





The goal is to solve a diabetes classification problem using an artificial neural network with training method of genetic algorithm. Discovering performance difference of different parameters of the ANN model and comparing this training method with additional optimizers like stochastic gradient descent, RMSprop and Adam optimizer.
目的是使用带有遗传算法训练方法的人工神经网络解决糖尿病分类问题。 发现ANN模型不同参数的性能差异,并将此训练方法与其他优化器(例如随机梯度下降,RMSprop和Adam优化器)进行比较。
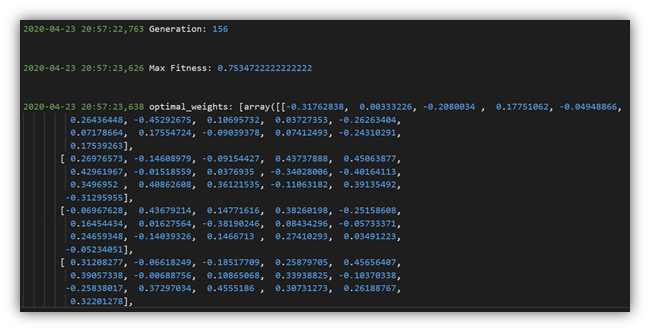
Inputs and Outputs
输入和输出
In the provided diabetes dataset (diabetes.txt), there are 11 columns: first column represents the bias with all values equal to one; The second to the ninth columns are values of features; The 10th column is the label column which indicates whether the tuple is classified as diabetes or not.
在提供的糖尿病数据集( diabet.txt )中,共有11列:第一列代表所有值都等于1的偏差; 第二至第九列是要素的值; 第10列是标签列,指示该元组是否归类为糖尿病。
During all trainings, the input for all ANNs will consist of the bias and all 8 features together with the label value (y) while the output of the ANNs should be the predicted output according to the ANN’s computation. The training label (y) is to help the ANN to tune its weights in each layers in order to compute an predicted output that is as close as the training label (y). As for the inputs and outputs of the layers in the ANN model, starting from the input layer, all outputs from each layer will become the inputs for the next layer (Here we are building a Sequential model).
在所有训练期间,所有ANN的输入将包括偏差和所有8个特征以及标签值(y),而ANN的输出应为根据ANN的计算得出的预测输出。 训练标签(y)可以帮助ANN调整每层的权重,以便计算出与训练标签(y)一样近的预测输出。 至于ANN模型中各层的输入和输出,从输入层开始,每层的所有输出将成为下一层的输入(此处我们正在构建顺序模型)。
Gathering Training Data
收集培训数据
From the diabetes dataset (diabetes.txt) I divided all 768 tuples into two parts: let the first 75% tuples be the training data and the rest 25% of the tuples be the final testing data.
从糖尿病数据集(diabetes.txt)中,我将所有768个元组分为两部分:让第一个75%的元组作为训练数据,其余的25%的元组作为最终测试数据。
ANN learning/ training method
人工神经网络学习/训练方法
In this project, I built an artificial neural network using genetic algorithm to optimize the weights in each layer of the training model in order to get a higher accuracy in predicting the unseen diabetes dataset.
在这个项目中,我使用遗传算法构建了一个人工神经网络,以优化训练模型每一层的权重,以便在预测看不见的糖尿病数据集时获得更高的准确性。
Initially, for a constant number of populations (e.g. 20) is set, the sequential model will generate the weights of all layers for each population randomly. Then the training data will be fed into the training model and the predicting process begins. After the fitness calculation which is a comparison of the true output and the predicted output, the program will update the maximum fitness value for the final training since its weights are the optimal ones and could likely yield a higher accuracy in the final training stage. This process will continue go on until the maximum generation is met.
最初,对于固定数量的人口(例如20),顺序模型将为每个人口随机生成所有层的权重。 然后将训练数据输入训练模型中,开始预测过程。 在对真实输出和预测输出进行比较的适应度计算之后,该程序将更新最终训练的最大适应度值,因为其权重是最优的,并且可能在最终训练阶段产生更高的准确性。 此过程将继续进行,直到达到最大发电量为止。
After optimizing the weight matrix, the optimal matrix will be set to the ANN model and be ready to generalize the testing data. In one particular example, I set the model with one input layer, three hidden layers with eight, six, and six neurons respectively, and finally one neuron for the output layer.
