





I will also walk through the OSEMN framework for this machine learning example. The acronym, OSEMN, stands for Obtain, Scrub, Explore, Model, and iNterpret. This is the most common framework for Data Scientists working on machine learning problems.
我还将通过该机器学习示例的OSEMN框架。 首字母缩写词OSEMN代表获取,清理,探索,模型和iNterpret。 这是数据科学家研究机器学习问题的最常见框架。
With out further ado, let’s get started.
事不宜迟,让我们开始吧。
使用Spotify API获取数据 (Obtaining Data Using Spotify API)
First, we use the Spotify API client to obtain our data. If you are not familiar with Spotify API, you will find the CodeEntrepreneur’s 30 Days of Python — Day 19 — The Spotify API — Python TUTORIAL very helpful, especially since the documentation is written in JavaScript. Spotify’s Web API requires a developers account, and the API call requires an authenticated token.
首先,我们使用Spotify API客户端获取数据。 如果您不熟悉Spotify API,您会发现CodeEntrepreneur的Python 30天-第19天 -Spotify API-Python教程非常有用,特别是因为该文档是用JavaScript编写的。 Spotify的Web API需要开发者帐户,并且API调用需要经过身份验证的令牌。
We will use the Get Artist endpoint from Spotify to obtain data for 30 artists originally from Houston, TX. You can download the .xlsx file from my GitHub repository if you would like to use the same artists for the API client.
我们将使用Spotify的“ 获取艺术家”端点来获取30位来自德克萨斯州休斯顿的艺术家的数据。 如果您希望对API客户端使用相同的艺术家,则可以从我的GitHub存储库下载.xlsx文件。
Make sure you set the client id and client secret:
确保设置了客户端ID和客户端密码:
client_id = 'your_client_id'
client_secret = 'your_secret_id'
spotify = SpotifyAPI(client_id, client_secret)In [ ]:spotify.get_artist('35magIA6t9JpNwT0sPEBgM')Out[ ]:{'external_urls': {'spotify': 'https://open.spotify.com/artist/35magIA6t9JpNwT0sPEBgM'},
'followers': {'href': None, 'total': 383},
'genres': ['houston rap'],
'href': 'https://api.spotify.com/v1/artists/35magIA6t9JpNwT0sPEBgM',
'id': '35magIA6t9JpNwT0sPEBgM',
'images': [{'height': 640,
'url': 'https://i.scdn.co/image/ab67616d0000b27326ac896c0d9a0e266c29ec27',
'width': 640},
{'height': 300,
'url': 'https://i.scdn.co/image/ab67616d00001e0226ac896c0d9a0e266c29ec27',
'width': 300},
{'height': 64,
'url': 'https://i.scdn.co/image/ab67616d0000485126ac896c0d9a0e266c29ec27',
'width': 64}],
'name': 'Yb Puerto Rico',
'popularity': 26,
'type': 'artist',
'uri': 'spotify:artist:35magIA6t9JpNwT0sPEBgM'}Since the api response returns a JSON object, we can parse each artists’ data for the information we need. I used a for loop to pull data from each artists adding their results to list. You can also try the Get Several Artists endpoint to get multiple artists in one response.
由于api响应返回一个JSON对象,因此我们可以解析每个艺术家的数据以获取所需的信息。 我使用了for循环从每位歌手中提取数据,并将其结果添加到列表中。 您也可以尝试“ 获取多位艺术家”端点来在一个响应中获得多位艺术家。
Here is my code to load the .csv file and get the artist info from Spotify:
这是我的代码,用于加载.csv文件并从Spotify获取艺术家信息:
# Load .csv with artists and spotifyIDs
import pandas as pdcsv = "Houston_Artists_SpotifyIDs.csv"
df = pd.read_csv(csv)
X = df['Spotify ID']# For loop to collect JSON responses for each artist
json_results = []for i in X:
json_results.append(spotify.get_artist(f'{i}'))从Spotify清除数据 (Scrubbing the Data from Spotify)
Once we have everyone’s information parsed, we no longer require the api client. We can use python check pull the number of followers and the popularity score for each artist stored in our list. We can also check for any duplicates and handle any missing values.
