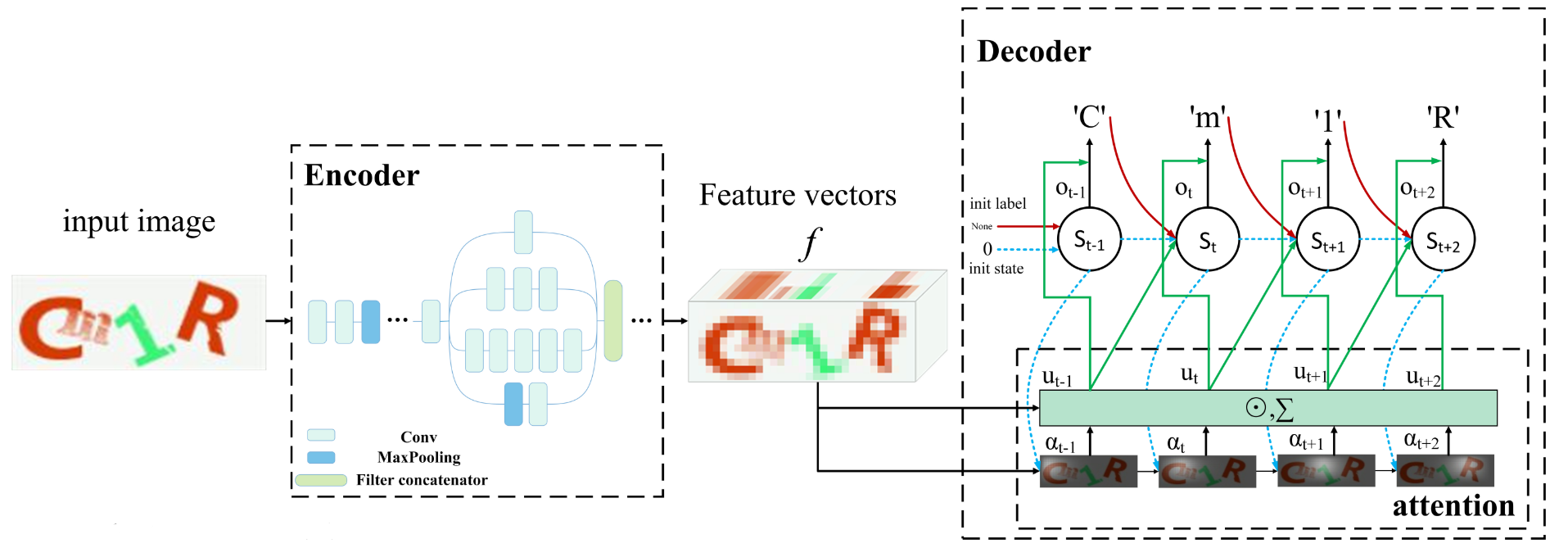
Fig. 16. Architecture Overview
图16.架构概述
The convolutional neural network is an encoder that extracts features from captcha. The original image is represented as a linear vector space. The feature vector created by the encoder is denoted by fijc, where i and j are the location indices on the feature map, c is the channel index.
卷积神经网络是一种从验证码中提取特征的编码器。 原始图像表示为线性向量空间。 编码器创建的特征向量用fijc表示,其中i和j是特征图上的位置索引,c是通道索引。
LSTM works as a decoder and translates the feature vector into a text sequence. Unlike a recurrent neural network, LSTM can store information over long periods of time.
LSTM用作解码器,并将特征向量转换为文本序列。 与递归神经网络不同,LSTM可以长时间存储信息。
In the traditional sequence-to-sequence model the vector f is transmitted to the input at each time step. But the bottleneck of the standard model is that the input is constant. The attention mechanism allows the decoder to ignore irrelevant information, while preserving the most significant information about the vector f. Different parts of the feature vector are assigned to different weights, so that the model at each step can focus on a specific part of the vector, making predictions more accurate. This is the main reason why the proposed method can recognize individual characters without segmentation.
