





This is an updated version of a very popular blog post, originally published in August 2012.
这是一个非常受欢迎的 博客文章 的更新版本,该 博客文章 最初于2012年8月发布。
介绍 (Introduction)
Enterprise software solutions often combine multiple technology platforms. Accessing an Oracle database via a Microsoft .NET application and vice-versa, accessing Microsoft SQL Server from a Java-based application is common. In this post, we will explore the use of the JDBC (Java Database Connectivity) API to call stored procedures from a Microsoft SQL Server 2017 database and return data to a Java 11-based console application.
企业软件解决方案通常结合多种技术平台。 通过Microsoft .NET应用程序访问Oracle数据库,反之亦然,从基于Java的应用程序访问Microsoft SQL Server是很常见的。 在本文中,我们将探索JDBC (Java数据库连接)API的使用,以从Microsoft SQL Server 2017数据库中调用存储过程并将数据返回到基于Java 11的控制台应用程序。
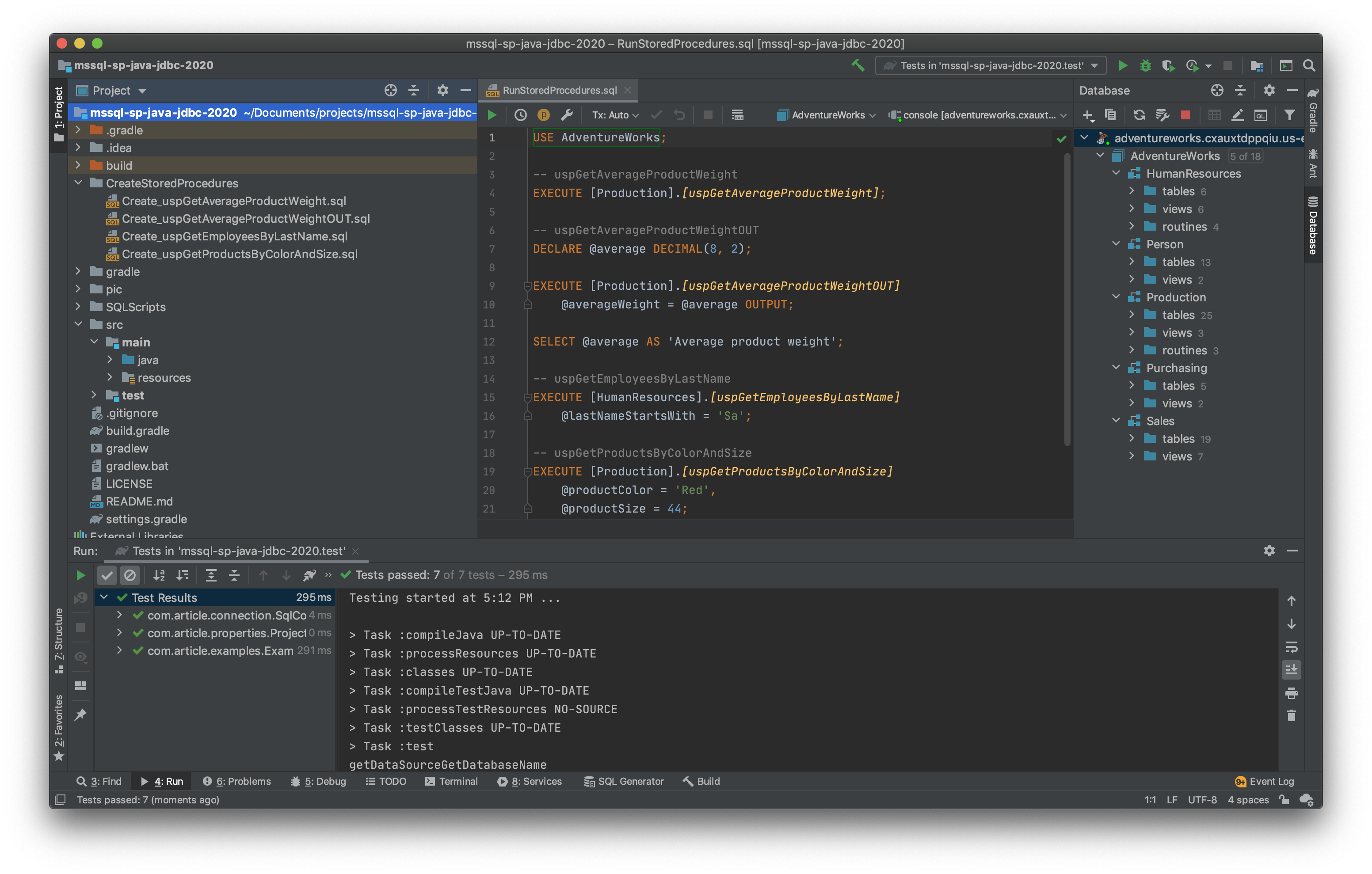
The objectives of this post include:
这篇文章的目标包括:
- Demonstrate the differences between using static SQL statements and stored procedures to return data. 演示使用静态SQL语句和存储过程返回数据之间的区别。
Demonstrate three types of JDBC statements to return data:
Statement,PreparedStatement, andCallableStatement.演示三种返回数据的JDBC语句:
Statement,PreparedStatement和CallableStatement。- Demonstrate how to call stored procedures with input and output parameters. 演示如何使用输入和输出参数调用存储过程。
- Demonstrate how to return single values and a result set from a database using stored procedures. 演示如何使用存储过程从数据库返回单个值和结果集。
为什么要存储过程? (Why Stored Procedures?)
To access data, many enterprise software organizations require their developers to call stored procedures within their code as opposed to executing static T-SQL (Transact-SQL) statements against the database. There are several reasons stored procedures are preferred:
为了访问数据,许多企业软件组织要求开发人员在代码中调用存储过程,而不是对数据库执行静态T-SQL (Transact-SQL)语句。 首选存储过程有以下几个原因:
- Optimization: Stored procedures are often written by database administrators (DBAs) or database developers who specialize in database development. They understand the best way to construct queries for optimal performance and minimal load on the database server. Think of it as a developer using an API to interact with the database. 优化:存储过程通常由数据库管理员(DBA)或专门从事数据库开发的数据库开发人员编写。 他们了解构造查询的最佳方法,以实现最佳性能并最小化数据库服务器上的负载。 可以将其视为使用API与数据库进行交互的开发人员。
- Safety and Security: Stored procedures are considered safer and more secure than static SQL statements. The stored procedure provides tight control over the content of the queries, preventing malicious or unintentionally destructive code from being executed against the database. 安全性:存储过程被认为比静态SQL语句更安全,更安全。 该存储过程提供了对查询内容的严格控制,从而防止对数据库执行恶意或无意破坏性的代码。
- Error Handling: Stored procedures can contain logic for handling errors before they bubble up to the application layer and possibly to the end-user. 错误处理:存储过程可以包含用于在错误蔓延到应用程序层和最终用户之前处理错误的逻辑。
AdventureWorks 2017数据库 (AdventureWorks 2017 Database)
For brevity, I will use an existing and well-known Microsoft SQL Server database, AdventureWorks. The AdventureWorks database was originally published by Microsoft for SQL Server 2008. Although a bit dated architecturally, the database comes prepopulated with plenty of data for demonstration purposes.
