





Data is now growing faster than processing speeds. One of the many solutions to this problem is to parallelise our computing on large clusters. A language that allows us to do just that is PySpark.
现在,数据的增长速度快于处理速度。 解决此问题的众多解决方案之一是在大型集群上并行化我们的计算。 PySpark是使我们能够做到这一点的一种语言。
However, PySpark requires you to think about data differently.
但是,PySpark要求您以不同的方式考虑数据。
Instead of looking at a dataset row-wise. PySpark encourages you to look at it column-wise. This was a difficult transition for me at first. I’ll tell you the main tricks I learned so you don’t have to waste your time searching for the answers.
而不是逐行查看数据集。 PySpark鼓励您逐列查看。 起初,这对我来说是一个艰难的过渡。 我将告诉您我学到的主要技巧,这样您就不必浪费时间来寻找答案。
数据集 (Dataset)
I’ll be using the Hazardous Air Pollutants dataset from Kaggle.
我将使用Kaggle的有害空气污染物数据集。
This Dataset is 8,097,069 rows.
该数据集是8,097,069行。
df = spark.read.csv(‘epa_hap_daily_summary.csv’,inferSchema=True, header =True)
df.show()
条件If语句 (Conditional If Statement)
The first transformation we’ll do is a conditional if statement transformation. This is as follows: if a cell in our dataset contains a particular string we want to change the cell in another column.
我们将执行的第一个转换是条件if语句转换。 如下所示:如果数据集中的一个单元格包含特定的字符串,我们要更改另一列中的单元格。
Basically we want to go from this:
基本上,我们要从这里开始:

To this:
对此:

