





算法竞赛训练指南代码仓库
重点 (Top highlight)
As a data scientist, it’s valuable to have some idea of fundamental data warehouse concepts. Most of the work we do involves adding enterprise value on top of datasets that need to be clean and readily comprehensible. For a dataset to reach that stage of its lifecycle, it has already passed through many components of data architecture and, hopefully, many data quality filters. This is how we avoid the unfortunate situation wherein the data scientist ends up spending 80% of their time on data wrangling.
作为数据科学家,了解基本数据仓库概念非常有价值。 我们所做的大部分工作都涉及在需要整洁且易于理解的数据集之上增加企业价值。 为了使数据集达到其生命周期的这一阶段,它已经通过了数据体系结构的许多组件,并希望通过许多数据质量过滤器。 这样,我们就避免了不幸的情况,在这种情况下,数据科学家最终将80%的时间都花在了数据整理上。
Let’s take a moment to deepen our appreciation of the data architecture process by learning about various considerations relevant to setting up a data warehouse.
让我们花一点时间,通过学习与建立数据仓库有关的各种注意事项,加深对数据体系结构过程的认识。
The data warehouse is a specific infrastructure element that provides down-the-line users, including data analysts and data scientists, access to data that has been shaped to conform to business rules and is stored in an easy-to-query format.
的 数据仓库 是一个特定的基础架构元素,它为包括数据分析师和数据科学家在内的下层用户提供对已成形为符合业务规则并以易于查询的格式存储的数据的访问权限。
The data warehouse typically connects information from multiple “source-of-truth” transactional databases, which may exist within individual business units. In contrast to information stored in a transactional database, the contents of a data warehouse are reformatted for speed and ease of querying.
数据仓库通常连接来自多个“真相”交易数据库的信息,这些数据库可能存在于各个业务部门中。 与存储在事务数据库中的信息相反,数据仓库的内容经过重新格式化,以提高查询速度和查询难度。
The data must conform to specific business rules that validate quality. Then it is stored in a denormalized structure — that means storing together pieces of information that will likely be queried together. This serves to increase performance by decreasing the complexity of queries required to get data out of the warehouse (i.e., by reducing the number of data joins).
数据必须符合验证质量的特定业务规则。 然后,将其存储在非规范化结构中-这意味着将可能会被一起查询的信息存储在一起。 这可通过降低将数据移出仓库所需的查询的复杂性(即通过减少数据联接的数量)来提高性能。
In this guide:
在本指南中:
架构数据仓库 (Architecting the Data Warehouse)
In the process of developing the dimension model for the data warehouse, the design will typically pass through three stages: (1) business model, which generalizes the data based on business requirements, (2) logical model, which sets the column types, and (3) physical model, which represents the actual design blueprint of the relational data warehouse.
在开发尺寸模型的过程中 对于数据仓库,设计通常将经历三个阶段:(1)业务模型,该模型根据业务需求对数据进行概括;(2)逻辑模型,用于设置列类型;以及(3)物理模型,用于表示关系数据仓库的实际设计蓝图。
Because the data warehouse will contain information from across all aspects of the business, stakeholders must agree in advance to the grain (i.e. level of granularity) of the data that will be stored.
由于数据仓库将包含来自全国各地业务的各个方面的信息,利益相关者必须提前向同意粮食将被存储的数据(粒度即水平)。
Reminder to validate the model across various stakeholder groups before implementation.