解析完每个人的信息后,我们将不再需要api客户端。 我们可以使用python check pull来存储列表中每个艺术家的关注者数量和受欢迎度得分。 我们还可以检查是否有重复项,并处理任何缺失的值。
Here is my code to parse the JSON info into a Pandas Dataframe:
这是将JSON信息解析为Pandas Dataframe的代码:
In [ ]:names = []
followers = []
popularity = []
genres = []
urls = []
for i in json_results:
names.append(i['name'])
followers.append(i['followers']['total'])
popularity.append(i['popularity'])
genres.append(i['genres'])
urls.append(i['external_urls']['spotify'])
df = pd.DataFrame()
df['names'] = names
df['followers'] = followers
df['popularity'] = popularity
df['genre'] = genres
df['url'] = urls
df.head()Out [ ]: names followers popularity genre url
0 AcePer$ona 15 1 [] https://open.spotify.com/artist/4f06tvRb3HaDFC...
1 AliefBiggie 26 0 [] https://open.spotify.com/artist/1WkWfhdsdSqVYT...
2 Amber Smoke 93 2 [] https://open.spotify.com/artist/2JrntJAExmduLd...
3 Beyoncé 23821006 89 [dance pop, pop, post-teen pop, r&b] https://open.spotify.com/artist/6vWDO969PvNqNY...
4 Chucky Trill 957 25 [houston rap] https://open.spotify.com/artist/2mdDdKL0UzOqSq...探索Spotify中的数据 (Exploring the Data from Spotify)
With our data now in a pandas dataframe, we can begin analyzing our sample artists. By view the data table by followers, we can see two outliers, Beyonce and Travis Scott.
现在我们的数据已存储在熊猫数据框中,我们就可以开始分析样本艺术家了。 通过关注者查看数据表,我们可以看到两个离群值,碧昂丝和特拉维斯·斯科特。
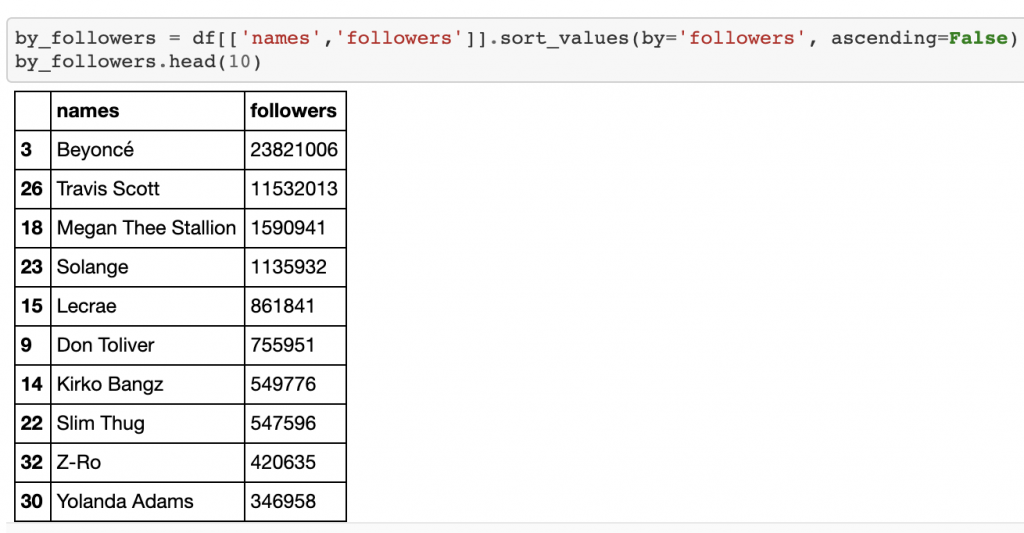
We can also see that these two artists are similar but slightly different. While Beyonce has more followers, Travis Scott trumps Beyonce in Spotify popularity with Travis scoring 96 and Beyonce scoring 89, a whole seven points higher than ‘Queen B’.