为简便起见,我将使用一个现有的知名Microsoft SQL Server数据库AdventureWorks 。 AdventureWorks数据库最初由Microsoft发布,用于SQL Server2008。尽管在体系结构上有些过时,但该数据库预先填充了大量数据,用于演示。
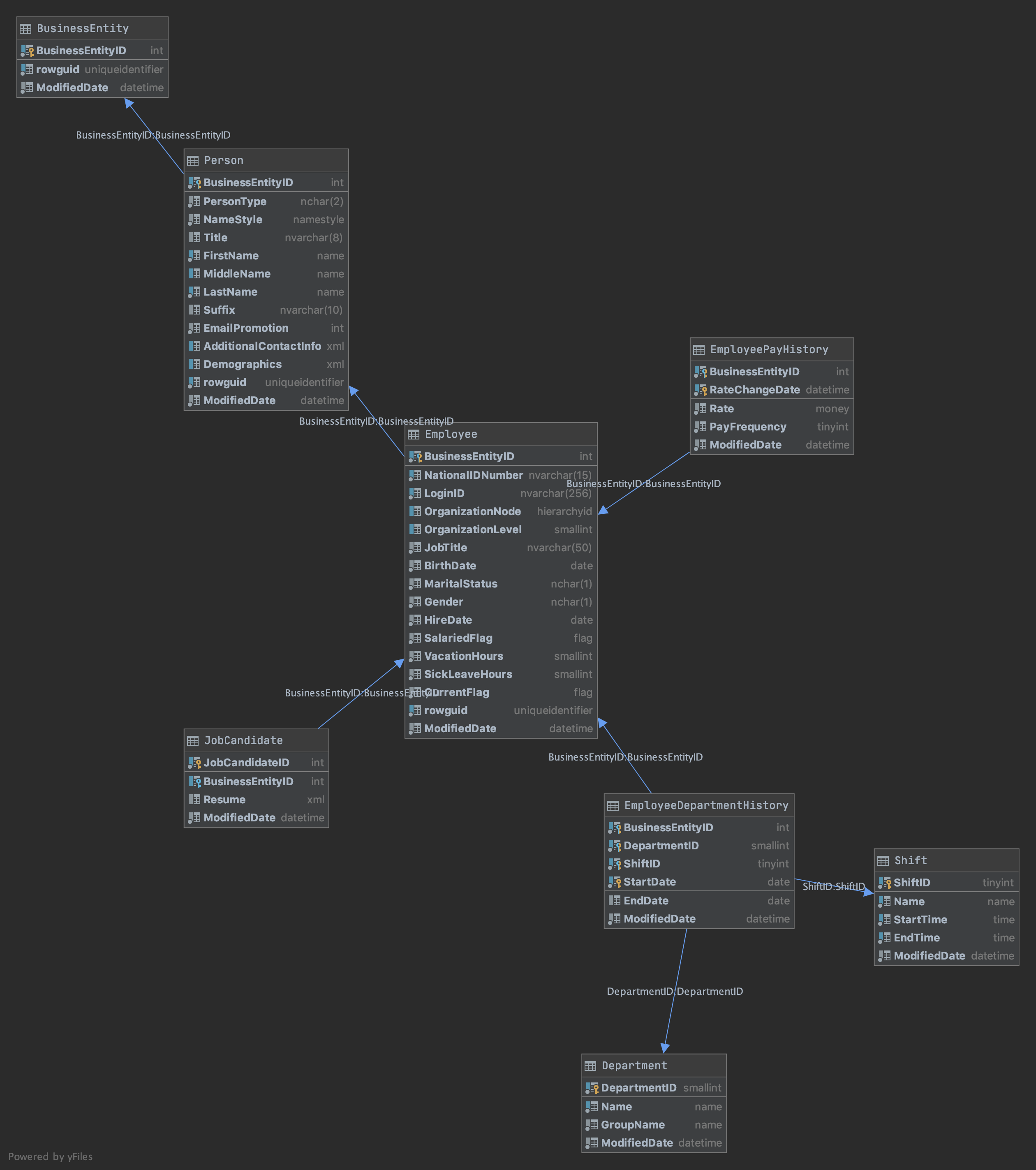
HumanResources schema, one of five schemas within the AdventureWorks database
HumanResources模式,AdventureWorks数据库中的五个模式之一
For the demonstration, I have created an Amazon RDS for SQL Server 2017 Express Edition instance on AWS. You have several options for deploying SQL Server, including AWS, Microsoft Azure, Google Cloud, or installed on your local workstation.
为了演示,我在AWS上创建了一个用于SQL Server 2017 Express Edition的Amazon RDS实例。 您可以使用多种选项来部署SQL Server,包括AWS , Microsoft Azure , Google Cloud或安装在本地工作站上。
There are many methods to deploy the AdventureWorks database to Microsoft SQL Server. For this post’s demonstration, I used the AdventureWorks2017.bak backup file, which I copied to Amazon S3. I then enabled and configured the native backup and restore feature of Amazon RDS for SQL Server to import and install the backup.
有很多方法可以将AdventureWorks数据库部署到Microsoft SQL Server。 在本博文的演示中,我使用了AdventureWorks2017.bak 备份文件 ,该文件已复制到Amazon S3。 然后,我为SQL Server 启用并配置了Amazon RDS的本机备份和还原功能,以导入和安装备份。
DROP DATABASE IF EXISTS AdventureWorks;
GO
EXECUTE msdb.dbo.rds_restore_database
@restore_db_name='AdventureWorks',
@s3_arn_to_restore_from='arn:aws:s3:::my-bucket/AdventureWorks2017.bak',
@type='FULL',
@with_norecovery=0;
-- get task_id from output (e.g. 1)
EXECUTE msdb.dbo.rds_task_status
@db_name='AdventureWorks',
@task_id=1;安装存储过程 (Install Stored Procedures)
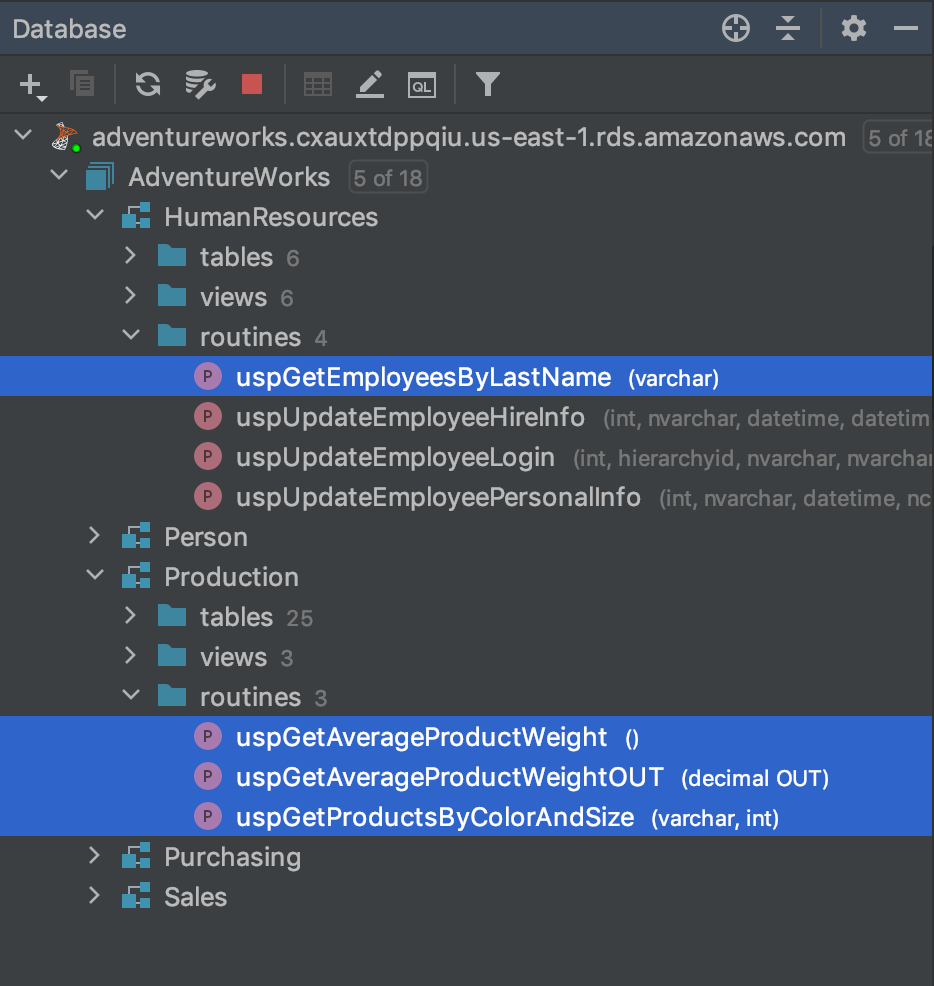
For the demonstration, I have added four stored procedures to the AdventureWorks database to use in this post. To follow along, you will need to install these stored procedures, which are included in the GitHub project.