在优化权重矩阵之后,将最优矩阵设置为ANN模型,并准备将测试数据推广。 在一个特定的示例中,我将模型设置为一个输入层,三个隐藏层分别具有八个,六个和六个神经元,最后为输出层一个神经元。
Ensure the ANN can generalize well
确保人工神经网络可以很好地推广
Although it is very hard to promise that the ANN can always generalize the testing data well, applying genetic algorithm could possibly help raise the accuracy rate by preventing the model from being trapped in a local minimum scenario.
尽管很难保证ANN总是能够很好地概括测试数据,但是应用遗传算法可能会通过防止模型陷入局部最小场景中来帮助提高准确率。
The three key parts of genetic algorithm (GA) is: selection, crossover, and mutation. First, the mechanism selects the elite parents to the gene pool (an array that keeps track of the best matrix of weights) for child production to realize the elitism. Second, crossover is implemented. Among the best genes (weighted matrix), the mechanism selects two genes randomly and recombines them in a certain approach which is defined in the provided python code. For instance, in this case, I randomly choose a split point for the elite gene 1 and gene 2. Then I concatenate the second part of gene 2 to the first part of gene 1 and perform the reverse method for the remaining parts of the two genes. As a result, I have two recombined possibly elite genes. Third, mutation might occur since it happens on a random basis. Each generation after performing the crossover, the mechanism will generate a random number between 0 to 1. If the random generated number is less than or equal to 0.05, a particular part of the weighted matrix which is also defined randomly will be multiplied by another random number between 2 and 5. By slightly scaling some values in the weighted matrix can help achieve the mutation process in order to prevent the ANN model from being trained in a wrong direction (yielding a lower training accuracy rate).
遗传算法(GA)的三个关键部分是:选择,交叉和变异。 首先,该机制将精英父母选择到基因库(跟踪最佳权重矩阵的阵列)中,以供孩子生产以实现精英主义。 第二,实现交叉。 在最佳基因(加权矩阵)中,该机制随机选择两个基因,并以提供的python代码中定义的某种方法将它们重组。 例如,在这种情况下,我为精英基因1和基因2随机选择一个分割点,然后将基因2的第二部分连接到基因1的第一部分,并对这两个部分的其余部分执行相反的方法基因。 结果,我有两个可能重组的精英基因。 第三,突变可能会发生,因为它是随机发生的。 执行分频后的每一代,该机制都会生成一个介于0到1之间的随机数。如果随机生成的数小于或等于0.05,则也随机定义的加权矩阵的特定部分将与另一个随机数相乘。数值在2到5之间。通过略微缩放加权矩阵中的某些值可以帮助实现变异过程,以防止ANN模型在错误的方向上训练(产生较低的训练准确率)。
There are so many factors that could affect the performance of an ANN. Including the number of layers and number of neurons in each layer, learning rate, optimization function, loss function and others. In genetic algorithm, population size, number of generations, crossover rate, and mutation rate and its probability also need to be considered when building the ANN. For instance, in theory, if the mutation rate and its mutation probability is high, the model should come up with a weighted matrix with a higher variance of values than those with lower mutation rate and lower mutation probability. Its main goal is to try to solve the drawback of the traditional gradient descent learning algorithm by ensuring having various possible weighted matrix instead of possibly training a model in a wrong approach without getting an optimal solution for any problem.
有太多因素会影响人工神经网络的性能。 包括层数和每层中的神经元数,学习率,优化函数,损失函数等。 在遗传算法中,构建人工神经网络时还需要考虑种群大小,世代数,交叉率,变异率及其概率。 例如,从理论上讲,如果突变率及其突变概率很高,则该模型应该得出一个加权矩阵,该矩阵的值方差要高于那些具有较低突变率和概率的概率。 它的主要目标是通过确保具有各种可能的加权矩阵,而不是用错误的方法训练模型而没有获得任何问题的最佳解决方案,从而尝试解决传统梯度下降学习算法的缺点。
Performance comparison of different training methods
不同训练方法的表现比较
To compare different training algorithm or methods, I tested ANN models with SGD (Stochastic Gradient Descent), RMSprop (Root Mean Square Propagation), and Adam (Adaptive moment estimation) training methods using keras model in python. Below are the results of different algorithm.
