





The recent advances in NLP suggest training Language Models mainly either using a causal language modeling objective or denoising autoencoding objectives (for e.g. Masked Language Modeling objective). The framework proceeds with self-supervised pre-training of the model on one of the aforementioned objectives followed by fine-tuning the model on specific downstream objectives. Models like BERT, RoBERTa, XLNet, ALBERT, T5, etc. are trained on such objectives and have achieved the state of the art on the respective benchmarks.
NLP的最新进展建议主要使用因果语言建模目标或去噪自动编码目标(例如,蒙版语言建模目标)来训练语言模型。 该框架将对上述目标之一进行模型的自我监督预训练,然后针对特定的下游目标对模型进行微调。 像BERT , RoBERTa , XLNet , ALBERT , T5等模型都针对此类目标进行了培训,并已在各自的基准上达到了最新水平。
In this paper we are going to discuss a rather unique approach proposed by Google AI for pre-training of language models in the paper, ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. We’ll first glance through the existing pre-training approaches and then discuss ELECTRA’s approach in-depth.
在本文中,我们将讨论Google AI提出的一种非常独特的方法,用于在论文ELECTRA中进行语言模型的预训练:ELECTRA:将文本编码器作为鉴别器而不是生成器进行鉴别 。 我们将首先浏览现有的预培训方法,然后深入讨论ELECTRA的方法。
Note that these models implement the Transformer (Vaswani et. al.) architecture. For more on Transformers, consider giving this article a read.
注意 ,这些模型实现了Transformer( Vaswani et al。 )体系结构。 有关“变形金刚”的更多信息,请考虑阅读本文 。
现有的预培训方法 (Existing Pre-training Approaches)

These approaches can be broadly classified as:
这些方法可以大致分为:
Language Modeling or Causal Language Modeling Objective (left): In this objective, the language model is trained in an autoregressive setting i.e. for a sequence of tokens, we maximize the probability of a token x_t to occur at the ‘t’th position, given all the tokens preceding that token in the sequence. Formally, maximize: P(x_t | x_(i < t)).
语言建模或因果语言建模目标 (左):在此目标中,语言模型是在自回归设置下训练的,即对于一系列标记,我们给出标记x_t在第t个位置出现的概率最大,给定序列中该令牌之前的所有令牌。 正式地,最大化: P(x_t | x_(i <t)) 。
Denoising Autoencoding or vaguely, Masked Language Modeling Objective (right): In this objective, the language model is trained in an autoencoding setting i.e. for a sequence of tokens, we maximize the probability of a token x_t to occur at the ‘t’th position, given all the tokens in the sequence x_hat. Formally, maximize: P(x_t | x_hat).
对自动编码进行降噪或模糊地掩盖语言建模目标 (右):在此目标中,语言模型是在自动编码设置下进行训练的,即对于一系列令牌,我们最大化了令牌x_t在第t个位置出现的概率给定序列x_hat中的所有令牌。 正式地,最大化: P(x_t | x_hat) 。
OpenAI GPT, GPT-2, XLNet are trained on the Language Modeling Objective and BERT, RoBERTa are trained on the Denoising Autoencoding Objective.
OpenAI GPT , GPT-2 , XLNet 接受了语言建模目标 方面的培训 , BERT , RoBERTa 接受了降噪自动编码目标方面的培训。
电子 (ELECTRA)