我们还可以看到,这两位艺术家相似但略有不同。 尽管碧昂斯拥有更多的追随者,但特拉维斯·斯科特(Travis Scott)在Spotify的流行度上击败了碧昂斯(Beyonce),特拉维斯获得96分,碧昂斯获得89分,比“女王B”高出整整七分。
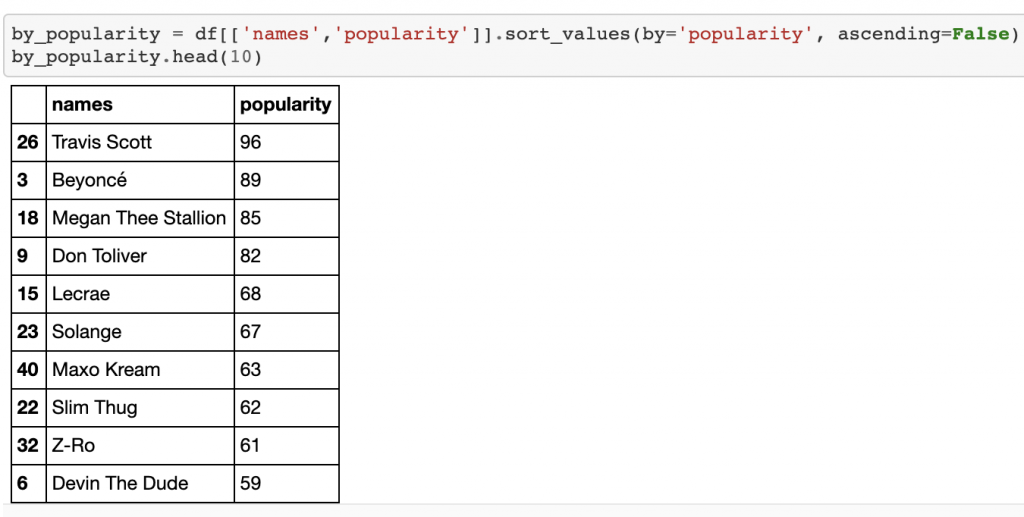
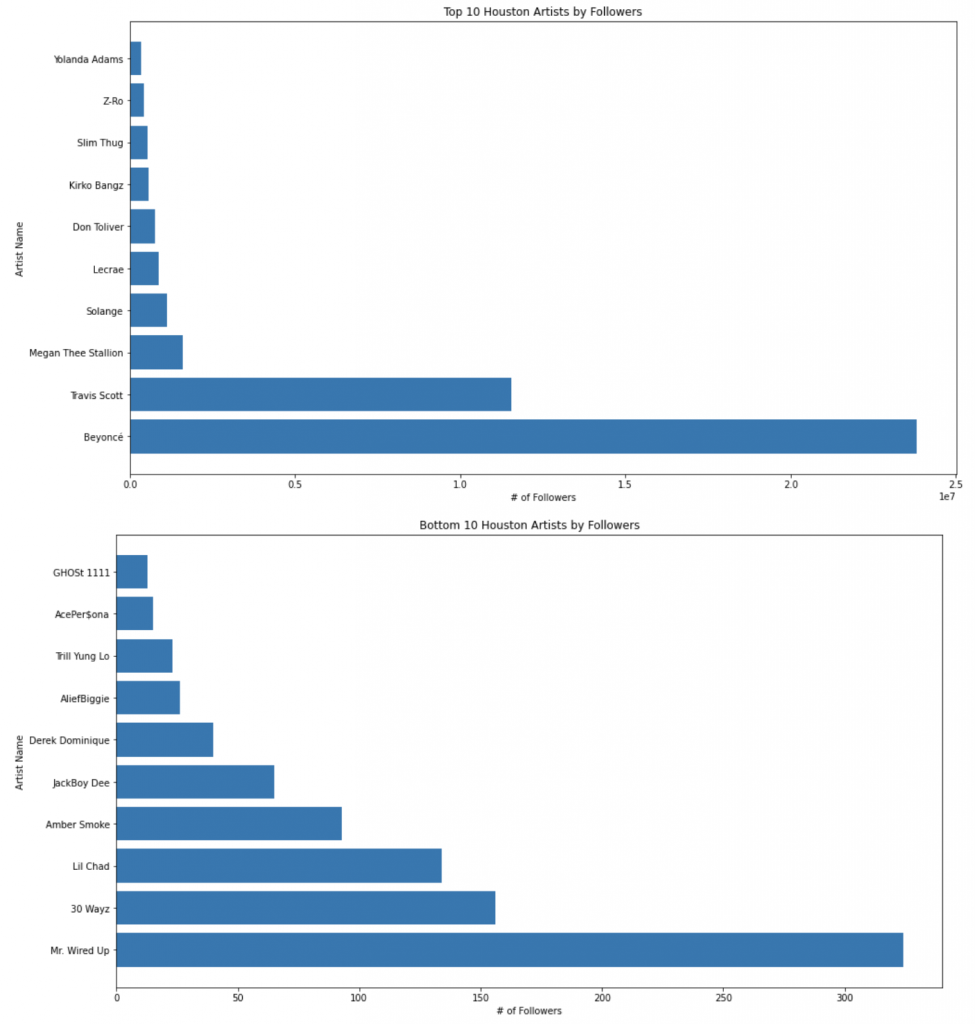
