





sci分类
Let us say you pose a complex question to a set of random people and collect the answers in to a data set. Now, you aggregate (take average of) all the answers present in the dataset , Many a time, your aggregate answer is either close or better compared to an expert’s solution to the complex problem. This principle is called wisdom of the crowd.
假设您向一组随机的人提出了一个复杂的问题,并将答案收集到一个数据集中。 现在,您可以汇总(取平均值)数据集中存在的所有答案,很多时候,与专家对复杂问题的解决方案相比,您的汇总答案接近或更好。 这个原则被称为群众智慧。
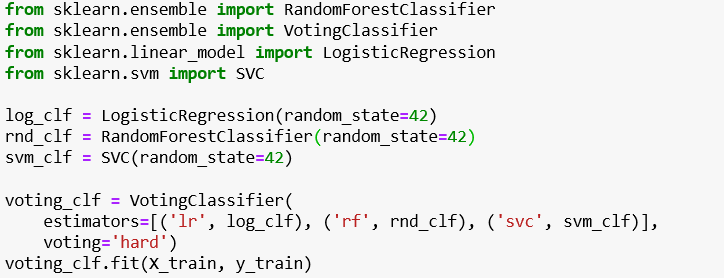
The above mentioned principle applies to machine learning in order to have a better model performance in terms of accuracy and sustainability. We generally have a group of predictors (classifiers/regressors) which forms an ensemble, that yields a better prediction when compared to the individual best predictor. This technique is called as ensemble learning and the algorithm that is used to predict the aggregate of the ensemble is called as ensemble method. If an ensemble contains only the decision tree classifiers/regressors we call it a Random Forest. In this article we discuss about Hard, Soft Voting used to achieve higher accuracy together with Random Forests as an ensemble.
上述原则适用于机器学习,以便在准确性和可持续性方面具有更好的模型性能。 通常,我们有一组构成整体的预测变量(分类器/回归变量) , 与单独的最佳预测变量相比,可以产生更好的预测。 该技术称为集成学习,而用于预测集成集合的算法称为集成方法。 如果一个集成仅包含决策树分类器/回归器,我们将其称为随机森林。 在本文中,我们将讨论用于实现更高准确性的“硬,软投票”,以及“随机森林”作为整体。
How does the ensemble method choose the winning class?
集成方法如何选择获胜类?
There are two methods to determine the winning class in the ensemble learning by aggregating the predictions of each classifier in the ensemble and predict the class that gets the most votes. This is called Hard voting. To generalize a group of weak learners in an ensemble could also provide a strong learner, when there are (weak learners)in sufficient number with high diversity.
通过汇总集合中每个分类器的预测并预测获得最多选票的类,有两种方法可以确定集合学习中的获胜类。 这称为硬投票。 当有足够数量的(弱学习者)具有高度多样性时,概括一个整体中的弱学习者也可以提供一个强大的学习者。
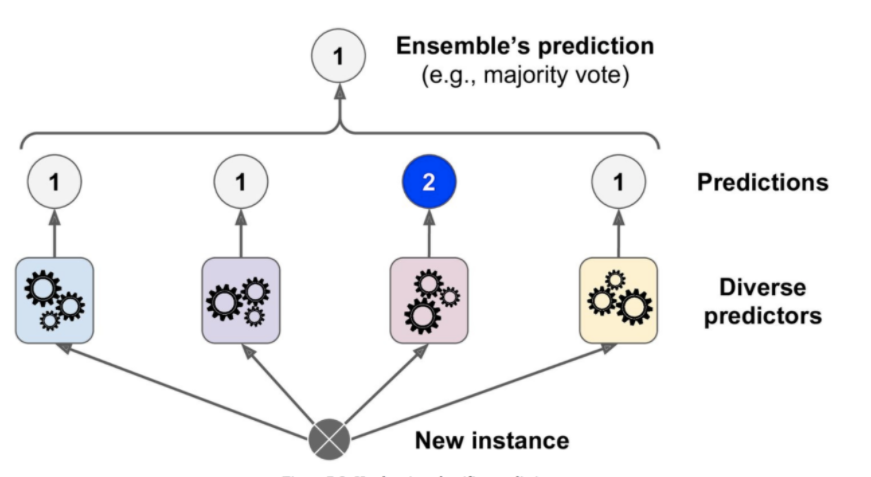
If the classifiers in ensemble learning are able to predict probability (using predict_proba() method , for example Decision Trees in the ensemble), then the class with highest class probability , averaged over all the classifiers, is the winning class. This method is called Soft voting. Both Hard voting and soft voting can be done using scikit -learn’s VotingClassifier.
如果整体学习中的分类器能够预测概率(使用predict_proba()方法,例如整体中的决策树),则在所有分类器上平均的具有最高分类概率的分类就是获胜分类。 此方法称为软投票。 硬投票和软投票都可以使用scikit -learn的VotingClassifier进行。
To illustrate Voting classifier , let us take make_moons dataset which is a pre-defined dataset in sklearn. we take a total samples of 500 (n_samples) and a standard deviation of 30% (noise = 0.30) is added to the data.