The ELECTRA paper has proposed a Replaced Token Detection objective wherein instead of masking the inputs and then training the model to predict the correct tokens, we replace the original tokens from the sequence with tokens that are not correct, but they make some sense with the given sequence (for e.g. in the animation above, ‘the’ and ‘cooked’ are replaced by ‘a’ and ‘ate’ which although are incorrect, still make sense), and then train the model to classify if a given token is ‘original’ or ‘replaced’.
ELECTRA论文提出了替换令牌检测目标,其中我们不是掩盖输入然后训练模型以预测正确的令牌, 而是用不正确的令牌替换了序列中的原始令牌 ,但对于给定的令牌来说,它们是有意义的序列(例如,在以上“ 的 ”和“ 熟 ”由“a”和“ 吃 ”,这虽然是不正确的,还有意义代替动画),然后训练模型,如果一个给定的令牌是“ 原始 分类 '或' 替换 '。
The model consists of a Generator and a Discriminator Network as in Generative Adversarial Networks (GANs). On the contrary, the training procedure is NOT adversarial as in GANs. We will glance through a few reasons why ELECTRA is not a GAN later in this article.
该模型由生成对抗网络 (GAN)中的生成 器和鉴别器网络组成。 相反,与GAN相比,训练过程不是 对抗性的 。 我们将在本文后面介绍几种为什么ELECTRA不是GAN的原因。
发电机 (The Generator)
This is essentially a small masked language model. So, the inputs are initially corrupted with [MASK] tokens and then, the generator is trained to predict the correct tokens from the original sequence (or plausible tokens that make sense as discussed earlier).
这本质上是一个小的掩盖语言模型 。 因此,最初使用[MASK]令牌破坏了输入,然后训练了生成器,以根据原始序列(或前面讨论的有意义的合理令牌)预测正确的令牌。
Moreover, the logic behind having a small generator is related to the computational complexity of the model.
此外,具有较小生成器的逻辑背后与模型的计算复杂性有关。
If the generator and discriminator are the same size, training ELECTRA would take around twice as much compute per step as training only with masked language modeling
如果生成器和鉴别器的大小相同,则训练ELECTRA每步所需的计算量大约是仅使用掩盖语言建模进行训练的两倍
— ELECTRA纸
Formally,
正式地
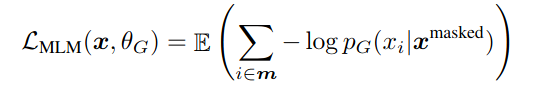
鉴别者 (The Discriminator)
This is essentially a transformer encoder and is trained to maximize the likelihood of classifying a replaced token as ‘replaced’ and a original token as ‘original’.
这本质上是一个变压器编码器,经过培训可以最大程度地将替换标记分类为“ 替换 ”,将原始标记分类为“ 原始 ”。
Formally,
正式地
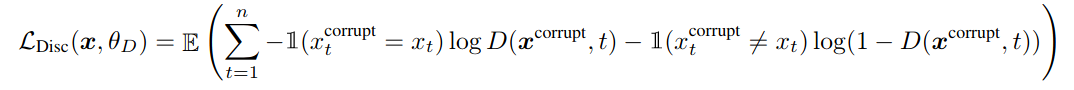
组合模型 (Combined Model)
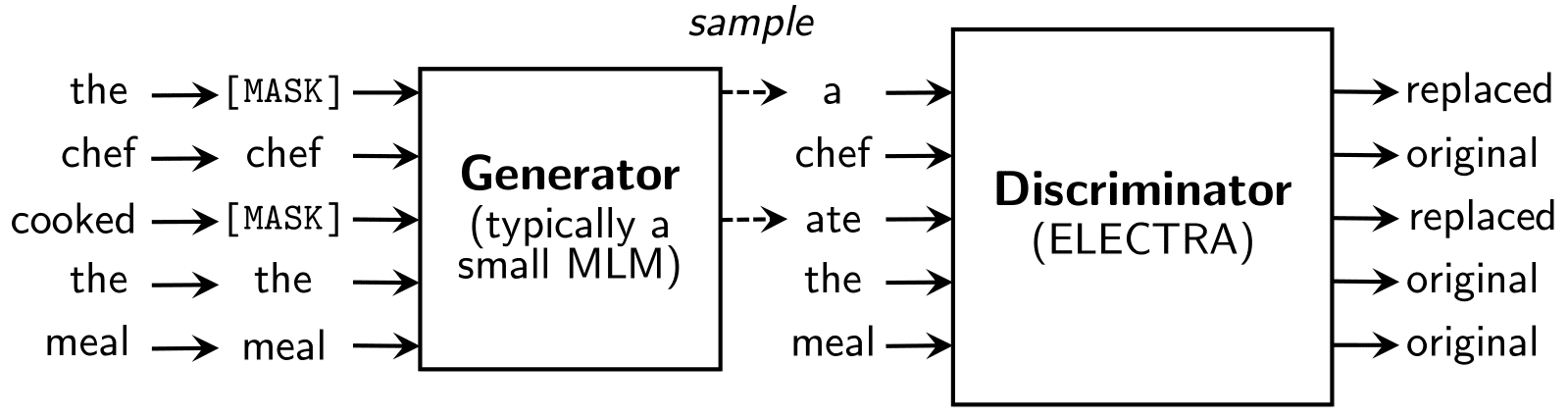
The combined model is pre-trained with both; the generator and the discriminator on the Replaced Token Detection objective.
两者都经过组合模型的预训练; 替换令牌检测目标上的生成器和鉴别器。
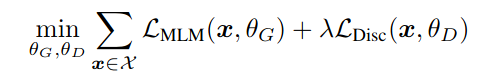
The generator is discarded after the pre-training and the discriminator is used for fine-tuning on downstream tasks.
在预训练之后,将丢弃生成器,并使用鉴别器对下游任务进行微调。
Hence, the Discriminator is ELECTRA.
因此, 鉴别器为ELECTRA。
ELECTRA不是GAN吗? (How is ELECTRA not a GAN?)
Although the model architecture and/or training objective may reminisce GANs, ELECTRA ain’t one! The following are some peculiarities of ELECTRA that contrast to that of GANs’:
尽管模型架构和/或培训目标可能会使GAN令人回味,但ELECTRA却不是一个! 以下是ELECTRA的一些特性与GAN's的对比:
- If the generator happens to generate the correct token, that token is considered “real” instead of “fake”. 如果生成器恰巧生成正确的令牌,则该令牌被视为“真实”而不是“伪造”。
- The generator is trained with maximum likelihood rather than being trained adversarially to trick the discriminator. 训练生成器的可能性最大,而不是通过对抗性的方法欺骗区分器。
- Since we sample tokens as the generator output and feed it to the discriminator, it is impossible to backpropagate the loss through this sampling step, which is a necessity for adversarial training. 由于我们将令牌作为生成器输出进行采样并将其提供给鉴别器,因此不可能通过此采样步骤反向传播损失,这是对抗训练的必要条件。
结论 (Conclusion)
In this article, we covered a new approach for language model pre-training. We also discussed the resemblance of ELECTRA with GANs and how they both differ from each other.
在本文中,我们介绍了一种用于语言模型预训练的新方法。 我们还讨论了ELECTRA与GAN的相似之处以及它们之间的区别。
Here is a link to the GitHub repository for ELECTRA
Here is an API reference to implement ELECTRA using huggingface transformers
这是API的参考资料,用于使用拥抱转换器实现ELECTRA


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