为了演示,我在AdventureWorks数据库中添加了四个存储过程供本文使用。 为了继续进行,您将需要安装这些存储过程,这些存储过程包含在GitHub project中 。
数据源,连接和属性 (Data Sources, Connections, and Properties)
Using the latest Microsoft JDBC Driver 8.4 for SQL Server (version 8.4.1.jre11), we create a SQL Server data source, com.microsoft.sqlserver.jdbc.SQLServerDataSource, and database connection, java.sql.Connection. There are several patterns for creating and working with JDBC data sources and connections. This post does not necessarily focus on the best practices for creating or using either. In this example, the application instantiates a connection class, SqlConnection.java, which in turn instantiates the java.sql.Connection and com.microsoft.sqlserver.jdbc.SQLServerDataSource objects. The data source’s properties are supplied from an instance of a singleton class, ProjectProperties.java. This class instantiates the java.util.Properties class, which reads values from a configuration properties file, config.properties. On startup, the application creates the database connection, calls each of the example methods, and then closes the connection.
使用用于SQL Server的最新Microsoft JDBC驱动程序8.4 (版本8.4.1.jre11),我们创建一个SQL Server数据源com.microsoft.sqlserver.jdbc.SQLServerDataSource和数据库连接java.sql.Connection 。 有几种模式可用于创建和使用JDBC数据源和连接。 这篇文章不一定专注于创建或使用最佳实践。 在此示例中,应用程序实例化了一个连接类SqlConnection.java ,而该类又实例化了java.sql.Connection和com.microsoft.sqlserver.jdbc.SQLServerDataSource对象。 数据源的属性从单例类ProjectProperties.java的实例提供。 此类实例化java.util.Properties类,该类从配置属性文件config.properties读取值。 在启动时,应用程序创建数据库连接,调用每个示例方法,然后关闭该连接。
例子 (Examples)
For each example, I will show the stored procedure, if applicable, followed by the Java method that calls the procedure or executes the static SQL statement. For brevity, I have left out the data source and connection code in the article. Again, a complete copy of all the code for this article is available on GitHub, including Java source code, SQL statements, helper SQL scripts, and a set of basic JUnit tests.
对于每个示例,我将显示存储过程(如果适用),然后显示调用该过程或执行静态SQL语句的Java方法。 为简便起见,我在本文中省略了数据源和连接代码。 同样,可以在GitHub上获得本文所有代码的完整副本,包括Java源代码,SQL语句,辅助SQL脚本和一组基本的JUnit测试。
To run the JUnit unit tests, using Gradle, which the project is based on, use the ./gradlew cleanTest test --warning-mode none command.
要使用项目所基于的Gradle运行JUnit单元测试,请使用./gradlew cleanTest test --warning-mode none命令。
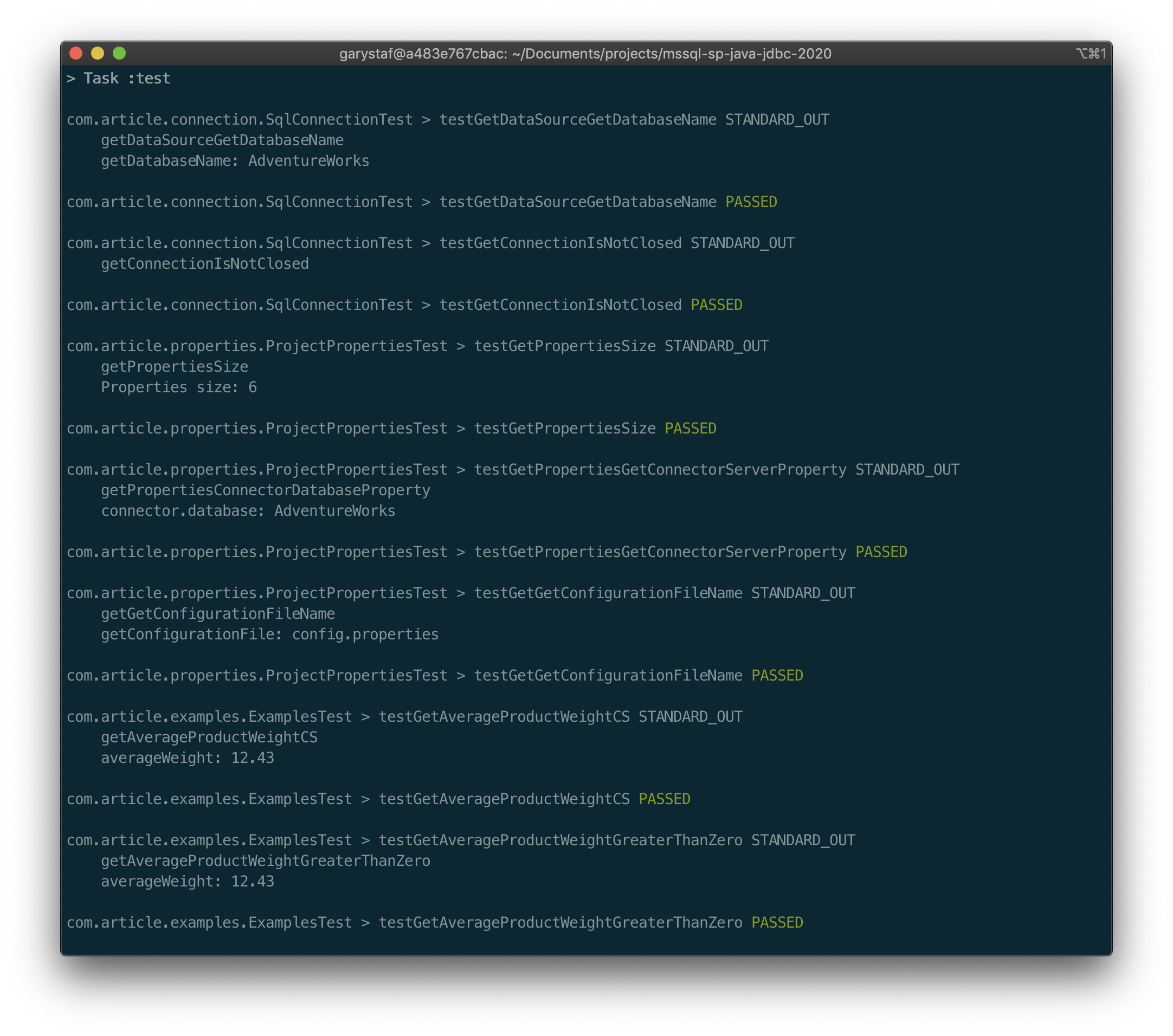
To build and run the application, using Gradle, which the project is based on, use the ./gradlew run --warning-mode none command.
