





苹果推送服务器推送延迟
Photo by Fay Fernandes on Unsplash
在开始项目之前 (Before I started the Project)
As for why I chose to partake in this project, I wanted to be able to expand my knowledge on the resources, libraries, and software available to me as an aspiring data analyst. In doing so, I was able to get some hands-on experience using numerous AWS services, working with APIs, making a website from scratch using HTML/CSS , and using JavaScript to enhance the site.
至于为什么选择参与这个项目,我希望能够扩展我对作为有抱负的数据分析师可用的资源,库和软件的知识。 通过这样做,我能够获得使用大量AWS服务,使用API,使用HTML / CSS从头开始创建网站以及使用JavaScript增强网站的动手经验。
At the moment Twitter is arguably at the forefront for how millions of people receive their news. As a result, we can rely on that data to identify trends or to uncover breaking new stories and in turn allows for individuals/companies to make more informed decisions. By leveraging this resource brands can increase their public outlook by fixing or cutting their losses on a product that has poor sentiment. Furthermore, they’ll be able to better their interactions with customers around the globe.
目前,Twitter可以说是数百万人如何接收其新闻的最前沿。 结果,我们可以依靠这些数据来识别趋势或发现突破性的新故事,从而允许个人/公司做出更明智的决定。 通过利用这些资源,品牌可以通过修复或减少情绪低落的产品的损失来提高公众的视野。 此外,他们将能够改善与全球客户的互动。
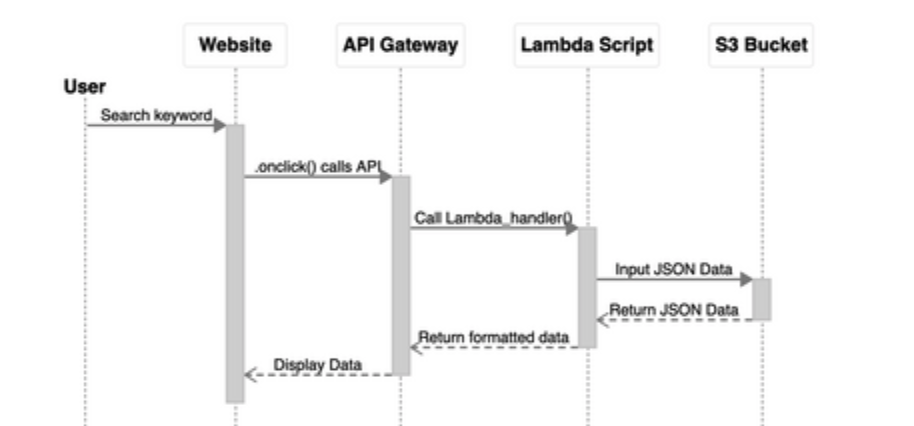
Here’s how I envisioned the flow of the project would go before I did any coding or anything like that. The user will interact with the website by entering a keyword. The website would then access the API once the user submits the search. Then the API endpoint will call the Python function, and the python script will input some JSON data to the S3 bucket so that it can be stored. This tool was created using a free resource called ZenUML, which allows you to make Sequence diagrams using code.