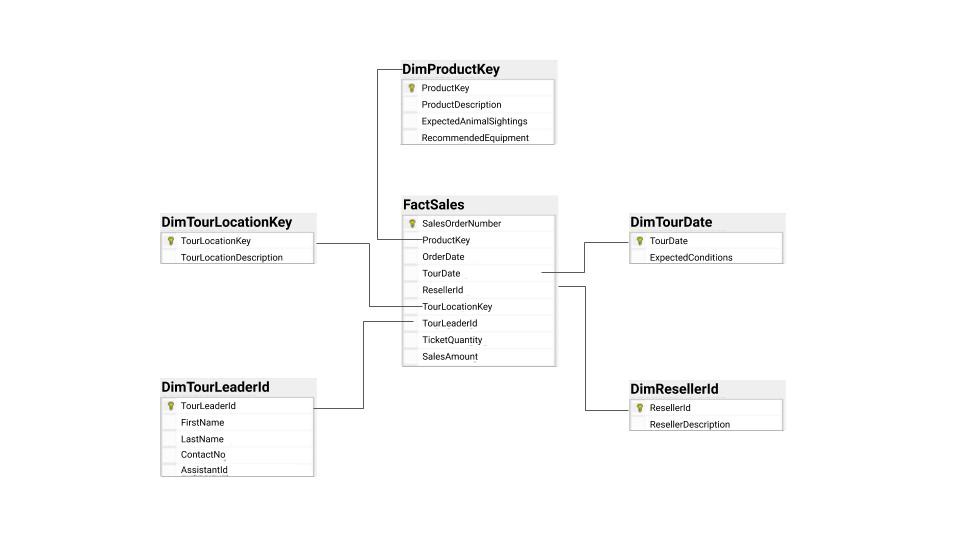
The underlying structure in the data warehouse is commonly referred to as the star schema — it classifies information as either a dimension or fact (i.e., measure). The fact table stores observations or events (i.e. sales, orders, stock balances, etc.) The dimension tables contain descriptive information about those facts (i.e. dates, locations, etc.)
数据仓库中的基础结构通常称为星型模式 -将信息分类为维或事实(即度量)。 事实表存储观察或事件(即销售,订单,库存余额等)。 维度表包含有关这些事实的描述性信息(即日期,位置等)。
There are three different types of fact tables: (1) transactional for records at the standardized grain, (2) periodic for records that fall within a given time frame, (3) cumulative for records that fall within a given business process.
事实表有三种不同类型:(1)标准化记录的事务性记录;(2)属于给定时间范围的记录是周期性的;(3)属于给定业务流程的记录是累积的。
In addition to the star schema, there’s also the option to arrange data into the snowflake schema. The difference here is that each dimension is normalized.
除了星型模式外,还可以选择将数据排列到雪花模式中 。 此处的区别在于每个维度均已标准化。
Normalization is a database design technique for creating records that contain an atomic level of information.
规范化是一种数据库设计技术,用于创建包含原子级别信息的记录。
However, the snowflake schema adds unnecessary complexity to the dimension model — usually the star schema will suffice.
但是,雪花模式会给维模型增加不必要的复杂性-通常星型就足够了。
增强性能并调整尺寸 (Enhancing Performance and Adjusting for Size)
In addition to understanding how to structure the data, the person designing the data warehouse should also be familiar with how to improve performance.
除了了解如何构造数据之外,设计数据仓库的人员还应该熟悉如何提高性能。
One performance-enhancing technique is to create a clustered index on the data in the order it is typically queried. So for example, we might choose to organize the fact table by TourDate descending, so the tours that are coming up next will be shown first in the table. Setting up a clustered index reorders the way the records are physically stored, promoting speed of retrieval. In addition to an optional, single clustered index, a table can also have multiple non-clustered indices that won’t impact how the table is physically stored, but rather create additional copies in memory.
一种性能增强技术是按照通常被查询的顺序在数据上创建聚簇索引 。 因此,例如,我们可能选择按TourDate降序组织事实表,因此接下来要显示的游览将首先显示在表中。 设置聚簇索引将对记录的物理存储方式进行重新排序,从而提高了检索速度。 除了可选的单个聚集索引之外,一个表还可以具有多个非聚集索引,这些索引不会影响表的物理存储方式,而是会在内存中创建其他副本。
Another performance enhancement involves splitting up very large tables into multiple smaller parts. This is called partitioning. By splitting a large table into smaller, individual tables, queries that need access to only a fraction of the data can run faster. Partitioning can be either vertical (splitting up columns) or horizontal (splitting up rows). Here’s a link where you can download an .rtf file containing partitioning script for SQL along with other database architecture resources like a project launch and management checklist.