要使用项目所基于的Gradle构建和运行应用程序,请使用./gradlew run --warning-mode none命令。
示例1:SQL语句 (Example 1: SQL Statement)
Before jumping into stored procedures, we will start with a simple static SQL statement. This example’s method, getAverageProductWeightST, uses the java.sql.Statement class. According to Oracle’s JDBC documentation, the Statement object is used for executing a static SQL statement and returning the results it produces. This SQL statement calculates the average weight of all products in the AdventureWorks database. It returns a solitary double numeric value. This example demonstrates one of the simplest methods for returning data from SQL Server.
在进入存储过程之前,我们将从一个简单的静态SQL语句开始。 此示例的方法getAverageProductWeightST使用java.sql.Statement类。 根据Oracle的JDBC文档 , Statement对象用于执行静态SQL语句并返回其产生的结果。 该SQL语句计算AdventureWorks数据库中所有产品的平均重量。 它返回一个孤立的double数值。 本示例演示了从SQL Server返回数据的最简单方法之一。
/**
* Statement example, no parameters, returns Integer
*
* @return Average weight of all products
*/public double getAverageProductWeightST() {
double averageWeight = 0;
Statement stmt = null;
ResultSet rs = null;try {
stmt = connection.getConnection().createStatement();
String sql = "WITH Weights_CTE(AverageWeight) AS" +
"(" +
" SELECT [Weight] AS [AverageWeight]" +
" FROM [Production].[Product]" +
" WHERE [Weight] > 0" +
" AND [WeightUnitMeasureCode] = 'LB'" +
" UNION" +
" SELECT [Weight] * 0.00220462262185 AS [AverageWeight]" +
" FROM [Production].[Product]" +
" WHERE [Weight] > 0" +
" AND [WeightUnitMeasureCode] = 'G')" +
"SELECT ROUND(AVG([AverageWeight]), 2)" +
"FROM [Weights_CTE];";
rs = stmt.executeQuery(sql);
if (rs.next()) {
averageWeight = rs.getDouble(1);
}
} catch (Exception ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.SEVERE, null, ex);
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.WARNING, null, ex);
}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.WARNING, null, ex);
}
}
}
return averageWeight;
}示例2:准备好的语句 (Example 2: Prepared Statement)
Next, we will execute almost the same static SQL statement as in Example 1. The only change is the addition of the column name, averageWeight. This allows us to parse the results by column name, making the code easier to understand as opposed to using the numeric index of the column as in Example 1.
接下来,我们将执行与示例1几乎相同的静态SQL语句。唯一的变化是增加了列名averageWeight 。 这使我们能够按列名解析结果,从而使代码更易于理解,与示例1中使用列的数字索引相反。
Also, instead of using the java.sql.Statement class, we use the java.sql.PreparedStatement class. According to Oracle’s documentation, a SQL statement is precompiled and stored in a PreparedStatement object. This object can then be used to execute this statement multiple times efficiently.
此外,而不是使用java.sql.Statement类,我们使用java.sql.PreparedStatement类。 根据Oracle的文档 ,SQL语句已预编译并存储在PreparedStatement对象中。 然后可以使用该对象有效地多次执行此语句。
/**
* PreparedStatement example, no parameters, returns Integer
*
* @return Average weight of all products
*/public double getAverageProductWeightPS() {
double averageWeight = 0;
PreparedStatement pstmt = null;
ResultSet rs = null;try {
String sql = "WITH Weights_CTE(averageWeight) AS" +
"(" +
" SELECT [Weight] AS [AverageWeight]" +
" FROM [Production].[Product]" +
" WHERE [Weight] > 0" +
" AND [WeightUnitMeasureCode] = 'LB'" +
" UNION" +
" SELECT [Weight] * 0.00220462262185 AS [AverageWeight]" +
" FROM [Production].[Product]" +
" WHERE [Weight] > 0" +
" AND [WeightUnitMeasureCode] = 'G')" +
"SELECT ROUND(AVG([AverageWeight]), 2) AS [averageWeight]" +
"FROM [Weights_CTE];";
pstmt = connection.getConnection().prepareStatement(sql);
rs = pstmt.executeQuery();
if (rs.next()) {
averageWeight = rs.getDouble("averageWeight");
}
} catch (Exception ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.SEVERE, null, ex);
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.WARNING, null, ex);
}
}
if (pstmt != null) {
try {
pstmt.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.WARNING, null, ex);
}
}
}
return averageWeight;
}示例3:可调用语句 (Example 3: Callable Statement)
In this example, the average product weight query has been moved into a stored procedure. The procedure is identical in functionality to the static statement in the first two examples. To call the stored procedure, we use the java.sql.CallableStatement class. According to Oracle’s documentation, the CallableStatement extends PreparedStatement. It is the interface used to execute SQL stored procedures. The CallableStatement accepts both input and output parameters; however, this simple example does not use either. Like the previous two examples, the procedure returns a double numeric value.
在此示例中,平均产品重量查询已移动到存储过程中。 该过程的功能与前两个示例中的static语句相同。 要调用存储过程,我们使用java.sql.CallableStatement类。 根据Oracle的文档 , CallableStatement扩展了PreparedStatement 。 它是用于执行SQL存储过程的接口。 CallableStatement接受输入和输出参数。 但是,此简单示例也不使用任何一个。 像前两个示例一样,该过程返回一个double精度数值。
CREATE OR
ALTER PROCEDURE [Production].[uspGetAverageProductWeight]
AS
BEGIN
SET NOCOUNT ON;WITH
Weights_CTE(AverageWeight)
AS
(
SELECT [Weight] AS [AverageWeight]
FROM [Production].[Product]
WHERE [Weight] > 0
AND [WeightUnitMeasureCode] = 'LB'
UNION
SELECT [Weight] * 0.00220462262185 AS [AverageWeight]
FROM [Production].[Product]
WHERE [Weight] > 0
AND [WeightUnitMeasureCode] = 'G'
)
SELECT ROUND(AVG([AverageWeight]), 2)
FROM [Weights_CTE];
ENDGOThe calling Java method is shown below.
