





需求分析与建模最佳实践
主题建模的实际使用 (Practical use of topic modeling)
There is a substantial amount of data generated on the internet every second — posts, comments, photos, and videos. These different data types mean that there is a lot of ground to cover, so let’s focus on one — text.
互联网每秒产生大量数据-帖子,评论,照片和视频。 这些不同的数据类型意味着有很多基础,所以让我们集中讨论一个文本。
All social conversations are based on written words — tweets, Facebook posts, comments, online reviews, and so on. Being a social media marketer, a Facebook group/profile moderator, or trying to promote your business on social media requires you to know how your audience reacts to the content you are uploading. One way is to read it all, mark hateful comments, divide them into similar topic groups, calculate statistics and… lose a big chunk of your time just to see that there are thousands of new comments to add to your calculations. Fortunately, there is another solution to this problem — machine learning. From this text you will learn:
所有社交对话均基于书面文字-推文,Facebook帖子,评论,在线评论等。 作为社交媒体营销商,Facebook组/个人资料主持人,或尝试在社交媒体上推广您的业务,您需要了解受众对上传内容的React。 一种方法是全部阅读,标记可恨的评论,将它们分为相似的主题组,计算统计信息,以及……浪费大量时间,只是要看到有成千上万的新评论要添加到计算中。 幸运的是,该问题还有另一种解决方案- 机器学习 。 通过本文,您将学到:
- Why do you need specialised tools for social media analyses? 为什么需要用于社交媒体分析的专用工具?
- What can you get from topic modeling and how it is done? 您可以从主题建模中获得什么以及如何完成?
- How to automatically look for hate speech in comments? 如何自动在评论中寻找仇恨言论?
社交媒体文本为何独特? (Why are social media texts unique?)
Before jumping to the analyses, it is really important to understand why social media texts are so unique:
在进行分析之前,了解社交媒体文本为何如此独特非常重要:
- Posts and comments are short. They mostly contain one simple sentence or even single word or expression. This gives us a limited amount of information to obtain just from one post. 帖子和评论很简短。 它们主要包含一个简单的句子,甚至单个单词或表达。 这使我们仅从一个帖子中获得的信息量有限。

- Emojis and smiley faces — used almost exclusively on social media. They give additional details about the author’s emotions and context. 表情符号和笑脸-几乎仅在社交媒体上使用。 他们提供了有关作者的情感和背景的其他详细信息。

- Slang phrases which make posts resemble spoken language rather than written. It makes statements appear more casual. 使帖子成语的语类似于口语而不是书面语。 它使语句显得更随意。