另一个性能增强涉及将非常大的表拆分为多个较小的部分。 这称为分区 。 通过将大表拆分为较小的单个表,只需要访问一部分数据的查询可以运行得更快。 分区可以是垂直的(拆分列)或水平的(拆分行)。 这是一个链接 ,您可以在其中下载.rtf文件,其中包含SQL 分区脚本以及其他数据库体系结构资源,例如项目启动和管理清单 。

Taking total database size into account is another a crucial component of tuning performance. Estimating the size of the resulting database when designing a data warehouse will help align performance with application requirements according to service level agreement (SLA). Moreover, it will provide insight into the budgeted demand for physical disk space or cost of cloud storage.
考虑数据库的总大小是调优性能的另一个关键组成部分。 在设计数据仓库时,估计结果数据库的大小将有助于根据服务水平协议(SLA)使性能与应用程序要求保持一致。 此外,它将提供对物理磁盘空间或云存储成本的预算需求的洞察力。
To conduct this calculation, simply aggregate the size of each table, which depends largely on the indexes. If database size is significantly larger than expected, you may need to normalize aspects of the database. Conversely, if your database ends up smaller, you can get away with more denormalization, which will increase query performance.
要进行此计算,只需汇总每个表的大小,这在很大程度上取决于索引 。 如果数据库大小明显大于预期,则可能需要规范化数据库的各个方面。 相反,如果数据库最终变小,则可以避免更多的非规范化,这将提高查询性能。
相关数据存储选项 (Related Data Storage Options)
The data in a data warehouse can be reorganized into smaller databases to suit the needs of the organization. For example, a business unit might create a data mart, with information specific to their department. This read-only info source provides clarity and accessibility for business users who might be a little further from the technical details of data architecture. Here’s a planning strategy to deploy when creating a data mart.
可以将数据仓库中的数据重组为较小的数据库,以满足组织的需求。 例如,一个业务部门可能创建一个数据集市 ,其中包含其部门特定的信息。 该只读信息源为业务用户提供了清晰性和可访问性,他们可能与数据体系结构的技术细节有些距离。 这是创建数据集市时要部署的计划策略 。
Similarly, an operational data store (ODS) can be set up for operational reporting. The Master Data Management (MDM) system stores information about unique business assets (i.e., customers, suppliers, employees, products, etc.)
同样,可以为运营报告设置运营数据存储(ODS) 。 主数据管理(MDM)系统存储有关独特业务资产(即客户,供应商,员工,产品等)的信息。
Read about the risks of overutilizing data visualization tools for business intelligence.
处理大数据 (Working with Big Data)
To handle big data, a data architect might chose to implement a tool such as Apache Hadoop. Hadoop was based on the MapReduce technique developed by Google to index the world wide web and was released to the public in 2006. In contrast to the highly structured environment of the data warehouse, where information has already been validated upstream to conform to business rules, Hadoop is a software library that accepts a variety of data types and allows for distributed processing across clusters of computers. Hadoop is often used to process streaming data.
为了处理大数据,数据架构师可能选择实现诸如Apache Hadoop之类的工具。 Hadoop基于Google开发的MapReduce技术来索引万维网,并于2006年向公众发布。与高度结构化的数据仓库环境相反,在数据仓库中,信息已经在上游进行了验证,可以符合业务规则, Hadoop是一个软件库,它接受各种数据类型,并允许跨计算机集群进行分布式处理。 Hadoop通常用于处理流数据。
While Hadoop is able to quickly process streaming data, it struggles with query speed, complexity of queries, security, and orchestration. In recent years, Hadoop has been falling out of favor as cloud-based solutions (e.g., Amazon Kinesis) have risen to prominence — offering the same gains in terms of speed for processing unstructured data while integrating with other tools in the cloud ecosystem that address these potential weaknesses.