调用Java方法如下所示。
/**
* CallableStatement, no parameters, returns Integer
*
* @return Average weight of all products
*/public double getAverageProductWeightCS() {
CallableStatement cstmt = null;
double averageWeight = 0;
ResultSet rs = null;
try {
cstmt = connection.getConnection().prepareCall(
"{call [Production].[uspGetAverageProductWeight]}");
cstmt.execute();
rs = cstmt.getResultSet();
if (rs.next()) {
averageWeight = rs.getDouble(1);
}
} catch (Exception ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.SEVERE, null, ex);
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.SEVERE, null, ex);
}
}
if (cstmt != null) {
try {
cstmt.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.WARNING, null, ex);
}
}
}
return averageWeight;
}示例4:使用输出参数调用存储过程 (Example 4: Calling a Stored Procedure with an Output Parameter)
In this example, we use almost the same stored procedure as in Example 3. The only difference is the inclusion of an output parameter. This time, instead of returning a result set with a value in a single unnamed column, the column has a name, averageWeight. We can now call that column by name when retrieving the value.
在此示例中,我们使用与示例3几乎相同的存储过程。唯一的区别是包含了输出参数。 这次,该列的名称为averageWeight ,而不是在单个未命名列中返回带有值的结果集。 现在,我们可以在检索值时按名称调用该列。
The stored procedure patterns found in Examples 3 and 4 are both commonly used. One procedure uses an output parameter, and one not, both return the same values. You can use the CallableStatement to for either type.
在示例3和示例4中找到的存储过程模式都是常用的。 一种过程使用输出参数,而另一种则不返回相同的值。 您可以将CallableStatement用于这两种类型。
CREATE OR
ALTER PROCEDURE [Production].[uspGetAverageProductWeightOUT] @averageWeight DECIMAL(8, 2) OUTAS
BEGIN
SET NOCOUNT ON;WITH
Weights_CTE(AverageWeight)
AS
(
SELECT [Weight] AS [AverageWeight]
FROM [Production].[Product]
WHERE [Weight] > 0
AND [WeightUnitMeasureCode] = 'LB'
UNION
SELECT [Weight] * 0.00220462262185 AS [AverageWeight]
FROM [Production].[Product]
WHERE [Weight] > 0
AND [WeightUnitMeasureCode] = 'G'
)
SELECT @averageWeight = ROUND(AVG([AverageWeight]), 2)
FROM [Weights_CTE];
ENDGOThe calling Java method is shown below.
调用Java方法如下所示。
/**
* CallableStatement example, (1) output parameter, returns Integer
*
* @return Average weight of all products
*/public double getAverageProductWeightOutCS() {
CallableStatement cstmt = null;
double averageWeight = 0;try {
cstmt = connection.getConnection().prepareCall(
"{call [Production].[uspGetAverageProductWeightOUT](?)}"); cstmt.registerOutParameter("averageWeight", Types.DECIMAL); cstmt.execute();
averageWeight = cstmt.getDouble("averageWeight");
} catch (Exception ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.SEVERE, null, ex);
} finally {
if (cstmt != null) {
try {
cstmt.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.WARNING, null, ex);
}
}
}
return averageWeight;
}示例5:使用输入参数调用存储过程 (Example 5: Calling a Stored Procedure with an Input Parameter)
In this example, the procedure returns a result set of type java.sql.ResultSet, of employees whose last name starts with a particular sequence of characters (e.g., ‘M’ or ‘Sa’). The sequence of characters is passed as an input parameter, lastNameStartsWith, to the stored procedure using the CallableStatement.
在此示例中,该过程返回员工姓氏以特定字符序列(例如“ M”或“ Sa”)开头的雇员的结果类型为java.sql.ResultSet的结果集。 使用CallableStatement将字符序列作为输入参数lastNameStartsWith传递到存储过程。
The method making the call iterates through the rows of the result set returned by the stored procedure, concatenating multiple columns to form the employee’s full name as a string. Each full name string is then added to an ordered collection of strings, a List<String> object. The List instance is returned by the method. You will notice this procedure takes a little longer to run because of the use of the LIKE operator. The database server has to perform pattern matching on each last name value in the table to determine the result set.
进行调用的方法遍历存储过程返回的结果集的行,将多列连接起来以字符串形式形成员工的全名。 然后,将每个全名字符串添加到一个有序的字符串集合(一个List<String>对象)中。 该方法返回列表实例。 您会注意到,由于使用了LIKE运算符,因此此过程需要花费更长的时间。 数据库服务器必须对表中的每个姓氏值执行模式匹配,以确定结果集。
CREATE OR
ALTER PROCEDURE [HumanResources].[uspGetEmployeesByLastName] @lastNameStartsWith VARCHAR(20) = 'A'AS
BEGIN
SET NOCOUNT ON;SELECT p.[FirstName], p.[MiddleName], p.[LastName], p.[Suffix], e.[JobTitle], m.[EmailAddress]
FROM [HumanResources].[Employee] AS e
LEFT JOIN [Person].[Person] p ON e.[BusinessEntityID] = p.[BusinessEntityID]
LEFT JOIN [Person].[EmailAddress] m ON e.[BusinessEntityID] = m.[BusinessEntityID]
WHERE e.[CurrentFlag] = 1
AND p.[PersonType] = 'EM' AND p.[LastName] LIKE @lastNameStartsWith + '%' ORDER BY p.[LastName], p.[FirstName], p.[MiddleName]
ENDGOThe calling Java method is shown below.
调用Java方法如下所示。
/**
* CallableStatement example, (1) input parameter, returns ResultSet
*
* @param lastNameStartsWith
* @return List of employee names
*/public List<String> getEmployeesByLastNameCS(String lastNameStartsWith) {CallableStatement cstmt = null;
ResultSet rs = null;
List<String> employeeFullName = new ArrayList<>();try {
cstmt = connection.getConnection().prepareCall(
"{call [HumanResources].[uspGetEmployeesByLastName](?)}",
ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_READ_ONLY);cstmt.setString("lastNameStartsWith", lastNameStartsWith); boolean results = cstmt.execute();
int rowsAffected = 0;// Protects against lack of SET NOCOUNT in stored procedure
while (results || rowsAffected != -1) {
if (results) {
rs = cstmt.getResultSet();
break;
} else {
rowsAffected = cstmt.getUpdateCount();
}
results = cstmt.getMoreResults();
}
while (rs.next()) {
employeeFullName.add(
rs.getString("LastName") + ", "
+ rs.getString("FirstName") + " "
+ rs.getString("MiddleName"));
}
} catch (Exception ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.SEVERE, null, ex);
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.WARNING, null, ex);
}
}
if (cstmt != null) {
try {
cstmt.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.WARNING, null, ex);
}
}
}
return employeeFullName;
}示例6:将结果集转换为对象的有序集合 (Example 6: Converting a Result Set to Ordered Collection of Objects)
In this last example, we pass two input parameters, productColor and productSize, to a stored procedure. The stored procedure returns a result set containing several columns of product information. This time, the example’s method iterates through the result set returned by the procedure and constructs an ordered collection of products, List<Product> object. The Product objects in the list are instances of the Product.java POJO class. The method converts each results set’s row-level field value into a Product property (e.g., Product.Size, Product.Model). Using a collection is a common method for persisting data from a result set in an application.
