





ssm整合 api
Yield Analytics (YA) is one of hundreds of products offered by Xandr that adds value to advertisers seeking to reach customers at scale. The YA product serves as an “oracle” for customers by using historic data from advertisers to make quantitative predictions about current and future campaigns. Technically speaking, YA has been around since 07'. While it isn’t sporting a near two-decade lifetime like Windows XP, it is a mature piece of software by any standard.
Yield Analytics( YA )是Xandr提供的数百种产品之一 ,可以为寻求大规模吸引客户的广告客户增加价值。 YA产品通过使用广告商的历史数据来对当前和未来的广告活动进行定量预测,从而成为客户的“Oracle”。 从技术上讲, YA从07'开始就存在。 尽管它不像Windows XP那样具有近两个十年的使用寿命,但按任何标准来看,它都是一款成熟的软件。
Through the years of development cycles YA has accumulated a number of configurable options reflected at the client level. Some options give control over core forecasting metrics, others address data pipelining parameters, and still others work to integrate third party features. All of these options in total results in each client having (approximately) 700–1000 configuration key-value pairs. Adding insult to injury is the spread of sources that the key-values are found in. Some exist in the source code, others are present in a multitude of XML files, and still others exist in a database. Conflicting keys can override one another as defined by a pseudo-hierarchy at runtime.
在多年的开发周期中, YA积累了许多可配置选项,反映在客户端级别。 一些选项可以控制核心预测指标,另一些可以解决数据流水线参数,还有一些可以集成第三方功能。 所有这些选项的总结果是,每个客户端具有(大约)700-1000个配置键值对。 在键值所在的源代码中散布会增加伤害。在源代码中有些存在,在其他XML文件中存在,在数据库中也存在。 在运行时,有冲突的密钥可以相互覆盖,这由伪层次结构定义。
Any developer or service tech looking to make changes to a client configuration must understand the following:
任何希望更改客户端配置的开发人员或服务技术人员都必须了解以下内容:
- Out of the (on-average) 1000 configurations for a client, which key or group of keys do I need to change? 在客户机的(平均)1000个配置中,我需要更改哪个密钥或一组密钥?
- What source are those keys in? An XML file, a database, or perhaps some combination of the two? 这些密钥输入什么来源? XML文件,数据库还是两者的某种组合?
- Do any overrides exist in the same source or other sources which could conflict with the new value? 同一来源或其他来源中是否存在任何可能与新值冲突的替代?
- What is a reasonable value to use for that configuration? 用于该配置的合理值是多少?
- If a change is made, will it be made in the correct source location? 如果进行了更改,将在正确的源位置进行更改吗?
The time commitment alone to change even a single configuration value becomes increasingly large with each complication. Obviously, this has become a serious pain point among developers and services alike.
每次复杂化,仅改变甚至单个配置值的时间投入就变得越来越大。 显然,这已成为开发人员和服务人员的严重痛苦点。
设计解决方案 (Designing a Solution)
A good solution to the configuration problem eliminates most of the above complexities, and adds a few small features:
一个很好的解决配置问题的方法消除了上述大多数复杂性,并增加了一些小功能:
- Clearly defines the location of configuration keys, reasonable values, and override hierarchy 明确定义配置键的位置,合理的值和覆盖层次结构
- Defines a seamless add, update, and manipulate single keys and groups of keys 定义无缝的添加,更新和操作单个键和键组
- Log configuration changes and the users that made them 日志配置更改以及进行更改的用户
Bearing in mind the requirements, several attempts were made at designing a robust yet understandable data backend.