为了比较不同的训练算法或方法,我使用python中的keras模型测试了具有SGD(随机梯度下降),RMSprop(均方根传播)和Adam(自适应矩估计)训练方法的ANN模型。 以下是不同算法的结果。
- SGD: 新币:
Epoch 1000/1000
时代1000/1000
576/576 [=======================] — 0s 36us/step — loss: 0.2256 — accuracy: 0.6562
576/576 [======================] — 0s 36us / step —损耗:0.2256 —精度:0.6562
Test accuracy: 0.6354166865348816
测试精度:0.6354166865348816
- RMSprop: RMSprop:
Epoch 1000/1000
时代1000/1000
576/576 [=======================] — 0s 36us/step — loss: 0.1508 — accuracy: 0.7778
576/576 [======================] — 0s 36us / step —损耗:0.1508 —精度:0.7778
Test accuracy: 0.7760416865348816
测试精度:0.7760416865348816
- Adam: 亚当:
Epoch 1000/1000
时代1000/1000
576/576 [=======================] — 0s 35us/step — loss: 0.1483 — accuracy: 0.7830
576/576 [======================] — 0s 35us / step —损耗:0.1483 —精度:0.7830
Test accuracy: 0.78125
测试精度:0.78125
- GA: GA:
Training max fitness: 0.78472
训练最大适合度:0.78472
Test accuracy: 0.77
测试精度:0.77
From the experiment above, we can see that stochastic gradient descent method indeed has a problem of converging to the global minimum and therefore resulting an accuracy that is lower than other training methods. On the other hand, genetic algorithm performs well since it has selection, crossover, and mutation mechanisms that could improve the local minimum dilemma by producing variant kinds of genes (weighted matrix) and selecting the best among them.
从上面的实验中,我们可以看到,随机梯度下降法确实存在收敛到全局最小值的问题,因此其准确性低于其他训练方法。 另一方面,遗传算法之所以表现良好,是因为它具有选择,交叉和变异机制,可以通过产生变异基因(加权矩阵)并从中选择最佳基因来改善局部最小困境。
Parameters tuning and discoveries
参数调整和发现
There are factors that may affect the genetic algorithm based ANN model’s performance such as number of layers, number of neurons in one layer, population size and number of generations. I ran through some training to try discovering performance of the model with different parameters.
有一些因素可能会影响基于遗传算法的ANN模型的性能,例如层数,一层中的神经元数,种群大小和世代数。 我进行了一些培训,以尝试发现具有不同参数的模型的性能。
Here to simplify the expression,
这里为了简化表达,
- iL = input layer iL =输入层
- hL = hidden layer(s)hL =隐藏层
- oL = output layeroL =输出层
- n = number of neurons in one layern =一层中的神经元数量
1. Tune the number of neurons
1.调整神经元的数量
These trainings and testing are using genetic algorithm with 20 initial populations and were run in 200 generations.
这些培训和测试使用了具有20个初始种群的遗传算法,并运行了200代。
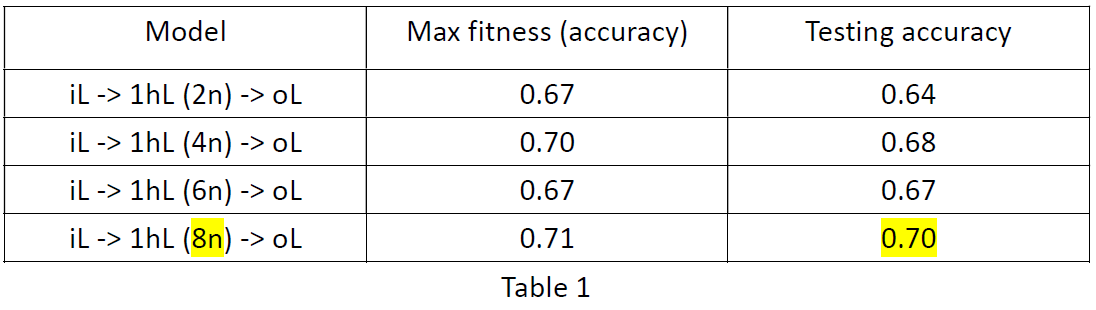
From table 1, it is obvious that with all parameters remain the same but only tune the number of neurons in the only hidden layer, the more neurons in the layer has a higher accuracy in classifying the unseen data. Although the testing accuracy and maximum fitness are not strictly increasing along with the increased number of neurons in the hidden layer, it shows a clear trend of the number of neurons in a layer and accuracy rate.