在最后一个示例中,我们将两个输入参数productColor和productSize传递给存储过程。 该存储过程返回一个包含几列产品信息的结果集。 这次,示例的方法遍历过程返回的结果集,并构造产品的有序集合List<Product>对象。 列表中的Product对象是Product.java POJO类的实例。 该方法将每个结果集的行级字段值转换为Product属性(例如Product.Size , Product.Model )。 使用集合是在应用程序中持久存储来自结果集的数据的常用方法。
CREATE OR
ALTER PROCEDURE [Production].[uspGetProductsByColorAndSize] @productColor VARCHAR(20),
@productSize INTEGERAS
BEGIN
SET NOCOUNT ON;SELECT p.[ProductNumber], m.[Name] AS [Model], p.[Name] AS [Product], p.[Color], p.[Size]
FROM [Production].[ProductModel] AS m
INNER JOIN
[Production].[Product] AS p ON m.[ProductModelID] = p.[ProductModelID]
WHERE (p.[Color] = @productColor)
AND (p.[Size] = @productSize)
ORDER BY p.[ProductNumber], [Model], [Product]
ENDGOThe calling Java method is shown below.
调用Java方法如下所示。
/**
* CallableStatement example, (2) input parameters, returns ResultSet
*
* @param color
* @param size
* @return List of Product objects
*/public List<Product> getProductsByColorAndSizeCS(String color, String size) {CallableStatement cstmt = null;
ResultSet rs = null; List<Product> productList = new ArrayList<>();try {
cstmt = connection.getConnection().prepareCall(
"{call [Production].[uspGetProductsByColorAndSize](?, ?)}",
ResultSet.TYPE_SCROLL_INSENSITIVE,
ResultSet.CONCUR_READ_ONLY);cstmt.setString("productColor", color);
cstmt.setString("productSize", size); boolean results = cstmt.execute();
int rowsAffected = 0;// Protects against lack of SET NOCOUNT in stored procedure
while (results || rowsAffected != -1) {
if (results) {
rs = cstmt.getResultSet();
break;
} else {
rowsAffected = cstmt.getUpdateCount();
}
results = cstmt.getMoreResults();
}while (rs.next()) {
Product product = new Product(
rs.getString("Product"),
rs.getString("ProductNumber"),
rs.getString("Color"),
rs.getString("Size"),
rs.getString("Model"));
productList.add(product);
}
} catch (Exception ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.SEVERE, null, ex);
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.WARNING, null, ex);
}
}
if (cstmt != null) {
try {
cstmt.close();
} catch (SQLException ex) {
Logger.getLogger(RunExamples.class.getName()).
log(Level.WARNING, null, ex);
}
}
}
return productList;
}正确的T-SQL:架构参考和括号 (Proper T-SQL: Schema Reference and Brackets)
You will notice in all T-SQL statements, I refer to the schema as well as the table or stored procedure name (e.g., {call [Production].[uspGetAverageProductWeightOUT](?)}). According to Microsoft, it is always good practice to refer to database objects by a schema name and the object name, separated by a period; that even includes the default schema (e.g., dbo).
您会注意到,在所有T-SQL语句中,我都引用了架构以及表或存储过程的名称(例如{call [Production].[uspGetAverageProductWeightOUT](?)} )。 根据Microsoft的经验 ,始终最好使用模式名称和对象名称(以句点分隔)来引用数据库对象。 甚至包括默认架构(例如dbo )。
You will also notice I wrap the schema and object names in square brackets (e.g., SELECT [ProductNumber] FROM [Production].[ProductModel]). The square brackets are to indicate that the name represents an object and not a reserved word (e.g, CURRENT or NATIONAL). By default, SQL Server adds these to make sure the scripts it generates run correctly.
您还将注意到我将模式和对象名称包装在方括号中(例如, SELECT [ProductNumber] FROM [Production].[ProductModel] )。 方括号表示该名称代表一个对象,而不是保留字 (例如CURRENT或NATIONAL )。 默认情况下,SQL Server添加这些以确保其生成的脚本正确运行。
运行示例 (Running the Examples)
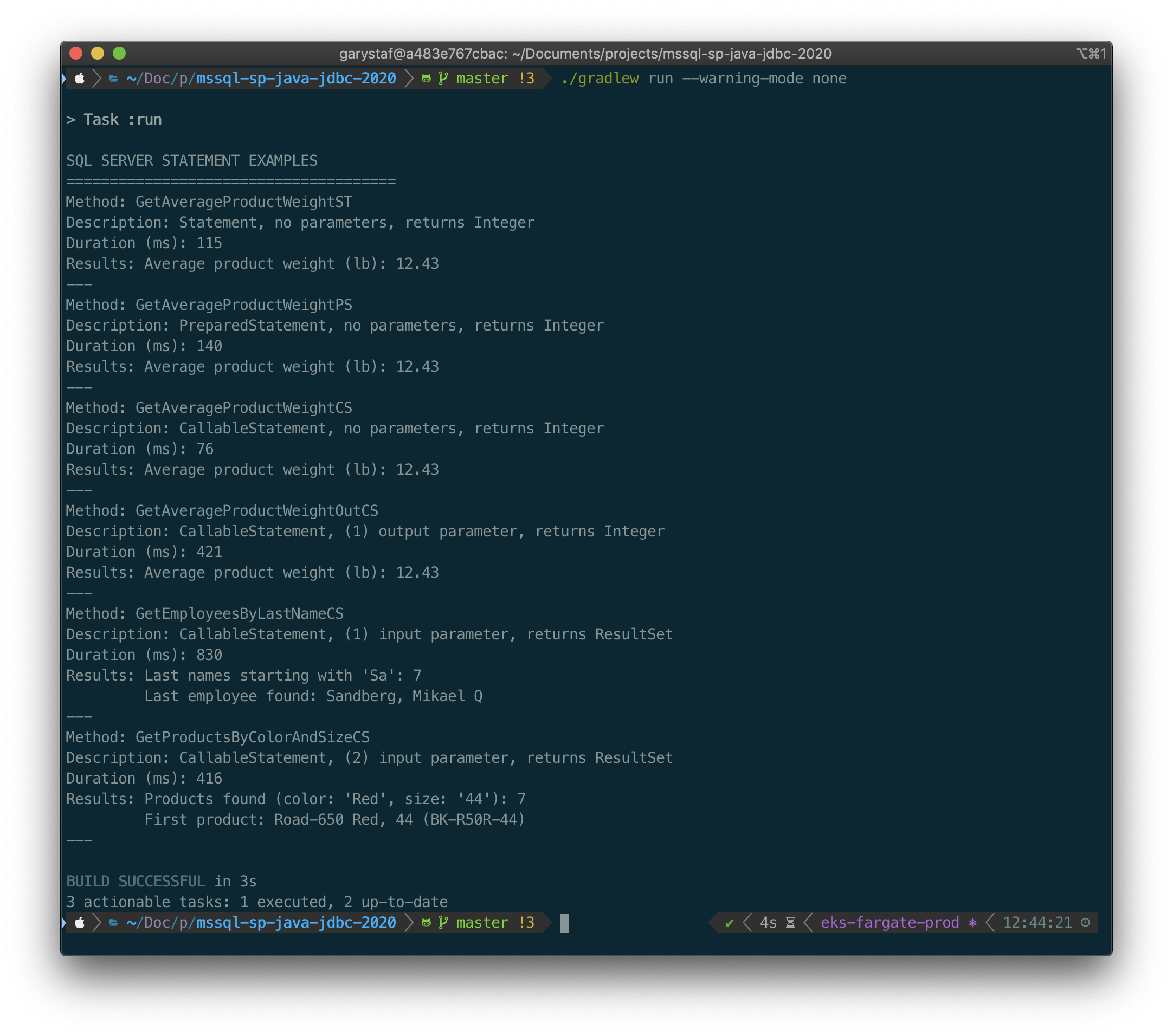
The application will display the name of the method being called, a method description, the duration of time it took to retrieve the data, and any results returned by the method.