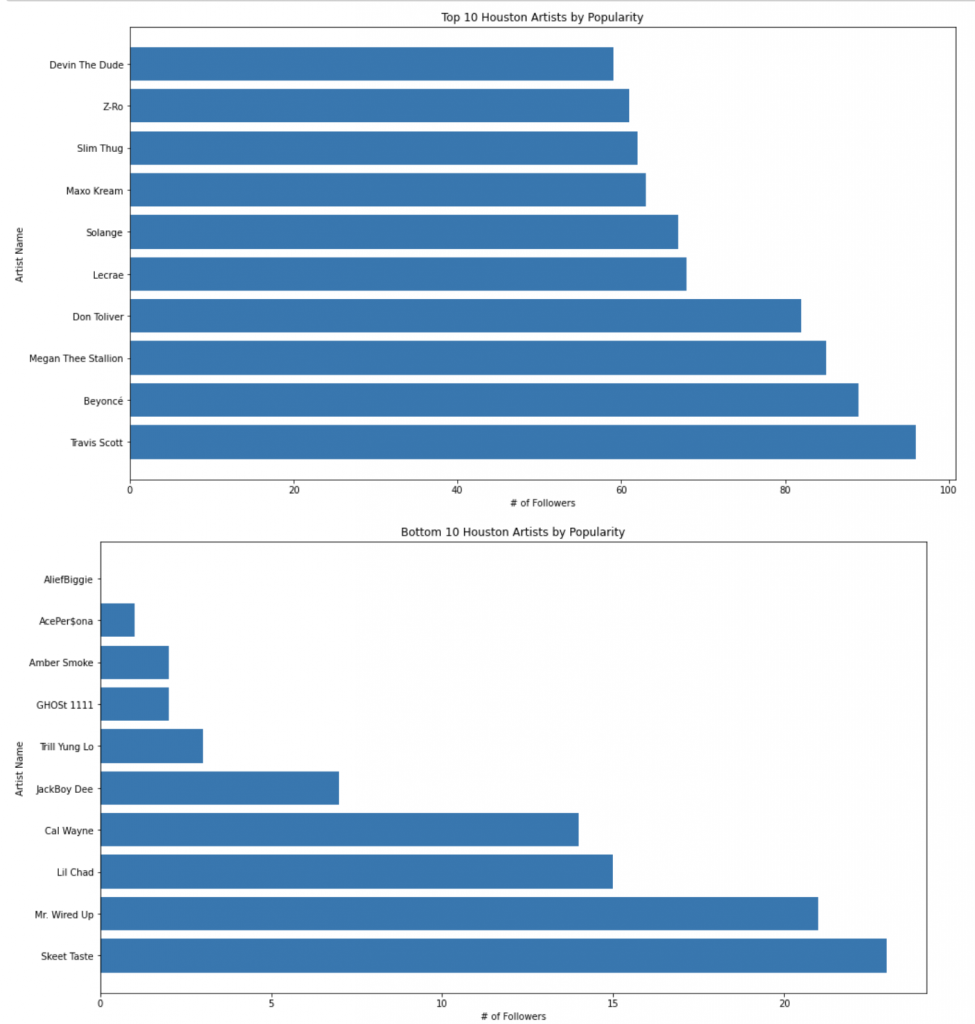
We can also see the top artists by followers and popularity, and on the opposite end of the spectrum, we can see the bottom artists by followers and popularity.