在传统的序列到序列模型中,向量f在每个时间步长都传输到输入。 但是标准模型的瓶颈是输入是恒定的。 注意机制允许解码器忽略不相关的信息,同时保留有关向量f的最重要的信息。 将特征向量的不同部分分配给不同的权重,以便每个步骤的模型都可以专注于向量的特定部分,从而使预测更加准确。 这是提出的方法无需分割即可识别单个字符的主要原因。
In experiments, the abbreviated Inception-v3 model was used for decoding. The decoder consisted of LSTM cells, each of which contained 256 hidden neurons. The number of LSTM cells was equal to the maximum length of the captcha line. For the entire structure, the number of parameters available to be trained was 9 million. Depending on the initial size, each captcha was scaled so that the short side was in the range from 100 to 200 pixels. At the training stage, the model trained on stochastic gradient descent with a moment of 0.9. The training rate was 0.004. 200 eras with a batch size of 64 were spent on training.
在实验中,缩写的Inception-v3模型用于解码。 解码器由LSTM单元组成,每个单元包含256个隐藏的神经元。 LSTM单元的数量等于验证码行的最大长度。 对于整个结构,可训练的参数数量为900万。 根据初始大小,对每个验证码进行缩放,以使短边在100到200像素的范围内。 在训练阶段,模型以0.9的矩进行随机梯度下降训练。 培训率为0.004。 200个时代(批处理规模为64个)用于培训。

Fig. 17. CCT captcha
图17. CCT验证码
After each era, the model was tested. If the performance of the model was better than the current best model, the weights of the best model were updating. CCT captchas (text with overlapping) were collected as data for the experiment (Fig. 17).
在每个时代之后,都对模型进行了测试。 如果模型的性能优于当前的最佳模型,则最佳模型的权重正在更新。 收集CCT验证码(文本重叠)作为实验数据(图17)。
For a captcha sample in the test set, the complete predicted sequence of characters was considered correctly determined only if it was identical to the manually marked answer. For a set of 10,000 samples (training and test in a 3:1 ratio), the probability of successful recognition was 42.7%. With the number of samples increased to 50,000, 100,000, 150,000, and 200,000, the probability increased to 87.9%, 94.5%, 97.4%, and 98.3%, respectively.
对于测试集中的验证码样本,只有与人工标记的答案相同,才认为正确确定了完整的预测字符序列。 对于一组10,000个样本(以3:1的比例进行训练和测试),成功识别的概率为42.7%。 随着样本数量增加到50,000、100,000、150,000和200,000,概率分别增加到87.9%,94.5%,97.4%和98.3%。
5.强化学习 (5. Reinforcement learning)
Reinforcement learning was used to bypass Google reCAPTCHA v3 [14].
强化学习被用来绕过Google reCAPTCHA v3 [14]。
The bot’s interaction with the environment was modeled as a Markov decision process (MDP). MDP was defined by a tuple (S, A, P, r), where S is a finite set of states, A is a finite set of actions, P is the probability of a transition between states P (s, a, s’), r is the reward received after going to state s’ from state s with probability of P.
该机器人与环境的交互被建模为马尔可夫决策过程(MDP)。 MDP由元组(S,A,P,r)定义,其中S是状态的有限集合,A是动作的有限集合,P是状态P(s,a,s' ),r是从状态s进入状态s'后获得的奖励,概率为P.
The goal of the campaign was to find the optimal π * rule that maximizes expected rewards in the future. Suppose that a rule is parameterized by a set of weights w such that π = π (s, w). Then the task is set as
该活动的目标是找到最佳的π*规则,以使将来的预期奖励最大化。 假设规则由一组权重w参数化,使得π=π(s,w)。 然后将任务设置为
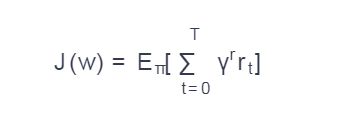
where γ is some constant (discount factor), rt is the reward at time t.
