





Importing data is the first step in any data science project. Often, you’ll work with data in CSV files and run into problems at the very beginning.
导入数据是任何数据科学项目的第一步。 通常,您将使用CSV文件中的数据,并在一开始就遇到问题。
Among the problems, parse date columns are the most common to us. In this article, we will cover the following most common parse date columns problems:
在这些问题中,解析日期列是我们最常见的问题。 在本文中,我们将介绍以下最常见的解析日期列问题:
- Reading date columns from a CSV file 从CSV文件读取日期列
- Day first format (DD/MM, DD MM or, DD-MM) 第一天格式(DD / MM,DD MM或DD-MM)
- Combining multiple columns to a datetime 将多个列合并到一个日期时间
- Customizing a date parser 自定义日期解析器
Please check out my Github repo for the source code.
请查看我的Github存储库以获取源代码。
1.从CSV文件读取日期列 (1. Reading date columns from a CSV file)
By default, date columns are represented as objects when loading data from a CSV file.
默认情况下,从CSV文件加载数据时,日期列表示为对象 。
For example, data_1.csv
例如, data_1.csv
date,product,price
1/1/2019,A,10
1/2/2020,B,20
1/3/1998,C,30And the date column gets read as an object data type using the default read_csv():
然后使用默认的read_csv()将date列读取为对象数据类型:
df = pd.read_csv('data/data_1.csv')
df.info()RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 3 non-null object
1 product 3 non-null object
2 price 3 non-null int64
dtypes: int64(1), object(2)
memory usage: 200.0+ bytesTo read the date column correctly, we can use the argument parse_dates to specify a list of date columns.
为了正确读取日期列,我们可以使用参数parse_dates指定日期列的列表。
df = pd.read_csv('data/data_3.csv', parse_dates=['date'])
df.info()RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 3 non-null datetime64[ns]
1 product 3 non-null object
2 price 3 non-null int64
dtypes: datetime64[ns](1), int64(1), object(1)
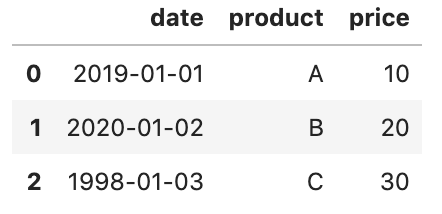
memory usage: 200.0+ bytesNow, the DataFrame should look like below
现在,DataFrame应该如下所示
2.天数优先格式(DD / MM,DD MM或DD-MM) (2. Day first format (DD/MM, DD MM or, DD-MM))
By default, the argument parse_dates will read date data with month first (MM/DD, MM DD, or MM-DD) format, and this arrangement is relatively unique in the United State.
默认情况下,参数parse_dates将以月份parse_dates ( MM / DD , MM DD或MM-DD )的格式读取日期数据,并且这种安排在美国是相对唯一的。
In most of the rest of the world, the day is written first (DD/MM, DD MM, or DD-MM). If you would like Pandas to consider day first instead of month, you can set the argument dayfirst to True.
在世界上大多数其他地方,日期是第一个写入的日期( DD / MM , DD MM或DD-MM )。 如果希望Pandas考虑第一天而不是月份,则可以将参数dayfirst设置为True 。
pd.read_csv('data/data_1.csv',
parse_dates=['date'],
dayfirst=True)
Alternatively, you can customize a date parser to handle day first format. Please checkout the solution in the “4. Customizing a date parser”.
或者,您可以自定义日期解析器以处理第一天的格式。 请在“ 4.自定义日期解析器 ”中签出解决方案。
3.将多个列合并到一个日期时间 (3. Combining multiple columns to a datetime)
Sometimes date is split up into multiple columns, for example, year, month, and day
有时,日期会分为多个列,例如year , month和day
year,month,day,product,price
2019,1,1,A,10
2019,1,2,B,20
2019,1,3,C,30
2019,1,4,D,40To combine them into a datetime, we can pass a nested list to parse_dates.
要将它们合并为日期时间,我们可以将嵌套列表传递给parse_dates 。
df = pd.read_csv('data/data_4.csv',
parse_dates=[['year', 'month', 'day']])
df.info()RangeIndex: 4 entries, 0 to 3
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 year_month_day 4 non-null datetime64[ns]
1 product 4 non-null object
2 price 4 non-null int64
dtypes: datetime64[ns](1), int64(1), object(1)
memory usage: 224.0+ bytesNotice that the column name year_month_day is generated automatically. To specify a custom column name, we can pass a dictionary instead.
请注意,列名year_month_day是自动生成的。 要指定自定义列名称,我们可以改为传递字典。
df = pd.read_csv('data/data_4.csv',
parse_dates={ 'date': ['year', 'month', 'day'] })
df.info()RangeIndex: 4 entries, 0 to 3
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- ----- 0 date 4 non-null datetime64[ns]
1 product 4 non-null object
2 price 4 non-null int64
dtypes: datetime64[ns](1), int64(1), object(1)
memory usage: 224.0+ bytes4.自定义日期解析器 (4. Customizing a date parser)
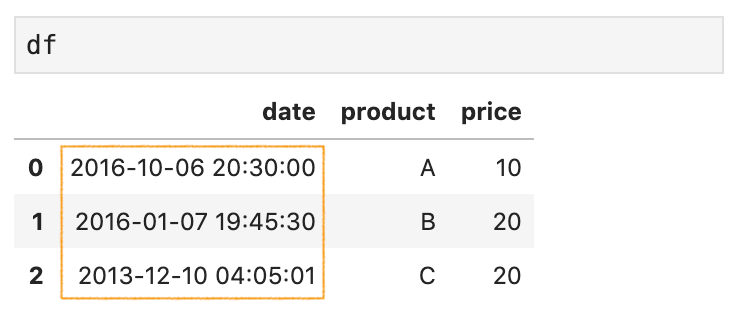
By default, date columns are parsed using the Pandas built-in parser from dateutil.parser.parse. Sometimes, you might need to write your own parser to support a different date format, for example, YYYY-DD-MM HH:MM:SS:
默认情况下,日期列使用dateutil.parser.parse的Pandas内置解析器进行dateutil.parser.parse 。 有时,您可能需要编写自己的解析器以支持其他日期格式,例如YYYY-DD-MM HH:MM:SS :
date,product,price
2016-6-10 20:30:0,A,10
2016-7-1 19:45:30,B,20
2013-10-12 4:5:1,C,20The easiest way is to write a lambda function which can read the data in this format, and pass the lambda function to the argument date_parser.
最简单的方法是编写一个lambda函数,该函数可以读取这种格式的数据,并将lambda函数传递给参数date_parser 。
from datetime import datetimecustom_date_parser = lambda x: datetime.strptime(x, "%Y-%d-%m %H:%M:%S")df = pd.read_csv('data/data_6.csv',
parse_dates=['date'],
date_parser=custom_date_parser)
df.info()RangeIndex: 3 entries, 0 to 2
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 date 3 non-null datetime64[ns]
1 product 3 non-null object
2 price 3 non-null int64
dtypes: datetime64[ns](1), int64(1), object(1)
memory usage: 200.0+ bytesNow, the date column has been read correctly in Pandas Dataframe.
现在,已在Pandas Dataframe中正确读取了date列。
而已 (That’s it)
Thanks for reading.
谢谢阅读。
Please checkout the notebook on my Github for the source code.
请在我的Github上查看笔记本中的源代码。
Stay tuned if you are interested in the practical aspect of machine learning.
如果您对机器学习的实用方面感兴趣,请继续关注。
Some relevant articles
一些相关文章















 267
267

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