为了说明投票分类器,让我们采用make_moons数据集,它是sklearn中的预定义数据集。 我们总共抽取500个样本(n_samples),并将标准偏差30%(噪声= 0.30)添加到数据中。


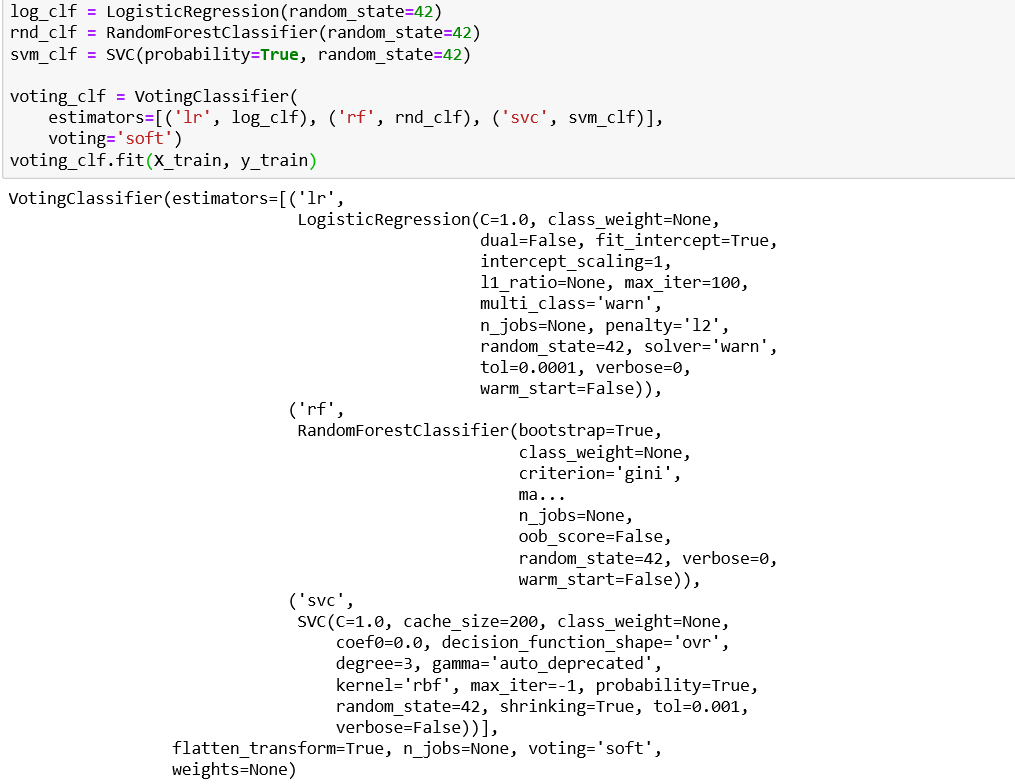
If the parameter voting in VotingClassifier is set to “soft”
如果VotingClassifier中的voting参数设置为“ soft”
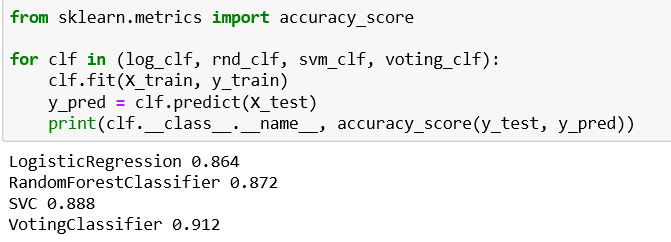
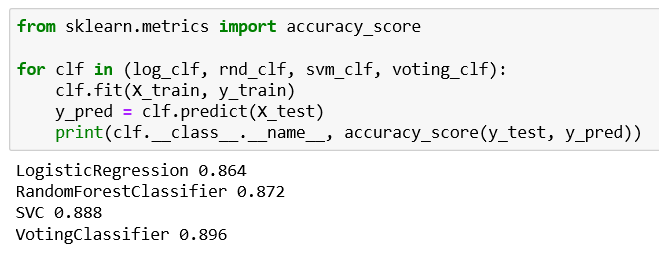
we get 91.2% as the accuracy for soft voting that predict the aggregate of class probabilities and 89.6% of accuracy for hard voting. This is because, soft voting takes the uncertainties of the classifiers in the final decision. Depending on the classifiers in the ensemble we use either Hard/Soft voting to predict with higher accuracy.
我们获得91.2%的软投票准确度,该准确度可以预测类别概率的总和,而89.6%的准确投票准确度可以预测类别概率的总和。 这是因为,软投票会在最终决策中考虑分类器的不确定性。 根据集合中的分类器,我们使用硬/软投票来进行更高精度的预测。
R
[R
As we discussed , and ensemble of decision trees is called a Random forest. They are generally trained by Bagging (training all the decision tree classifiers on different training subsets , with samples selected at random with replacement)methods(or sometimes pasting (samples selected at random without replacement)) typically max_samples parameter is set to size of the training set. We can use RandomForestClassifer class in Scikit -learn for Classification and RandomForestRegressor for regression tasks. Let us look into the code explaining some parameters that can be passed into RandomForestClassifer.