考虑到需求,在设计健壮但易于理解的数据后端时进行了几次尝试。
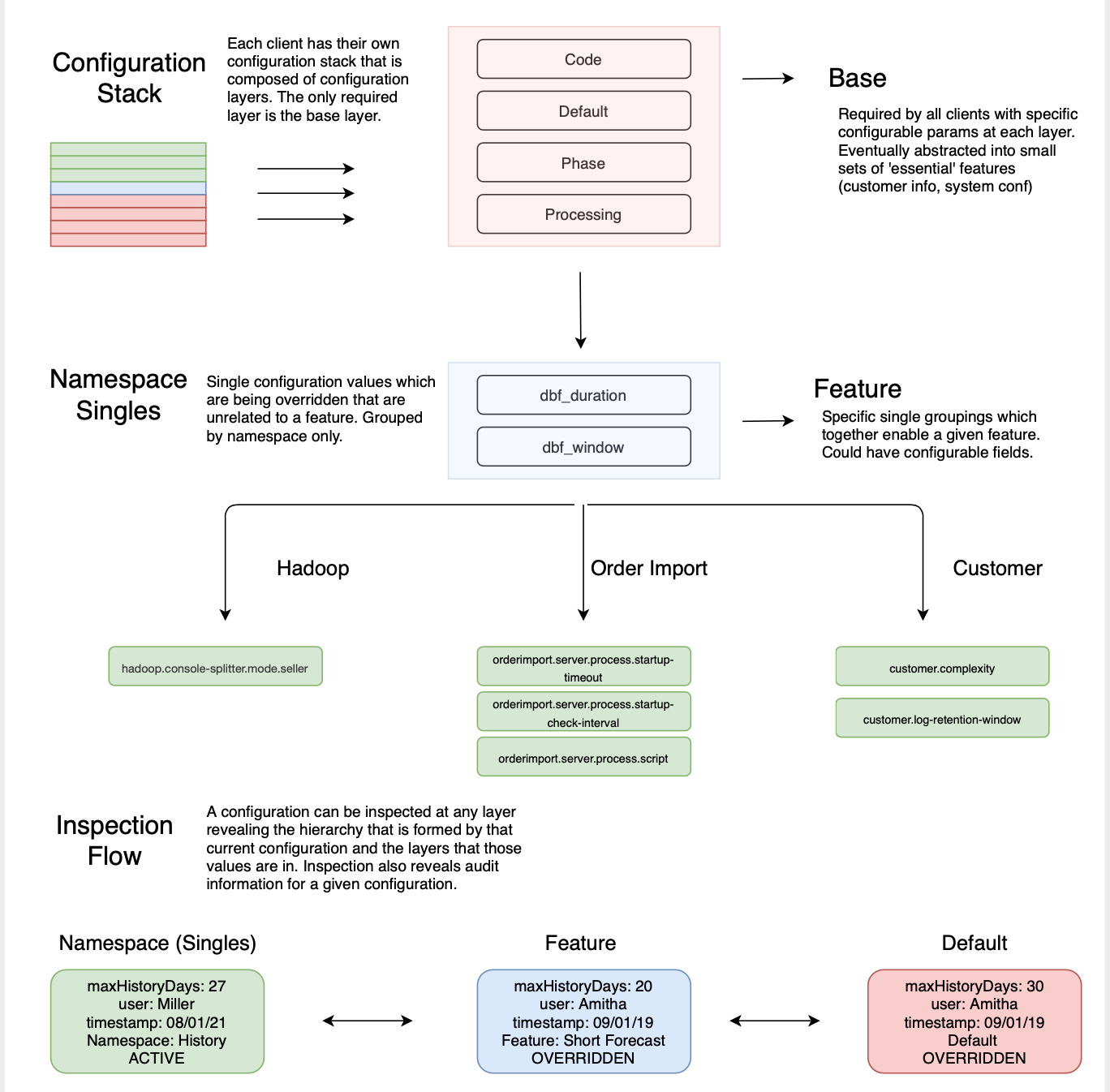
The first iteration represented groupings of configurations with a wrapper for the Commons Configuration object that I coined a Layer. The Layer objects were composed to complete a Configuration Stack — not unlike the Commons CompositeConfiguration object. Primarily, the Layer objects served as metadata containers for singleton configurations and groupings of configurations which naturally belonged together.