尽管Hadoop能够快速处理流数据,但它在查询速度,查询复杂性,安全性和编排方面遇到了困难。 近年来,随着基于云的解决方案(例如Amazon Kinesis )的兴起,Hadoop不再受到青睐-在处理非结构化数据的速度方面与在解决方案中与云生态系统中其他解决方案集成在一起的速度方面,收益相同这些潜在的弱点。
Read more about how to approach the implementation of “new” database technologies.
提取,转换,加载(ETL) (Extract, Transform, Load (ETL))
Extraction, transformation, and load define the process of moving the data out of its original location (E), doing some form of transformation (T), then loading it (L) into the data warehouse. Rather than approach the ETL pipeline in an ad hoc, piecemeal fashion, database architect should look to implement a systematic approach that takes into account best practices around design considerations, operational issues, failure points, and recovery methods. See also this helpful resource for setting up an ETL pipeline.
提取 , 转换和加载定义了以下过程:将数据移出其原始位置(E),进行某种形式的转换(T),然后将其加载(L)到数据仓库中。 数据库架构师应该采取一种系统的方法 ,该方法考虑设计方面的考虑,操作问题,故障点和恢复方法方面的最佳做法,而不是临时地,零散地处理ETL管道。 另请参阅此有用的资源来建立ETL管道 。
Documentation for ETL includes creating source-to-target mapping: the set of transformation instructions on how to convert the structure and content of data in the source system to the structure and content of the target system. Here’s a sample template for this step.
ETL的文档包括创建源到目标的映射:一组有关如何将源系统中数据的结构和内容转换为目标系统的结构和内容的转换说明。 这是此步骤的示例模板 。
Your organization might also consider ELT — loading the data without any transformations, then using the power of the destination system (usually a cloud-based tool) to conduct the transform step.
您的组织还可能考虑使用ELT-在不进行任何转换的情况下加载数据,然后使用目标系统(通常是基于云的工具)的强大功能来执行转换步骤。
将数据移出仓库 (Getting Data Out of the Warehouse)
Once the data warehouse is set up, users should be able to easily query data out of the system. A little education might be required to optimize queries, focusing on:
一旦建立了数据仓库,用户就应该能够轻松地从系统中查询数据。 可能需要一些教育以优化查询,重点在于:
资料封存 (Data Archiving)

Finally, let’s talk about optimizing your organization’s data archiving strategy. Archived data remains important to the organization and is of particular interest to data scientists looking to conduct regression using historical trends.
最后,让我们谈谈优化组织的数据归档 战略。 归档数据对组织仍然很重要,并且对于希望利用历史趋势进行回归的数据科学家特别感兴趣。
The data architect should plan for this demand by relocating historical data that is no longer actively used into a separate storage system with higher latency but also robust search capabilities. Moving the data to a less costly storage tier is an obvious benefit of this process. The organization can also gain from removing write access from the archived data, protecting it from modification.
数据架构师应通过将不再有效使用的历史数据重新定位到具有更高延迟但还具有强大搜索功能的单独存储系统中,来规划此需求。 将数据移动到成本较低的存储层是此过程的明显好处。 该组织还可以从删除存档数据的写访问权限中受益,从而保护其免受修改。
摘要 (Summary)
This article covers tried and true practices for setting up a data warehouse. Let me know how you’re using this information in your work by dropping a comment.
本文介绍了建立数据仓库的可靠实践。 通过添加评论,让我知道您在工作中如何使用此信息。

If you found this article helpful, follow me on Medium, LinkedIn, and Twitter for more ideas to advance your data science skills.
如果您认为本文很有帮助 ,请在Medium , LinkedIn和Twitter上关注我,以获取更多提高您的数据科学技能的想法。
翻译自: https://towardsdatascience.com/data-warehouse-68ec63eecf78
算法竞赛训练指南代码仓库














 6122
6122











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