从表1中可以明显看出,在所有参数保持不变的情况下,仅调整了唯一隐藏层中神经元的数量,该层中的神经元越多,对看不见的数据进行分类的准确性就越高。 尽管随着隐藏层中神经元数量的增加,测试准确性和最大适应度并未严格提高,但它显示出一层中神经元数量和准确率的明显趋势。
2. Increase the number of layers and tune the number of neurons in each layer
2.增加层数并调整每层中的神经元数
These trainings and testing are using genetic algorithm with 20 initial populations and were run in 200 generations.
这些培训和测试使用了具有20个初始种群的遗传算法,并进行了200代的运行。
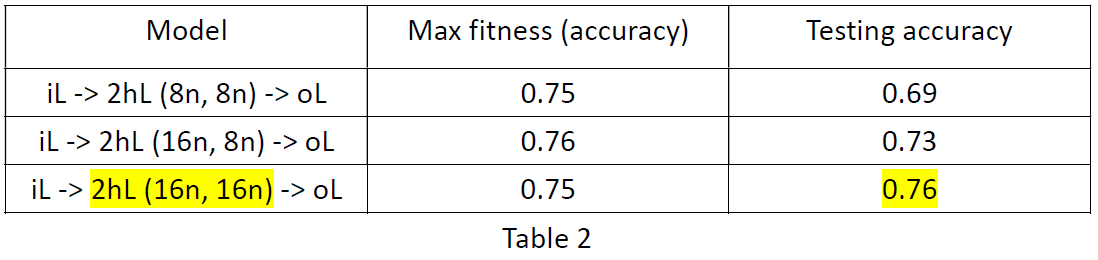
According to table 2, with more neurons in each layer, the testing accuracy gets higher. The result reinforces the discovery from table 1. Additionally, comparing table 1 and table 2, we can observe that more hidden layers can also raise the accuracy rate.
根据表2,每层神经元越多,测试精度越高。 结果加强了对表1的发现。此外,通过比较表1和表2,我们可以观察到更多的隐藏层也可以提高准确率。
3. Tuning the population size
3.调整人口规模
From many trials I discovered that tuning the initial population size doesn’t have significant impact on improving the accuracy rate since the genetic algorithm mechanism will eventually tune the weighted matrix towards an optimal status.
从许多试验中,我发现调整初始种群大小不会对提高准确率产生重大影响,因为遗传算法机制最终会将加权矩阵调整为最佳状态。
4. Tuning the number of generations
4.调整世代数
Same as tuning the population size of the gene pool, it is also hard to say that with more generations, the higher accuracy one will get. From many trials I trained the model with 10, 25, 50, 100 and 200 generations, sometimes 10 generations yield a better result (test accuracy = 0.72) than 50 generations (test accuracy = 0.64). however, according to rule of thumbs, there is still a higher probability for models with higher number of generations that generates a better weighted matrix and yields a better accuracy score.