这是我预想的项目流程将在进行任何编码或类似操作之前进行的方式。 用户将通过输入关键字与网站进行交互。 用户提交搜索后,网站将访问API。 然后,API端点将调用Python函数,并且python脚本会将一些JSON数据输入到S3存储桶中,以便可以存储它们。 该工具是使用称为ZenUML的免费资源创建的,该资源可让您使用代码制作序列图。
制作网站模型 (Making a Mockup of Website)
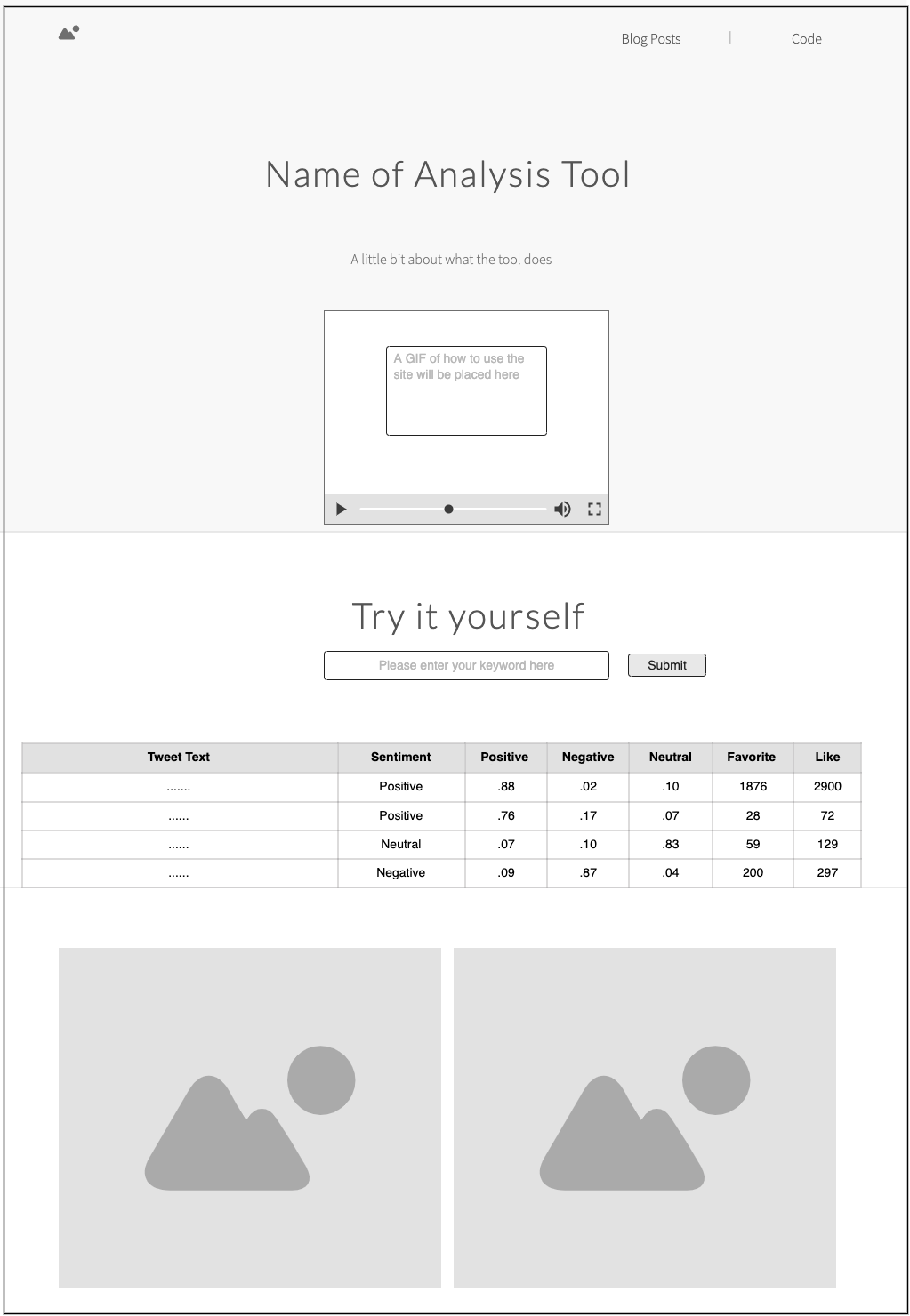
When deciding what I wanted the website to look like I had to ask myself what is the bare minimum that the website needs? Well I need to have a place for the user to search, a submit button to submit the search, and table to display the data. In addition to those three components I figured it would be important to have links to the code and blog posts, and in the future I would include a place for visualizations and a spot to showcase a video or GIF of me making the web app. The tool used to make this mockup is a free tool called Moqups.
在决定我想要网站的外观时,我不得不问自己,网站需要的最低限度是多少? 好吧,我需要有一个供用户搜索的地方,一个提交按钮以提交搜索以及一个表以显示数据。 除了我认为的这三个组件之外,具有指向代码和博客文章的链接也很重要,并且将来,我将包括一个可视化的地方和一个展示我制作Web应用程序的视频或GIF的位置。 用于制作此模型的工具是一个称为Moqups的免费工具。
制作网站 (Making the Website)
Now that I had an idea of what my site was going to look like I created two files, index.html and style.css. The index file will hold the content of the page including the javascript code while the style file will simply format the webpage.