If local site name contains the word police then we set the is_police column to 1. Otherwise we set it to 0.
如果local site name包含单词police那么我们将is_police列设置为1 。 否则我们将其设置为0 。
This kind of condition if statement is fairly easy to do in Pandas. We would use pd.np.where or df.apply. In the worst case scenario, we could even iterate through the rows. We can’t do any of that in Pyspark.
这种条件if语句在Pandas中相当容易做到。 我们将使用pd.np.where或df.appl y 。 在最坏的情况下,我们甚至可以遍历各行。 我们不能在Pyspark中做任何事情。
In Pyspark we can use the F.when statement or a UDF. This allows us to achieve the same result as above.
在Pyspark中,我们可以使用F.when语句或UDF . 这使我们可以获得与上述相同的结果。
from pyspark.sql import functions as Fdf = df.withColumn('is_police',\
F.when(\
F.lower(\
F.col('local_site_name')).contains('police'),\
F.lit(1)).\
otherwise(F.lit(0)))df.select('is_police', 'local_site_name').show()
Now suppose we want to extend what we’ve done above. This time if a cell contains any one of 3 strings then we change the corresponding cell in another column.
现在假设我们要扩展上面所做的工作。 这次,如果一个单元格包含3个字符串中的任何一个,则我们在另一列中更改相应的单元格。
If any one of strings: 'Police', 'Fort' , 'Lab' are in the local_site_name column then we'll mark the corresponding cell as High Rating.
如果在local_site_name列中有local_site_name任何一个字符串: 'Police', 'Fort' , 'Lab' ,那么我们会将相应的单元格标记为High Rating 。
Therlike function combined with the F.when function we saw earlier allows to us to do just that.
该rlike功能与合并F.when我们前面看到的功能可以让我们做到这一点。
parameter_list = ['Police', 'Fort' , 'Lab']df = df.withColumn('rating',\
F.when(\
F.col('local_site_name').rlike('|'.join(parameter_list)),\
F.lit('High Rating')).\
otherwise(F.lit('Low Rating')))df.select('rating', 'local_site_name').show()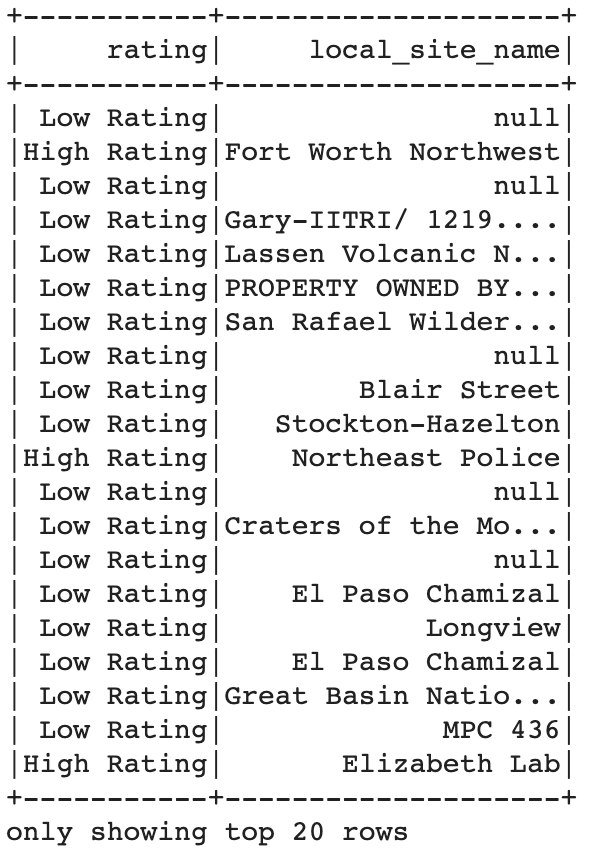
F.when is actually useful for a lot of different things. In fact you can even do a chained F.when:
F.when实际上可用于许多不同的事物。 实际上,您甚至可以在以下情况下执行链式F.when :
df = df.withColumn('rating', F.when(F.lower(F.col('local_site_name')).contains('police'), F.lit('High Rating'))\
.when(F.lower(F.col('local_site_name')).contains('fort'), F.lit('High Rating'))\
.when(F.lower(F.col('local_site_name')).contains('lab'), F.lit('High Rating'))\
.otherwise(F.lit('Low Rating')))df.select('rating', 'local_site_name').show(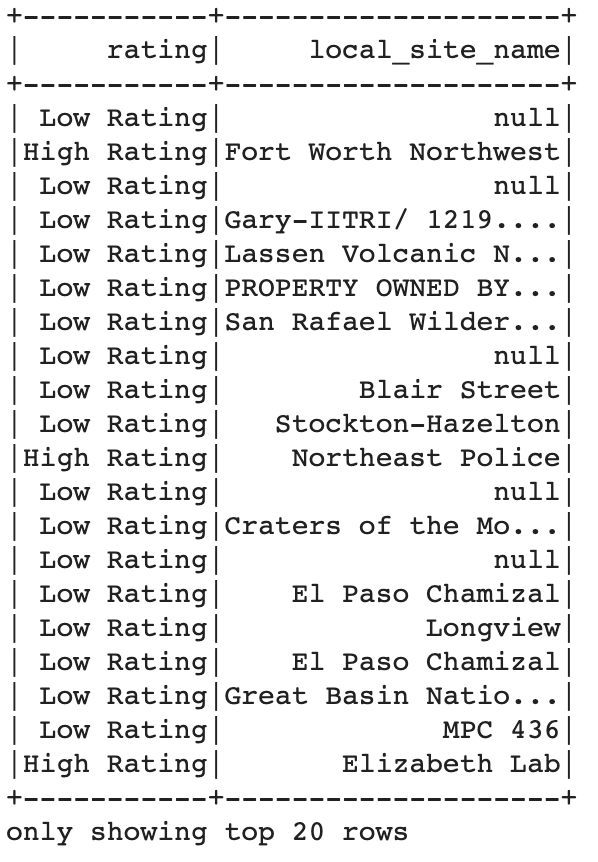
This achieves exactly the same thing we saw in the previous example. However, it’s more code to write and it’s more code to maintain.
这可以实现与上一个示例完全相同的功能。 但是,要编写的代码更多,需要维护的代码也更多。
I prefer the rlike method discussed above.
我更喜欢上面讨论的rlike方法。
删除空格 (Remove whitespace)
Whitespace can be really annoying. It really affects string matches and can cause unnecessary bugs in queries.
空格可能真的很烦人。 它确实会影响字符串匹配,并可能导致查询中不必要的错误。
In my opinion it’s a good idea to remove whitespace as soon as possible.
我认为,最好尽快删除空白。
F.trimallows us to do just that. It will remove all the whitespace for every row in the specified column.
F.trim允许我们这样做。 它将删除指定列中每一行的所有空格。
df = df.withColumn('address', F.trim(F.col('address')))
df.show()
删除特定列的空行 (Remove Null Rows for a Particular Column)
Suppose we want to remove null rows on only one column. If we encounter NaN values in the pollutant_standard column drop that entire row.
假设我们只想删除一列上的空行。 如果我们在pollutant_standard列中遇到NaN值,则将整行删除。
This can accomplished fairly simply.
这可以相当简单地完成。
filtered_data = df.filter((F.col('pollutant_standard').isNotNull())) # filter out nulls
filtered_data.count()The conditional OR parameter allows to remove rows where we event_type or site_num are NaN.
条件OR参数允许删除我们event_type或site_num为NaN.
This is referred to as `|`.
这称为 “ |”。
filtered_data = df.filter((F.col('event_type').isNotNull()) | (F.col('site_num').isNotNull())) # filter out nulls
filtered_data.count()df.na.drop allows us to remove rows where all our columns are NaN.
df.na.drop允许我们删除所有列均为NaN 。
filtered_data = df.na.drop(how = 'all') # filter out nulls
filtered_data.show()结论 (Conclusion)
PySpark is still fairly a new language. Probably as a result of that there isn’t a lot of help on the internet. With something like Pandas or R there’s a wealth of information out there. With Spark that’s not the case at all.
PySpark仍然是一种新语言。 可能是由于这样的结果,互联网上没有太多帮助。 像Pandas或R这样的东西,那里有很多信息。 使用Spark根本不是这样。
So I hope these bits of code help someone out there. They certainly would’ve helped me and saved me a lot of time. The transformations I went through might seem small or trivial but there aren’t a lot of people talking about this stuff when it pertains to Spark. I hope this helps you in some way.
因此,我希望这些代码可以帮助某人。 他们肯定会帮助我,并节省了我很多时间。 我经历的转换看起来很小或微不足道,但是当涉及到Spark时,没有多少人在谈论这些东西。 希望这对您有所帮助。
If I’ve made a mistake or you’d like reach out to me feel free to contact me on twitter.
如果我弄错了,或者你想与我联系,请随时通过Twitter与我联系。
Originally published at https://spiyer99.github.io on September 6, 2020.
最初于 2020年9月6日 发布在 https://spiyer99.github.io 。
翻译自: https://medium.com/@neel.r.iyer/data-transformation-in-pyspark-6a88a6193d92















 963
963

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