应用程序将显示被调用方法的名称,方法说明,检索数据所花费的时间以及该方法返回的所有结果。
package com.article.examples;
import java.util.List;
/**
* Main class that calls all example methods
*
* @author Gary A. Stafford
*/
public class RunExamples {
private static final Examples examples = new Examples();
private static final ProcessTimer timer = new ProcessTimer();
/**
* @param args the command line arguments
* @throws Exception
*/
public static void main(String[] args) throws Exception {
System.out.println();
System.out.println("SQL SERVER STATEMENT EXAMPLES");
System.out.println("======================================");
// Statement example, no parameters, returns Integer
timer.setStartTime(System.nanoTime());
double averageWeight = examples.getAverageProductWeightST();
timer.setEndTime(System.nanoTime());
System.out.println("Method: GetAverageProductWeightST");
System.out.println("Description: Statement, no parameters, returns Integer");
System.out.printf("Duration (ms): %d%n", timer.getDuration());
System.out.printf("Results: Average product weight (lb): %s%n", averageWeight);
System.out.println("---");
// PreparedStatement example, no parameters, returns Integer
timer.setStartTime(System.nanoTime());
averageWeight = examples.getAverageProductWeightPS();
timer.setEndTime(System.nanoTime());
System.out.println("Method: GetAverageProductWeightPS");
System.out.println("Description: PreparedStatement, no parameters, returns Integer");
System.out.printf("Duration (ms): %d%n", timer.getDuration());
System.out.printf("Results: Average product weight (lb): %s%n", averageWeight);
System.out.println("---");
// CallableStatement, no parameters, returns Integer
timer.setStartTime(System.nanoTime());
averageWeight = examples.getAverageProductWeightCS();
timer.setEndTime(System.nanoTime());
System.out.println("Method: GetAverageProductWeightCS");
System.out.println("Description: CallableStatement, no parameters, returns Integer");
System.out.printf("Duration (ms): %d%n", timer.getDuration());
System.out.println("---");
// CallableStatement example, (1) output parameter, returns Integer
timer.setStartTime(System.nanoTime());
averageWeight = examples.getAverageProductWeightOutCS();
timer.setEndTime(System.nanoTime());
System.out.println("Method: GetAverageProductWeightOutCS");
System.out.println("Description: CallableStatement, (1) output parameter, returns Integer");
System.out.printf("Duration (ms): %d%n", timer.getDuration());
System.out.printf("Results: Average product weight (lb): %s%n", averageWeight);
System.out.println("---");
// CallableStatement example, (1) input parameter, returns ResultSet
timer.setStartTime(System.nanoTime());
String lastNameStartsWith = "Sa";
List<String> employeeFullName =
examples.getEmployeesByLastNameCS(lastNameStartsWith);
timer.setEndTime(System.nanoTime());
System.out.println("Method: GetEmployeesByLastNameCS");
System.out.println("Description: CallableStatement, (1) input parameter, returns ResultSet");
System.out.printf("Duration (ms): %d%n", timer.getDuration());
System.out.printf("Results: Last names starting with '%s': %d%n", lastNameStartsWith, employeeFullName.size());
if (employeeFullName.size() > 0) {
System.out.printf(" Last employee found: %s%n", employeeFullName.get(employeeFullName.size() - 1));
} else {
System.out.printf("No employees found with last name starting with '%s'%n", lastNameStartsWith);
}
System.out.println("---");
// CallableStatement example, (2) input parameters, returns ResultSet
timer.setStartTime(System.nanoTime());
String color = "Red";
String size = "44";
List<Product> productList =
examples.getProductsByColorAndSizeCS(color, size);
timer.setEndTime(System.nanoTime());
System.out.println("Method: GetProductsByColorAndSizeCS");
System.out.println("Description: CallableStatement, (2) input parameter, returns ResultSet");
System.out.printf("Duration (ms): %d%n", timer.getDuration());
if (productList.size() > 0) {
System.out.printf("Results: Products found (color: '%s', size: '%s'): %d%n", color, size, productList.size());
System.out.printf(" First product: %s (%s)%n", productList.get(0).getProduct(), productList.get(0).getProductNumber());
} else {
System.out.printf("No products found with color '%s' and size '%s'%n", color, size);
}
System.out.println("---");
examples.closeConnection();
}
}Below, we see the results.
下面,我们看到结果。
SQL语句性能 (SQL Statement Performance)
This post is certainly not about SQL performance, demonstrated by the fact I am only using Amazon RDS for SQL Server 2017 Express Edition on a single, very underpowered db.t2.micro Amazon RDS instance types. However, I have added a timer feature, ProcessTimer.java class, to capture the duration of time each example takes to return data, measured in milliseconds. The ProcessTimer.java class is part of the project code. Using the timer, you should observe significant differences between the first run and proceeding runs of the application for several of the called methods. The time difference is a result of several factors, primarily pre-compilation of the SQL statements and SQL Server plan caching.