我们还可以按关注者和受欢迎程度查看排名靠前的艺术家,而在频谱的另一端,我们可以按关注者和受欢迎程度查看排名靠后的艺术家。
追随者: (By Followers:)
按受欢迎程度: (By Popularity:)
While this can be helpful to know who is who, and who has what kind of following or popularity, the purpose of this post was to use an unsupervised learning algorithm to compare these artists.
虽然这有助于了解谁是谁,以及谁具有什么样的追随者或受欢迎程度,但本文的目的是使用无监督学习算法来比较这些艺术家。
使用Scikit学习建模数据 (Modeling the Data with Scikit-learn)
“Unsupervised Learning is a type of machine learning algorithm used to draw inferences from datasets consisting of input data without labeled responses. The most common unsupervised learning method is cluster analysis, which is used for exploratory data analysis to find hidden patterns or grouping in data.” — Mathworks
“无监督学习是一种机器学习算法,用于从包含输入数据而没有标记响应的数据集中得出推论。 最常见的无监督学习方法是聚类分析,它用于探索性数据分析,以发现隐藏的模式或数据分组。” — Mathworks
Since we would like to compare these artists, we will use an unsupervised learning algorithm to group/cluster our artists together. To be more specific, will use Scikit-Learn’s KMeans algorithm for this example. Let’s import the module from sklearn. You can follow the instructions here to install sklearn.
由于我们想比较这些艺术家,因此我们将使用无监督学习算法将我们的艺术家分组/聚类。 更具体地说,在此示例中,将使用Scikit-Learn的KMeans算法。 让我们从sklearn导入模块。 您可以按照此处的说明安装sklearn 。
from sklearn.cluster import KMeansThe
KMeansalgorithm clusters data by trying to separate samples in n groups of equal variance, minimizing a criterion known as the inertia or within-cluster sum-of-squares.的
KMeans通过尝试不同的样品中的n个组等于方差,最小化被称为惯性或内簇求和的平方 的标准算法簇的数据 。Scikit-Learn.org
Scikit-Learn.org
缩放功能 (Scaling the Features)
It’s always a best practice to scale your features before training any machine learning algorithm. It’s also great practice to handle your outliers. In this example, I will keep our outliers in and used a MinMaxScaler to scale the features in our small dataset, but we could also use the RobustScaler to scale features using statistics that are robust to outliers.
在训练任何机器学习算法之前,扩展功能始终是最佳实践。 处理异常值也是一种很好的做法。 在此示例中,我将保留离群值,并使用MinMaxScaler缩放小型数据集中的要素 ,但我们也可以使用RobustScaler通过对离群值具有鲁棒性的统计来缩放要素 。
from sklearn.preprocessing import MinMaxScaler
s = MinMaxScaler()
Scaled_X = s.fit_transform(X)训练模型 (Training the Model)
Now that we have scaled and transformed our features, we can train our KMeans algorithm. We are required to set a number of clusters, and there are several methods to help select the best number of clusters, but for our example, we will use 8 clusters. We will use the predict method to predict the group or cluster for each artists based on their followers and popularity.