正如我们所讨论的,决策树的集合称为随机森林。 通常通过Bagging训练(在不同的训练子集上训练所有决策树分类器,使用随机选择的样本进行替换)方法(或有时粘贴(随机选择的样本而不进行替换))通常将max_samples参数设置为训练的大小组。 我们可以将Scikit -learn中的RandomForestClassifer类用于分类,将RandomForestRegressor用于回归任务。 让我们看一下解释一些可以传递给RandomForestClassifer的参数的代码。
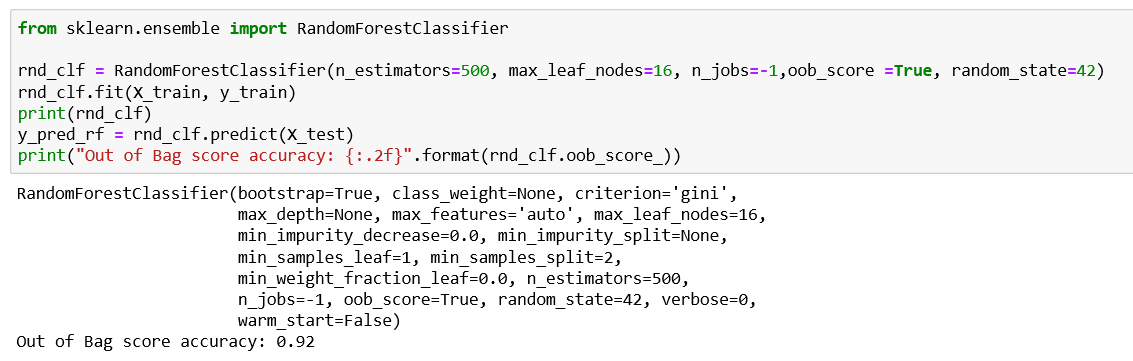
RandomForestClassifier(bootstrap=True, class_weight=None, criterion=’gini’, max_depth=None, max_features=’auto’, max_leaf_nodes=16, min_impurity_decrease=0.0, min_impurity_split=None, min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=500, n_jobs=-1, oob_score=False, random_state=42, verbose=0, warm_start=False)
RandomForestClassifier(自举=真,class_weight =无,标准= '基尼',MAX_DEPTH =无,max_features = '自动',max_leaf_nodes = 16,min_impurity_decrease = 0.0,min_impurity_split =无,min_samples_leaf = 1,min_samples_split = 2,min_weight_fraction_leaf = 0.0, n_estimators = 500 , n_jobs = -1 , oob_score = False ,random_state = 42,verbose = 0,warm_start = False)
bootstrap is set to True to implement Bagging and False to implement pasting. Crierion, min_sample_leaf,min_sample_split,max_depth are already explained in my previous article of Decision Tree classifier.n_estimators are set to determine number of trees to be build.n_jobs is the parameter to decide on how many CPU cores does the algorithm shall run(If set to ‘-1' , the algorithm will run on al the available CPU cores).Averaging more trees will yield a more robust ensemble by reducing overfitting. max_features determines how random each tree is, and a smaller max_features reduces overfitting. In general, it’s a good rule of thumb to use the default values: max_features=sqrt(n_features) [Auto]for classification and max_features=log2(n_features) for regression. oob_score (out of bag score) is set to either True/False whether to use out-of-bag samples to estimate the generalization accuracy from the samples that are not ‘bagged’ before considering to use the test set for validation. oob_decsion_function returns a 2D array that predicts the probabilities of classes for each training instance that are used in training the model.
bootstrap设置为True以实现装袋,而False则实现粘贴。 Crierion,min_sample_leaf,min_sample_split,max_depth已在我之前的决策树分类器文章中进行了解释。 n_estimators设置为确定要构建的树数。n_jobs是用于确定算法应运行多少个CPU内核的参数(如果设置为-1,则算法将在所有可用的CPU内核上运行)。通过减少过度拟合,更多的树木将产生更强大的合奏。 max_features确定每棵树的随机性,较小的max_features减少过度拟合。 通常,使用默认值是一个很好的经验法则: max_features = sqrt(n_features)[自动]用于分类,max_features = log2(n_features)用于回归。 oob_score(袋外评分)设置为True / False或False,是否在考虑使用测试集进行验证之前是否使用袋外样本来估计没有“袋装”的样本的泛化精度。 oob_decsion_function返回一个2D数组,该数组预测用于训练模型的每个训练实例的类的概率。
References:
参考资料:
- Hands-on Machine Learning with Scikit-Learn, Keras & TensorFlow — Aurelien Geron 使用Scikit-Learn,Keras和TensorFlow进行动手机器学习— Aurelien Geron
- Introduction to Machine Learning with Python — Andreas C. Müller & Sarah Guido 使用Python进行机器学习的简介— Andreas C.Müller和Sarah Guido
sci分类















 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