这篇文章肯定不是关于SQL性能的,这一事实证明了我仅在单一的,功能不足的db.t2.micro Amazon RDS实例类型上使用SQL Server 2017 Express Edition的 Amazon RDS。 但是,我添加了一个计时器功能ProcessTimer.java类,以捕获每个示例返回数据所花费的时间(以毫秒为单位)。 ProcessTimer.java类是项目代码的一部分。 使用计时器,您应该观察到应用程序的第一次运行和后续运行之间有明显的区别。 时间差异是多种因素共同作用的结果,主要是SQL语句的预编译和SQL Server 计划缓存 。
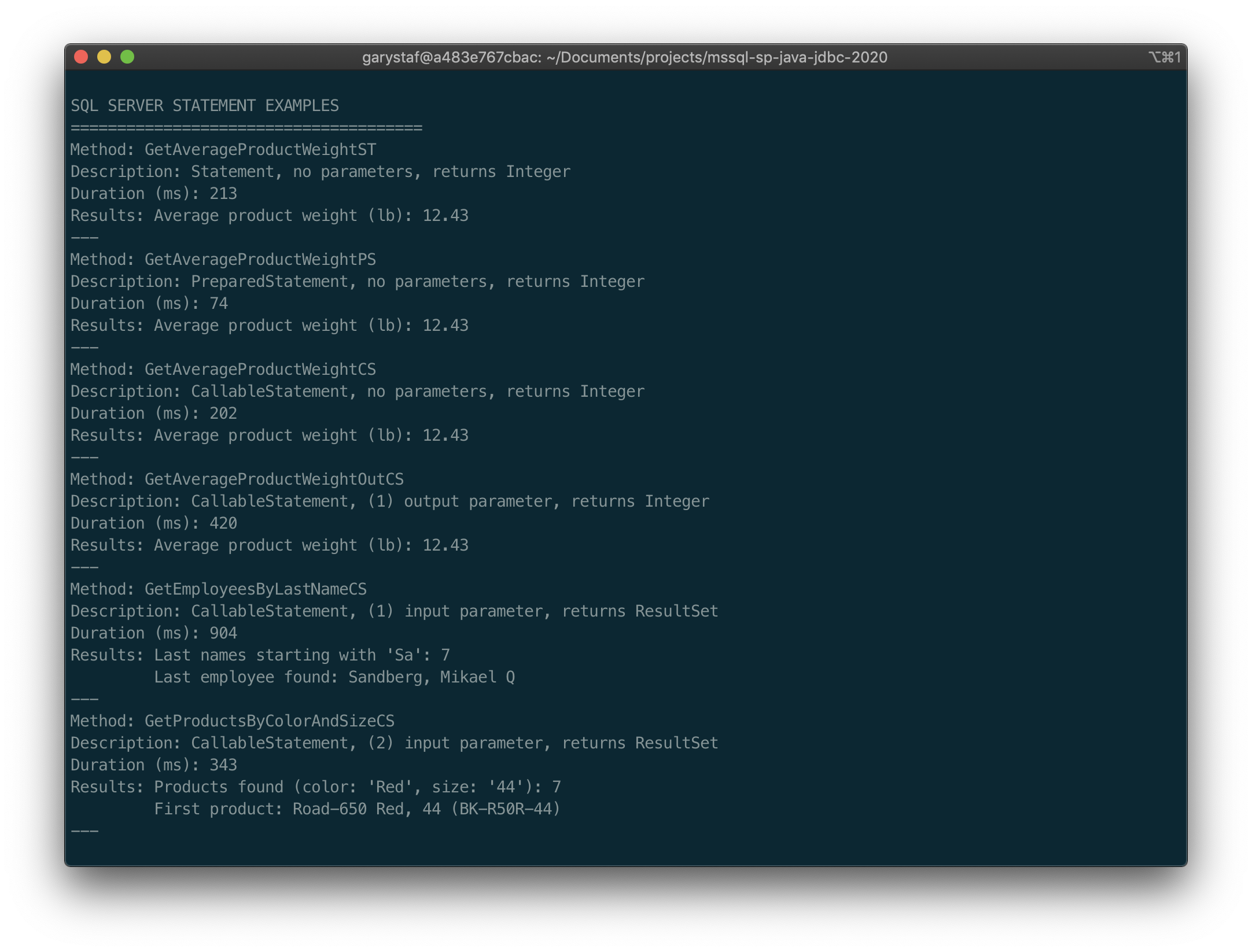
The effects of these two factors are easily demonstrated by clearing the SQL Server plan cache (see SQL script below) using DBCC (Database Console Commands) statements. and then running the application twice in a row. The second time, pre-compilation and plan caching should result in significantly faster times for the prepared statements and callable statements, in Examples 2–6. In the two random runs shown below, we see up to a 5x improvement in query time.
通过使用DBCC (数据库控制台命令)语句清除SQL Server计划缓存 ( 请参见下面SQL脚本 ),很容易证明这两个因素的影响。 然后连续两次运行该应用程序。 在示例2–6中,第二次预编译和计划缓存应大大缩短准备好的语句和可调用语句的时间。 在下面显示的两个随机运行中,我们发现查询时间最多提高了5倍。
USE AdventureWorks;DBCC FREESYSTEMCACHE('SQL Plans');
GOCHECKPOINT;
GO-- Impossible to run with Amazon RDS for Microsoft SQL Server on AWS
-- DBCC DROPCLEANBUFFERS;
-- GOThe first run results are shown below.
第一次运行结果如下所示。
SQL SERVER STATEMENT EXAMPLES
======================================
Method: GetAverageProductWeightST
Description: Statement, no parameters, returns IntegerDuration (ms): 122Results: Average product weight (lb): 12.43
---
Method: GetAverageProductWeightPS
Description: PreparedStatement, no parameters, returns IntegerDuration (ms): 146Results: Average product weight (lb): 12.43
---
Method: GetAverageProductWeightCS
Description: CallableStatement, no parameters, returns IntegerDuration (ms): 72Results: Average product weight (lb): 12.43
---
Method: GetAverageProductWeightOutCS
Description: CallableStatement, (1) output parameter, returns IntegerDuration (ms): 623Results: Average product weight (lb): 12.43
---
Method: GetEmployeesByLastNameCS
Description: CallableStatement, (1) input parameter, returns ResultSetDuration (ms): 830Results: Last names starting with 'Sa': 7
Last employee found: Sandberg, Mikael Q
---
Method: GetProductsByColorAndSizeCS
Description: CallableStatement, (2) input parameter, returns ResultSetDuration (ms): 427Results: Products found (color: 'Red', size: '44'): 7
First product: Road-650 Red, 44 (BK-R50R-44)
---The second run results are shown below.
第二次运行结果如下所示。
SQL SERVER STATEMENT EXAMPLES
======================================
Method: GetAverageProductWeightST
Description: Statement, no parameters, returns IntegerDuration (ms): 116Results: Average product weight (lb): 12.43
---
Method: GetAverageProductWeightPS
Description: PreparedStatement, no parameters, returns IntegerDuration (ms): 89Results: Average product weight (lb): 12.43
---
Method: GetAverageProductWeightCS
Description: CallableStatement, no parameters, returns IntegerDuration (ms): 80Results: Average product weight (lb): 12.43
---
Method: GetAverageProductWeightOutCS
Description: CallableStatement, (1) output parameter, returns IntegerDuration (ms): 340Results: Average product weight (lb): 12.43
---
Method: GetEmployeesByLastNameCS
Description: CallableStatement, (1) input parameter, returns ResultSetDuration (ms): 139Results: Last names starting with 'Sa': 7
Last employee found: Sandberg, Mikael Q
---
Method: GetProductsByColorAndSizeCS
Description: CallableStatement, (2) input parameter, returns ResultSetDuration (ms): 208Results: Products found (color: 'Red', size: '44'): 7
First product: Road-650 Red, 44 (BK-R50R-44)
---结论 (Conclusion)
This post has demonstrated several methods for querying and calling stored procedures from a SQL Server 2017 database using JDBC with the Microsoft JDBC Driver 8.4 for SQL Server. Although the examples are quite simple, the same patterns can be used with more complex stored procedures, with multiple input and output parameters, which not only select, but insert, update, and delete data.
这篇文章演示了几种使用JDBC和用于SQL Server的Microsoft JDBC Driver 8.4从SQL Server 2017数据库查询和调用存储过程的方法。 尽管示例非常简单,但是相同的模式可以用于更复杂的存储过程,并具有多个输入和输出参数,这些参数不仅可以选择数据,还可以插入,更新和删除数据。
There may be some limitations of the Microsoft JDBC Driver for SQL Server you should be aware of by reading the documentation. However, for most tasks that require database interaction, the Driver provides adequate functionality with SQL Server.
阅读文档应了解用于SQL Server的Microsoft JDBC驱动程序的某些限制。 但是,对于大多数需要数据库交互的任务,驱动程序提供了与SQL Server相同的功能。
This blog represents my own viewpoints and not of my employer, Amazon Web Services.
该博客代表了我自己的观点,而不代表我的雇主Amazon Web Services。
翻译自: https://towardsdatascience.com/java-development-with-microsoft-sql-server-ee6efd13f799














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