现在我们已经缩放和变换了功能,我们可以训练KMeans算法。 我们需要设置多个群集,并且有多种方法可以帮助选择最佳群集数量,但是在我们的示例中,我们将使用8个群集。 我们将使用预测方法根据每个艺术家的关注者和受欢迎程度来预测其分组或聚类。
kmeans = KMeans(n_clusters=8, random_state=0).fit(Scaled_X)
y_kmeans = kmeans.predict(X)查看集群 (Viewing the Clusters)
To view the clusters, we can pull the labels from our Kmeans model by using the method, .labels_. We can also view the centers of the clusters by using the method, .cluster_centers_.
要查看群集,可以使用.labels_方法从Kmeans模型中提取标签。 我们还可以使用.cluster_centers_方法查看群集的中心。
df['labels'] = kmeans.labels_
centers = kmeans.cluster_centers_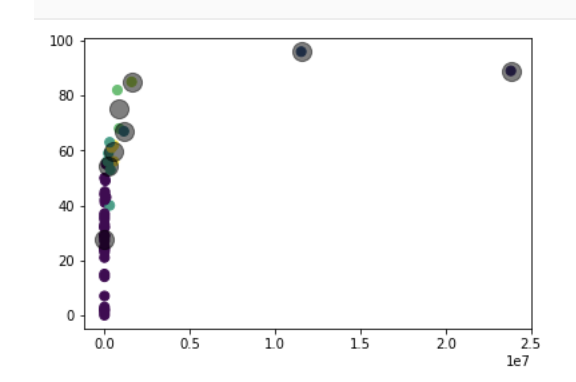
Image by Jacob Tadesse
图片提供者:Jacob Tadesse
While we could plot these in a notebook, I’ll use Tableau Public to create a dashboard for public access. Let’s save our dataframe as an Excel file.
虽然我们可以在笔记本中绘制这些图形,但我将使用Tableau Public创建仪表板以供公共访问。 让我们将数据框保存为Excel文件。
保存结果 (Saving the Results)
Below, we will filter our dataframe to only include the artist name, followers, popularity, and labels. Then we will sort the data by the label value.
在下面,我们将过滤数据框,使其仅包含艺术家姓名,关注者,受欢迎程度和标签。 然后,我们将根据标签值对数据进行排序。
final = df[['names','followers','popularity','labels']].sort_values(by='labels', ascending=False)Finally, we will use the built-in Pandas method, .to_excel, to save the file.
最后,我们将使用内置的Pandas方法.to_excel来保存文件。
final.to_excel('Houston_Artists_Categories_8-7-2020.xlsx')从Kmeans解释聚类 (Interpreting Clusters from Kmeans)
I used Tableau Public (it’s FREE) to create an interactive dashboard of the results. With Artist grouped by cluster, we can see Beyonce and Travis Scott are in their own clusters, while other Houston artists are grouped together by similar followers and popularity. Thank you for reading this article, I hope you found it helpful in comparing Houston Artists using unsupervised learning!
我使用Tableau Public (免费)创建了结果的交互式仪表板。 通过按分组对艺术家进行分组,我们可以看到碧昂斯和特拉维斯·斯科特在各自的分组中,而其他休斯敦艺术家则按相似的追随者和受欢迎程度分组。 感谢您阅读本文,希望对使用无监督学习的休斯顿艺术家进行比较有帮助!