与调整基因库的种群大小相同,也很难说随着世代的增加,将获得更高的准确性。 从许多试验中,我训练了10、25、50、100和200代的模型,有时10代产生的结果(测试精度= 0.72)比50代(测试精度= 0.64)更好。 但是,根据经验法则,具有更高世代数的模型仍然具有更高的概率,该模型生成更好的加权矩阵并产生更好的准确性得分。
Others
其他
Improving the current GA based ANN model
改进当前基于GA的ANN模型
Alternatively, in order to achieve a higher accuracy apart from merely applying the genetic algorithm, I tried to attach an additional training for the ANN model which is by applying the Adam optimizer with Mean squared error regression loss function to compile the ANN model with the optimal weight matrix. The followings are my discoveries:
另外,为了获得更高的准确度,除了仅应用遗传算法外,我还尝试对ANN模型进行附加训练,即通过应用具有均方误差回归损失函数的Adam优化器来编译具有最优模型的ANN模型。权重矩阵。 以下是我的发现:
E.g. 1:Parameters:Sequential Model with sigmoid activation function:Input layer: 8 neurons,First Hidden layer: 6 neurons,Second Hidden layer: 6 neurons,Third Hidden layer: 4 neurons,Output layer: 1 neuron,Optimizer: Adam (learning rate = 0.001),Loss function: Mean Squared Error,Initial population: 20,Number of Epochs: 1000
例如1:参数:具有S型激活函数的顺序模型:输入层:8个神经元,第一隐藏层:6个神经元,第二隐藏层:6个神经元,第三隐藏层:4个神经元,输出层:1个神经元,优化器:亚当(学习率= 0.001),损失函数:均方误差,初始填充量:20,历元数:1000
Result:Accuracy of training data after 1000 epochs: 0.7812,Loss after 1000 epochs: 0.1486,Accuracy of testing data: 0.79
结果:1000个周期后训练数据的准确性:0.7812; 1000个周期后训练数据的损失:0.1486,测试数据的准确性:0.79
Code (Program) explanation
代码(程序)说明
Note: All codes are written in python with keras model for the ANN training.
注意:所有代码均使用python和keras模型编写,用于ANN训练。
遗传算法 (Genetic Algorithm)
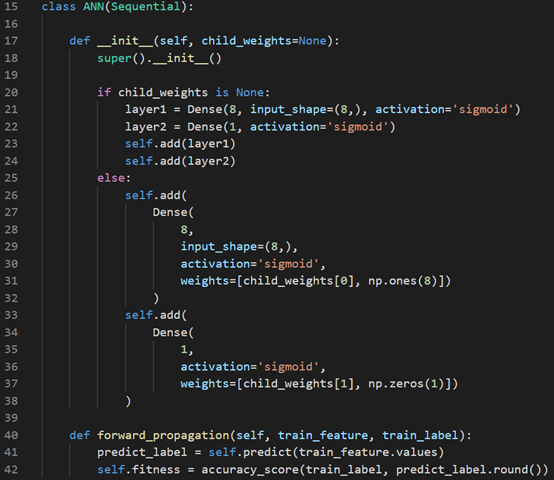
The two main purposes for the ANN model (class) is to set the weighted matrix and perform forward propagation to calculate the fitness score for each model. Here we have one input layer (with 8 inputs), one hidden layer (with 8 neurons), and one output layer (with one output) together with “sigmoid” as activation functions.
ANN模型(类)的两个主要目的是设置加权矩阵并执行正向传播以计算每个模型的适应性得分。 在这里,我们有一个输入层(有8个输入),一个隐藏层(有8个神经元)和一个输出层(有一个输出)以及“ Sigmoid”作为激活函数。
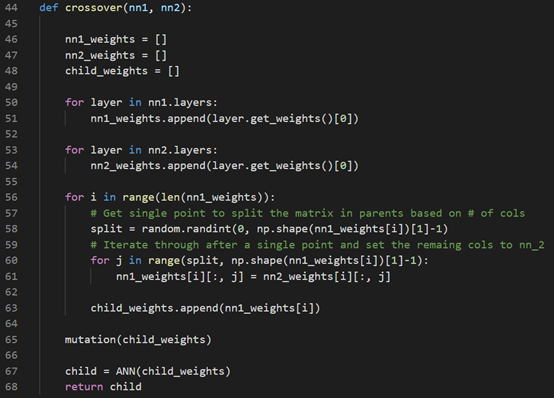
The crossover function uses two parents (two ANNs) to generate a child. Here, we randomly find a splitting point for dividing both parents’ weights and recombined them as a new child. After that, the child will be added to the networks array for future selection.