其中γ是某个常数(折现因子),rt是在时间t的回报。
Reinforced learning measures gradients by the formula
通过公式增强学习量度梯度
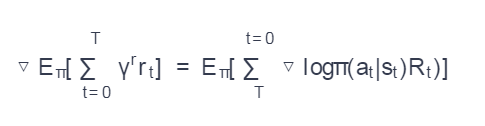
To go through reCAPTCHA, the user moves the cursor until the reCAPTCHA checkbox is selected. Depending on this interaction, the reCAPTCHA system will “reward” the user with a point. This process was modeled as MDP, where the state space S is the possible cursor position on the web page, and the action space A = {up, left, right, down}. This approach makes the task similar to a grid world task.
要浏览reCAPTCHA,用户移动光标直到选中reCAPTCHA复选框。 根据此交互,reCAPTCHA系统将为用户“奖励”一个点。 此过程建模为MDP,其中状态空间S是网页上可能的光标位置,而动作空间A = {上,左,右,下}。 这种方法使任务类似于网格世界任务。
As shown in Fig. 18, the starting point is the start position of the cursor, and the target is the position of reCAPTCHA. For each test, the starting point is randomly selected from the upper right or upper left area. Then a grid is built, where each pixel between the start and end points is a possible cursor position. Cell size c is the number of pixels between two consecutive positions. For example, if the cursor is at the position (x0, y0) and takes a move to the left, then the next position will be (x0 — c, y0).
如图18所示,起始点是光标的起始位置,目标是reCAPTCHA的位置。 对于每个测试,从右上或左上区域中随机选择起点。 然后构建一个网格,其中起点和终点之间的每个像素都是一个可能的光标位置。 像元大小c是两个连续位置之间的像素数。 例如,如果光标在(x0,y0)位置并向左移动,则下一个位置将是(x0-c,y0)。
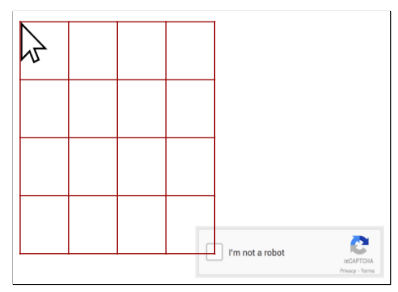
Fig. 18. The grid in the MDP [14]
图18. MDP中的网格[14]
In each test, the cursor position is random, the bot performs a sequence of actions until reCAPTCHA or the limit T is reached, where a and b are the height and width of the grid, respectively.
在每个测试中,光标位置都是随机的,机器人执行一系列操作,直到达到reCAPTCHA或极限T,其中a和b分别是网格的高度和宽度。
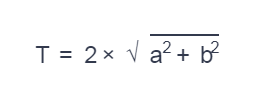
At the end of the test, the bot receives feedback from reCAPTCHA, like any ordinary user.
在测试结束时,机器人会像任何普通用户一样从reCAPTCHA接收反馈。
In most of the previous works, Selenium was used to automate the actions of the web browser, however, it often failed the test, since the HTTP requests detected an automatically generated header and other additional variables that were missing in a regular browser.
在大多数以前的工作中,Selenium用于自动化Web浏览器的操作,但是,由于HTTP请求检测到自动生成的标头和常规浏览器中缺少的其他附加变量,因此Selenium经常无法通过测试。
This problem can be solved in two different ways. The first is to create a proxy to remove the automatic header. The second option is to launch the browser from the command line and control the mouse using special Python packages, such as the PyAutoGUI library.
这个问题可以用两种不同的方式解决。 第一种是创建代理以删除自动标头。 第二个选项是从命令行启动浏览器,并使用特殊的Python包(例如PyAutoGUI库)控制鼠标。
It’s funny that simulations running in a browser with logged in Google account were passing validation more often than simulations without authorization.