These features make social media a whole different source of information and demand special attention while running an analysis using machine learning. In contrast, most open-source machine learning solutions are based on long, formal text, like Wikipedia articles and other website posts. As a result, these models perform badly on social media data, because they don’t understand additional forms of expression included. This problem is called domain shift and is a typical NLP problem. Different data also require customised data preparation methods called preprocessing. The step consists of cleaning text from invaluable tokens like URLs or mentions and conversion to machine readable format (more about how we do it in Sotrender). This is why it is crucial to use tools created especially for your data source to get the best results.
这些功能使社交媒体成为完全不同的信息来源,并且在使用机器学习进行分析时需要特别注意。 相反,大多数开源机器学习解决方案都是基于较长的正式文本,例如Wikipedia文章和其他网站帖子。 结果,这些模型在社交媒体数据上的表现不佳,因为它们不理解包含的其他表达形式。 此问题称为域移位,是典型的NLP问题。 不同的数据还需要定制的数据准备方法,称为预处理。 该步骤包括从宝贵的令牌(如URL或提及)中清除文本,然后转换为机器可读格式(更多有关我们在Sotrender中的操作方式 )。 这就是为什么使用专门为您的数据源创建的工具以获得最佳结果至关重要 。
社交媒体的主题建模 (Topic Modeling for social media)
Machine learning for text analysis (Natural Language Processing) is a vast field with lots of different model types that can gain insight into your data. One of the areas that can answer the question “what are the topics of given pieces of texts?” is topic modeling. These models help with understanding what people are talking about in general. It does not require any specially prepared data set with predefined topics. It can find topics which are patterns hidden within the data on its own without supervision and help — which makes it an unsupervised machine learning method. This means that it is easy to build a model for each individual problem.
文本分析的机器学习( 自然语言处理 )是一个广阔的领域,具有许多不同的模型类型,可以深入了解您的数据。 可以回答以下问题之一:“给定文本的主题是什么?” 是主题建模 。 这些模型有助于理解人们在谈论什么。 它不需要任何带有预定义主题的特殊准备的数据集。 它可以自行查找隐藏在数据中的模式主题,而无需监督和帮助-这使其成为无监督的机器学习方法。 这意味着很容易为每个单独的问题建立模型 。
There are lots of different algorithms that can be used for this task, but the most common and widely used is LDA (Latent Dirichlet Allocation). It’s based on word frequencies and topics distribution in texts. To put it simply, this method counts words in a given data set and groups them based on their co-occurrence into topics. Then the percentage distribution of topics in each document is calculated. As a result this method assumes that each text is a mixture of topics which works great with long documents where every paragraph relates to a different matter.
有许多不同的算法可用于此任务,但是最常见且使用最广泛的算法是LDA(潜在狄利克雷分配)。 它基于单词频率和主题在文本中的分布。 简而言之,该方法对给定数据集中的单词进行计数,并根据它们的同时出现将它们分组为主题。 然后计算每个文档中主题的百分比分布。 结果,该方法假定每个文本都是主题的混合体,这对于较长的文档(每个段落涉及一个不同的问题)非常有用。
That’s why social media texts need a different procedure. One of the new algorithms is GSDMM (Gibbs sampling algorithm for a Dirichlet Mixture Model). What makes this one so different?:
这就是为什么社交媒体文本需要不同的程序的原因 。 新算法之一是GSDMM (狄利克雷混合模型的吉布斯采样算法)。 是什么让这个如此与众不同?:
- It is fast, 很快
- designed for short texts, 专为短文本而设计
- easily explained with an analogy of a teacher (algorithm) that wants to divide students (texts) into groups (topics) of similar interests. 很容易用一个老师(算法)的类比来解释,该老师想将学生(文本)划分为兴趣相似的组(主题)。
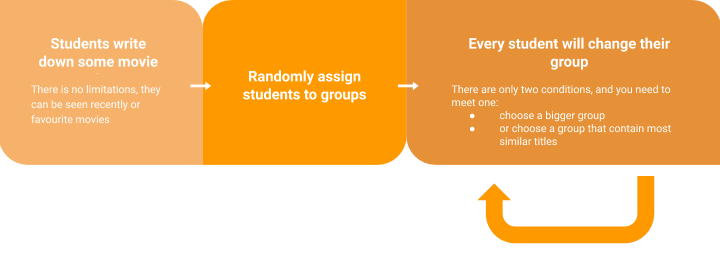
Students are told to write down some movie titles they liked within 2 minutes. Most students are able to list 3–5 movies with this time frame (it corresponds to a limited number of words for social media texts). Then they are randomly assigned to a group. The last step is for every student to pick a different table with two rules in mind:
要求学生在2分钟内写下他们喜欢的电影标题。 大多数学生可以在此时间范围内列出3-5部电影(对应于社交媒体文字的单词数量有限)。 然后将它们随机分配到一个组。 最后一步是让每个学生在选择不同表时要牢记两个规则:
- pick a group with more students — favours bigger groups 选择一个有更多学生的团体-偏爱更大的团体
- or a group with the most similar movie titles — makes groups more cohesive. 或电影标题最相似的小组-使小组更具凝聚力。
This last step is repeated multiple times. First rule that favours bigger groups is crucial to ensure that groups are not excessively fragmented. Due to the limited number of movie titles (words) for each student (text), each group (topic) is bound to have members with different movies in their lists but from the same genre.
最后一步重复多次。 有利于更大群体的第一条规则对于确保群体不会过于分散至关重要。 由于每个学生(文本)的电影标题(单词)数量有限,因此每个组(主题)都必须在列表中具有不同电影但来自同一流派的成员。
As A result of the GSDMM algorithm you obtain an assignment of each text to one topic, as well as a list of the most important words for every topic.
作为GSDMM算法的结果,您可以将每个文本分配给一个主题,并获得每个主题最重要的单词的列表。
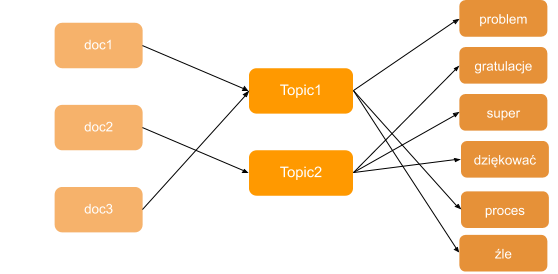
The tricky part is to decide upon number of topic (problem of every unsupervised method) but when you finally do this you can gain quite of a lot of insights from the data:
棘手的部分是确定主题的数量(每个无监督方法的问题),但是当您最终这样做时,您可以从数据中获得很多洞见:
- Distribution of topics in your data 数据中主题的分布
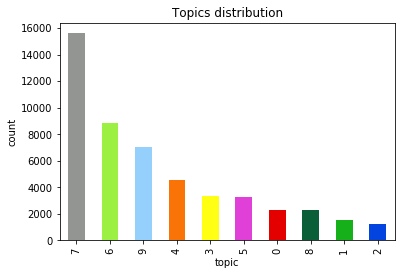
- Word Clouds — allows us to comprehend the topic and name it. It is a quick and easy solution that can replace reading the whole set of text and spare you hours of tedious work of dividing it into sets. 词云-使我们能够理解主题并为其命名。 这是一种快速简便的解决方案,可以代替阅读整个文本集,并且省去了将其分成几组的繁琐工作。