交叉功能使用两个父级(两个ANN)生成一个子级。 在这里,我们随机找到一个分割点,用于划分父母双方的权重并将其重新组合为一个新孩子。 之后,该子项将被添加到网络阵列以供将来选择。
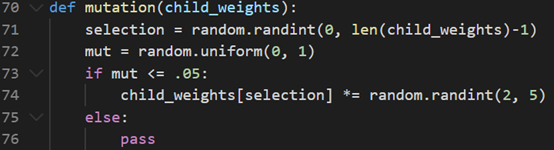
The mutation occurs on a random basis. Here the mutation rate is set to 0.05 and if the random number generated is lower or equal to the mutation rate, some parts of the weighted matrix will be scaled up or down in terms of values between 2 times to 5 times.
突变是随机发生的。 此处将突变率设置为0.05,如果生成的随机数小于或等于突变率,则加权矩阵的某些部分将按2倍至5倍之间的值进行缩放。
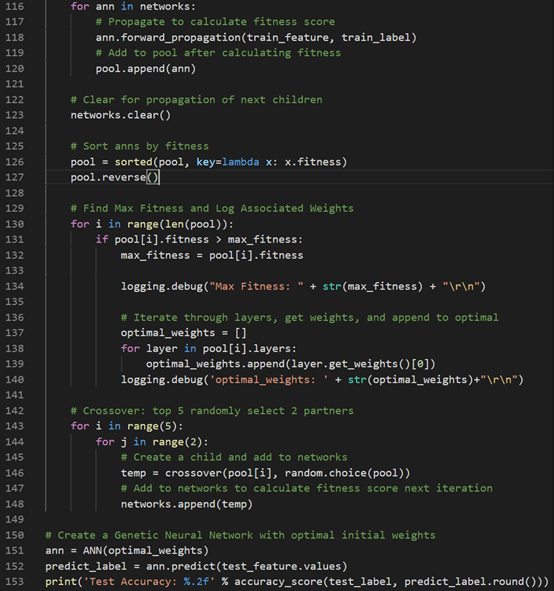
Here is the starting point of the GA ANN program. Under an epoch times of loops, the program will perform the above actions:
这是GA ANN计划的起点。 在一个循环的时代里,程序将执行上述操作:
1. Calculate the fitness scores and sort the ANNs according to the fitness scores.2. Select 2 parents from the top 5 parents and conduct crossover (the mutation will be conducted within the crossover function randomly).
1.计算健身分数,并根据健身分数对人工神经网络进行排序。2。 从前5位父母中选择2位父母并进行交叉(突变将在交叉功能内随机进行)。
Finally, set the optimal weighted to the ANN and feed in the testing dataset.
最后,将最佳权重设置为ANN并输入测试数据集。
遗传算法+ Adam优化器(替代解决方案) (Genetic Algorithm + Adam Optimizer (Alternative solution))

Inside the ANN model (class) we can add the above section for the final compilation after adding the optimal weighted matrix to the ANN instance.
在ANN模型(类)内部,我们可以在将最佳加权矩阵添加到ANN实例之后,添加以上部分进行最终编译。

Like the pure GA ANN algorithm, we just add one line (line 176) to compile the model using Adam optimizer and “mean squared error” as the loss function to try to improve the current GA algorithm.
像纯GA ANN算法一样,我们仅需添加一条线(第176行)就可以使用Adam优化器和“均方误差”作为损失函数来编译模型,以尝试改进当前的GA算法。
Saeed, A., 2020. Using Genetic Algorithm For Optimizing Recurrent Neural Network. [online] Aqibsaeed.github.io. Available at: <http://aqibsaeed.github.io/2017-08-11-genetic-algorithm-for-optimizing-rnn/> [Accessed 25 April 2020].
Saeed,A.,2020年。使用遗传算法优化递归神经网络。 [在线] Aqibsaeed.github.io。 可在以下网址获得:<http://aqibsaeed.github.io/2017-08-11-genetic-algorithm-for-optimizing-rnn/> [2020年4月25日访问]。
翻译自: https://medium.com/@jonathan.kuo33/genetic-algorithm-in-artificial-neural-network-5f5b9c9467d0














 6739
6739











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