现在,我已经了解了网站的外观,然后创建了两个文件index.html和style.css。 索引文件将包含包括javascript代码在内的页面内容,而样式文件将仅对网页进行格式设置。
<form id= "search-keyword" onsubmit="return false">
<input type="text" name="keywordSearch" id="keyword" placeholder="Enter your keyword here">
<input type="submit" onclick="loadData();" id="submit">
</form>This code in this <form> tag is the main foundation seeing that it allows the website to interact with Javascript. In short the user will enter the keyword in the search and once they click the submit button the Javascript code will be called to run the loadData() function.
该<form>标记中的这段代码是主要的基础,它使网站可以与Javascript进行交互。 简而言之,用户将在搜索中输入关键字,一旦单击提交按钮,将调用Javascript代码来运行loadData()函数。
<script type="text/javascript">
const tweetData = document.querySelector("#tweetData > tbody");
function loadData() {
const base_url = "https://bsj0pwvapj.execute-api.us-east-1.amazonaws.com/prod/?keywordSearch=";
const userSearch = document.getElementById("keyword").value;
const API_url = base_url + userSearch;
console.log(API_url);
const request = new XMLHttpRequest();
request.open('GET', API_url , true);
...
}
</script>The const base_url takes the base API url which won’t return anything since it has a NULL value. This is where we extract the search that was submitted and append it to the base_url. To invoke the API_url you must do a request. In my case since I am using a GET method I have “request.open(‘GET’, API_URL, true)”, but if I wanted to do a POST method you would simply replace it with the GET.
const base_url采用基本API网址,因为它具有NULL值,因此不会返回任何内容。 这是我们提取提交的搜索并将其附加到base_url的地方。 要调用API_url,您必须执行一个请求。 就我而言,因为我使用的是GET方法,所以我有“ request.open('GET',API_URL,true)”,但是如果我想执行POST方法,则只需将其替换为GET。
<script type="text/javascript>
...
const request = new XMLHttpRequest();
request.open('GET', API_url , true);
request.onload = function() {
const data = JSON.parse(this.response)
for (var i in data) {
var row = ` <tr>
<td>${data[i].user_name}</td>
<td>${data[i].date_created}</td>
<td>${data[i].tweet_text}</td>
<td>${data[i].retweet_count}</td>
<td>${data[i].favorite_count}</td>
<td>${data[i].sentiment}</>
</tr>`
const table = document.getElementById('tdata')
table.innerHTML += row
}
};
request.send();
}
</script>To wrap up the Javascript code I have to parse the JSON data that is taken from API endpoint, and this is done so within the data const. Now it’s just a matter of iterating through the parsed response by using a for loop and populating the database. After each iteration the “table.innerHTML += row” ensures that the data is added to the table before it begins iterating the next JSON object.
要包装Javascript代码,我必须解析从API端点获取的JSON数据,这是在数据const中完成的。 现在,只需使用for循环并填充数据库来遍历解析的响应即可。 每次迭代后,“ table.innerHTML + =行”确保在开始迭代下一个JSON对象之前将数据添加到表中。
结束语 (Closing Remarks)
I hope you enjoyed my blog post. I am Jose Martinez, recent UMD Graduate (Dec’19) looking to start my career in Data Analytics. If you’d like to check out some more of my work feel free to checkout my Github Website with my resume, Github projects, and the code from this Blog. This is my first blog post so it would be great if you’d leave a comment with some feedback, fill out this Contact form or reach out to me on Twitter or LinkedIn. Stay tuned for my next blog post where I’ll dive into setting up the AWS Lambda script, connecting to the Twitter API, and much more.
希望您喜欢我的博客文章。 我是UMD研究生(19年12月)的Jose Martinez,她希望开始我在数据分析方面的职业。 如果您想查看我的更多作品,请随时使用我的简历,Github项目以及此Blog中的代码来查看我的Github网站 。 这是我的第一篇博文,如果您想发表评论并提供一些反馈,填写此联系表或在Twitter或LinkedIn上与我联系 ,那将是很棒的。 请继续关注我的下一篇博客文章,在该文章中,我将深入探讨如何设置AWS Lambda脚本,连接到Twitter API等。
源代码 (Source Code)
翻译自: https://medium.com/analytics-vidhya/conduct-sentiment-analysis-using-tweets-serverless-a708dab87293
苹果推送服务器推送延迟















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}