第一次迭代表示配置分组,其中包含我创造了Layer的Commons Configuration对象的包装。 组成Layer对象以完成配置堆栈 -与Commons CompositeConfiguration对象不同。 首先,Layer对象用作元数据容器,用于单例配置和自然属于在一起的配置分组。
While the Layer system lent itself well to forming a hierarchy, the data views became cumbersome as each client required their own configuration stack to be queried. Additionally, placing configurations in pre-determined groups proved to be almost impossible as the naming schemes even within features were inconsistent.
尽管Layer系统非常适合形成层次结构,但是由于每个客户端都需要查询自己的配置堆栈,因此数据视图变得笨拙。 此外,将配置放入预定组几乎是不可能的,因为即使在要素内的命名方案也不一致。

The second iteration elected to store only the unique values found for each configuration key, as well as a default value. The unique values are then responsible for managing which clients point to them and for which grouping they are active. Storing only unique values and client names brought surprising simplification to the necessary data views and updates, enabling the system to store complete information about a single configuration in a set of maps.
选择第二次迭代仅存储为每个配置键找到的唯一值以及默认值。 然后,唯一值负责管理哪些客户端指向他们,以及哪些客户端处于活动状态。 仅存储唯一值和客户端名称就可以简化必要的数据视图和更新,从而使系统能够在一组映射中存储有关单个配置的完整信息。
Despite the advantages this design offers regarding data retrieval and modification, the hierarchy is weakly represented by a group parameter in each unique value. In an attempt to address this design weakness, a graph relationship was proposed that could capture the required data and enable more dynamic searches. However — in the absence of creating a fully connected structure — the requirements of uniqueness when attempting to locate a given node could not be fulfilled. Ultimately, the V2 unique-value structure was decided to be the best solution moving forward.
尽管此设计在数据检索和修改方面提供了优势,但层次结构却很难通过每个唯一值中的组参数来表示。 为了解决此设计缺陷,提出了一种图形关系,该图形关系可以捕获所需的数据并启用更多的动态搜索。 但是,在没有创建完全连接的结构的情况下,尝试定位给定节点时无法满足唯一性的要求。 最终, V2唯一值结构被认为是向前发展的最佳解决方案。
输入Quarkus和GraphQL (Enter Quarkus & GraphQL)
To support the new configuration backend, an API was created which handles all data transactions related to configurations. The Quarkus framework is used for general convenience and its really sweet ability to compile to a native executable. A MicroProfile GraphQL implementation from SmallRye is made available within the Quarkus library, and is used extensively throughout the configuration API.
为了支持新的配置后端,创建了一个API,用于处理与配置有关的所有数据事务。 Quarkus框架用于一般的便利,并且它具有编译为本地可执行文件的强大功能 。 Quarkus库中提供了SmallRye的MicroProfile GraphQL实现 ,并且在整个配置API中得到了广泛使用。
MicroProfile GraphQL is a fairly new paradigm which enables users to take advantage of automated schema generation and simplified annotations to quickly build efficient GraphQL endpoints. Phillip Krueger — a core developer on the SmallRye GraphQL project — has a fantastic post here which contrasts MicroProfile to a more traditional JAX-RS implementation. It also gives a more general overview of GraphQL and why you might be interested in using it for your development.
MicroProfile GraphQL是一个相当新的范例,它使用户能够利用自动模式生成和简化的注释来快速构建有效的GraphQL端点。 菲利普·克鲁格-在SmallRye GraphQL项目核心开发者-拥有一个梦幻般的岗位在这里它对比MicroProfile到一个更传统的JAX-RS实现。 它还提供了GraphQL的更一般的概述,以及为什么您可能会对在开发中使用它感兴趣。
Now that you’re all caught up on the latest and greatest in the GraphQL world, the details of the configuration API implementation should be a breeze. If you look back to the V2 architecture diagram, you’ll see that there are two primary entities we are going to represent with schemas: ConfigurationObject and UniqueValue.