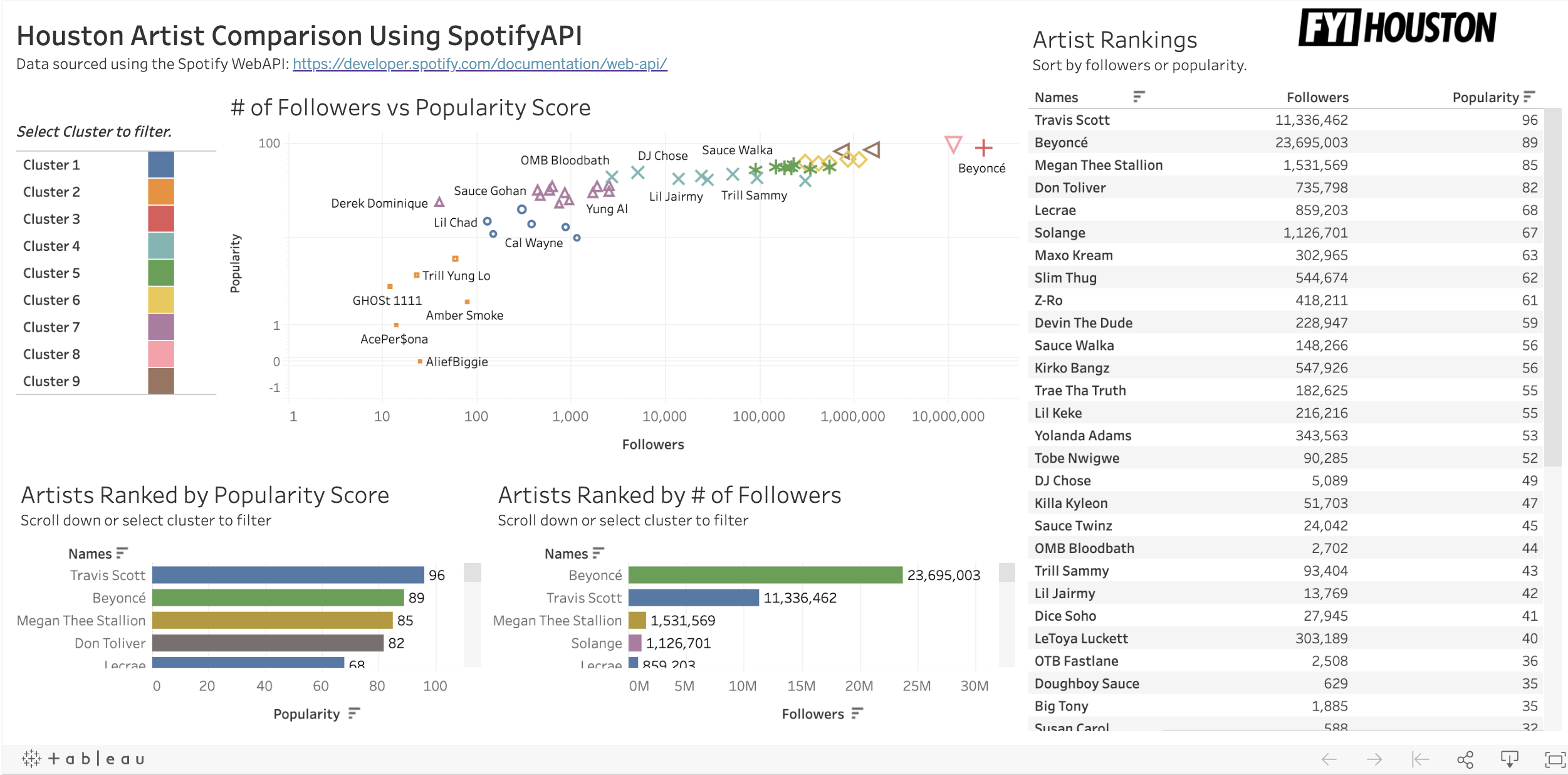
Here is the link to the dashboard.
这是仪表板的链接。
Also, here is a link to the repo.
另外,这是到repo的链接。
If you would like to contribute to this project, contact me on LindedIn.
如果您想为这个项目做贡献,请通过LindedIn与我联系。















 446
446

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