有趣的是,在具有登录Google帐户的浏览器中运行的模拟比未经授权的模拟通过验证的频率更高。
In experiments with a discount factor of γ = 0.99, a learning speed of 10^-3 and a batch size of 2000 CAPTCHA was cracked with a probability of 97.4%.
在贴现因子为γ= 0.99的实验中,学习速度为10 ^ -3,批处理大小为2000 CAPTCHA,被破解的概率为97.4%。
6.人为验证码 (6. CAPTCHA-solving by humans)
As you can already see from this article, machine learning has a high entry threshold, and after all, everything that was described in the article is just the tip of the iceberg. If you dig deeper, then soon you can claim the title of junior on neural networks =)
从本文已经可以看到,机器学习具有很高的入门门槛,毕竟,本文中描述的所有内容只是冰山一角。 如果您深入研究,很快就可以在神经网络上获得初级的称号=)
But for actual work you need a team of specialists and a rental of computing power. Add to this the time for training/retraining of networks, a growing number of captcha types, a variety of languages — and it will turn out that it’s faster and cheaper to use online services where it’s people solve captchas.
但是对于实际工作,您需要一个专家团队和租赁计算能力。 加上网络培训/再培训的时间,越来越多的验证码类型,多种语言,事实证明,在人们解决验证码的地方使用在线服务会更快,更便宜。
Among similar services, 2captcha stands out. The service has a fine-tuning of the solver: the number of words, case, numbers and/or letters, language (55 to choose from), mathematical operations, etc.
在类似的服务中, 2captcha脱颖而出。 该服务对求解器进行了微调:单词,大小写,数字和/或字母,语言(从55种中选择),数学运算等的数量。
The following types of captcha can be solved: plain text, ReCaptcha versions 2 and 3, GeeTest, hCaptcha, ClickCaptcha, RotateCaptcha, FunCaptcha, KeyCaptcha.
可以解决以下类型的验证码:纯文本,ReCaptcha版本2和3,GeeTest,hCaptcha,ClickCaptcha,RotateCaptcha,FunCaptcha,KeyCaptcha。
Interaction with the server occurs through the API, that is, you can embed the solution in your own product. There is a refund function for rare incorrect answers, also technical support actually does answer the questions (and really adequate in comparison with competitors).
通过API与服务器进行交互,也就是说,您可以将解决方案嵌入自己的产品中。 具有退款功能,可用于罕见的错误答案,技术支持实际上可以回答问题(与竞争对手相比确实足够)。
Of course, for solving captchas the service pays to specific people who are ready to solve tasks for a small fee. Accordingly, the service takes this money from customers who do not have to deal with routine anymore. The prices at the time of writing were as follows: 1000 captchas were hacked for no more than $0.75 (on average 7.5 seconds per captcha), 1000 ReCaptchas — for $2.99 (average 32 seconds per captcha). That is, one fixed price regardless of the load and how much other customers paid.
当然,为解决验证码问题,服务将支付给准备解决任务的特定人员,费用不高。 因此,该服务从不再需要处理常规事务的客户那里收取这笔钱。 撰写本文时的价格如下:窃取1000个验证码的费用不超过0.75美元(每个验证码平均7.5秒),购买1000个ReCaptchas的价格为2.99美元(平均每个验证码32秒)。 也就是说,一个固定的价格与负载和其他客户的支付量无关。
Just for comparison: one middle specialist in machine learning will cost at least $2,000/month on the today’s market.
只是为了比较:在当今市场上,机器学习的一名中级专家每月的费用至少为2,000美元。
Leave a comment if you used the service — it is interesting to know your opinion (so far we are based on the opinions of the authors of the following articles: in English and three in Russian: one, two, three).
发表评论,如果你使用的服务-这是有趣的知道你的意见(到目前为止,我们是基于以下文章的作者的观点: 在英语中 ,三个在俄罗斯: 一个 , 2 , 3 )。














 975
975











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