现在您已经掌握了GraphQL领域的最新知识和最新知识,配置API实现的细节应该轻而易举。 如果回头看V2架构图,您会发现我们将使用模式表示两个主要实体: ConfigurationObject和UniqueValue 。

Both the ConfigurationObject and the UniqueValue fields are described plainly by the GraphQL schema introspection. It should be noted that the clientValue field in the ConfigurationObject is actually a field that is only used on the query side to determine if a new UniqueValue needs to be created.
GraphQL架构自省清楚地描述了ConfigurationObject和UniqueValue字段。 应当注意, ConfigurationObject中的clientValue字段实际上是仅在查询侧用于确定是否需要创建新的UniqueValue的字段。

A master mapping of ConfigurationObjects is maintained by the configuration API in-memory and on a Postgres database utilizing the reactive client. All users are allowed to query the API to determine current configurations for clients.
ConfigurationObjects的主映射由内存中的配置API维护,并利用React式客户端在Postgres数据库上维护。 允许所有用户查询API,以确定客户端的当前配置。
变更请求和审核 (Change Requests & Audit)
If a mutation — new configuration or modification — needs to be made, system users can submit a request to the API containing the proposed changes. An administrator can then approve or deny the mutation request. Selective endpoint — or in this case function — security is made possible with annotations and roles via the Quarkus security library. The current API implementation only uses basic file permissions as a proof-of-concept, but the supporting authentication source can be changed without modifying annotations as long as the roles and users align.
如果需要进行突变(新的配置或修改),则系统用户可以向API提交包含所建议的更改的请求。 然后,管理员可以批准或拒绝突变请求。 选择性端点(在这种情况下为功能)可通过Quarkus 安全库通过注释和角色来实现安全性 。 当前的API实现仅使用基本文件权限作为概念证明,但是只要角色和用户对齐,就可以在不修改注释的情况下更改支持的身份验证源。
The request system also doubles as an audit log. Any change request is timestamped and marked with the username of the request creator. In a similar manner to request creation, approval by the administrator is noted on the stored request object.
请求系统还兼作审核日志。 任何更改请求都带有时间戳,并标记有请求创建者的用户名。 以类似于请求创建的方式,在存储的请求对象上记录了管理员的批准。
未来的工作 (Future Work)
Virtually all of the remaining work (save deployment) regarding the configuration API can be attributed to the deficiency in the V2 design. Namely:
实际上,与配置API有关的所有其余工作(保存部署)都可以归因于V2设计中的缺陷。 即:
Despite the advantages this design offers regarding data retrieval and modification, the hierarchy is weakly represented by a group parameter in each unique value.
尽管此设计在数据检索和修改方面提供了优势,但层次结构却很难通过每个唯一值中的组参数来表示。
Ideally, the hierarchy between configuration groupings — formerly sources — can be represented using a property more intrinsic to the system. One example of such a feature would be graph traversal order. If the end result utilizes overrides occurring from different groups, the traversal order of a graph can represent a pre-set ‘tier’ at each iteration. Unfortunately the problem hasn’t proven to be that simple to solve. At each junction in a new design, it seems that a sacrifice must be made regarding data views, performance, or application footprint.
理想情况下,可以使用系统固有的属性来表示配置组之间的层次结构(以前是源)。 这种功能的一个例子是图形遍历顺序。 如果最终结果利用了来自不同组的替代,则图的遍历顺序可以表示每次迭代时的预设“层”。 不幸的是,该问题尚未得到解决。 在新设计的每个结点上,似乎都必须在数据视图,性能或应用程序占用空间方面做出牺牲。
关于作者 (About the Author)
I am a second year master’s student at Colorado State University studying Computer Science. My work focuses primarily on technology at scale. I have interests in anything outdoors, table top games, and my parents’ dog, Fred.
我是科罗拉多州立大学的二年级硕士研究生,学习计算机科学。 我的工作主要集中于大规模技术。 我对户外活动,桌上游戏和父母的狗弗雷德(Fred)感兴趣。
翻译自: https://medium.com/xandr-tech/consolidating-configurations-with-graphql-and-quarkus-42fdc515b705
ssm整合 api















 818
818

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