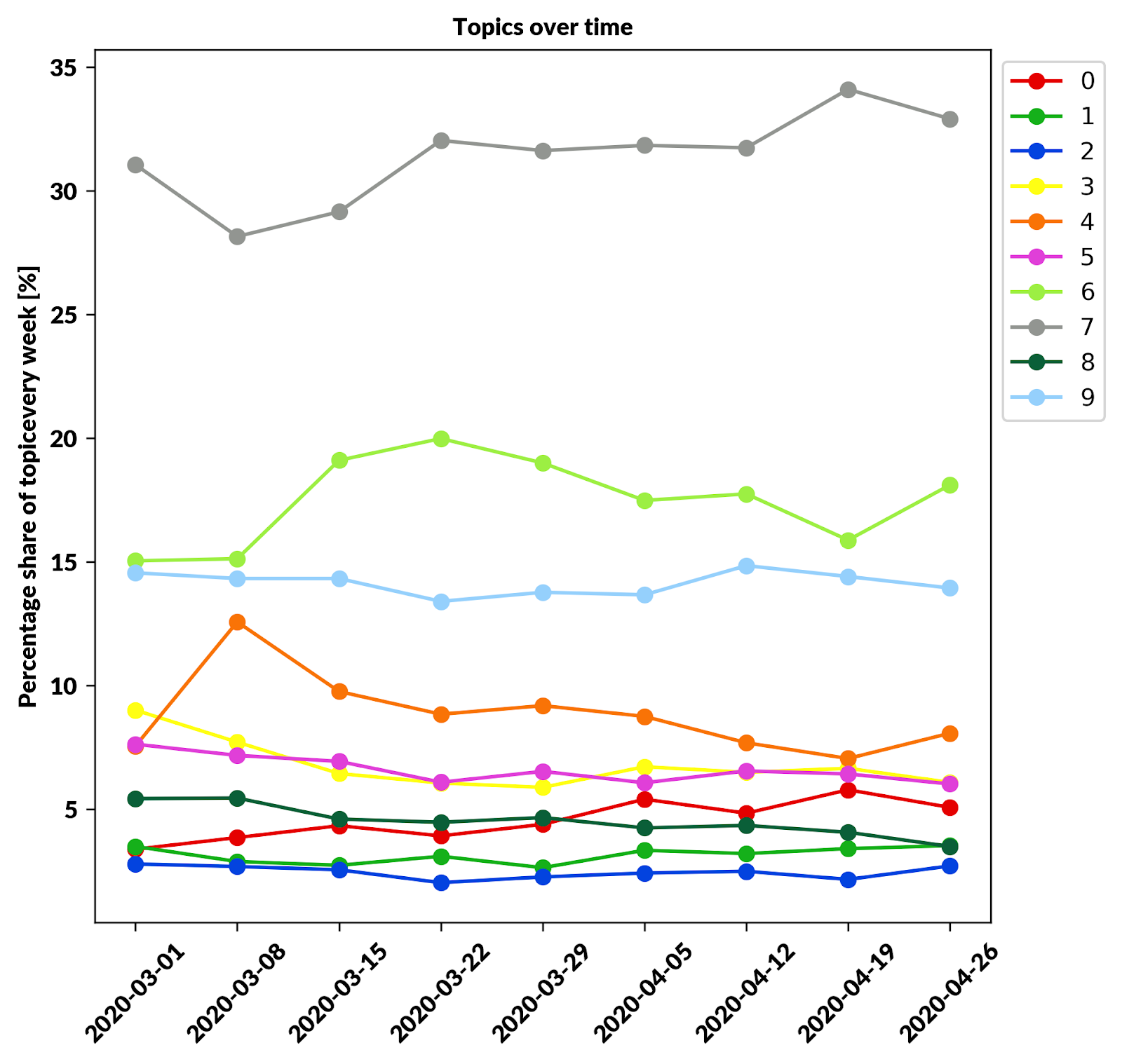
- Time series analysis of topics — As we can see in the plot below some topics can gain more attention like number 7 and some of them fade away like number 4. Trying to grasp the idea of what is popular or can be popular in the future is a good thing to look back and see how topics were changing in the past. 主题的时间序列分析-正如我们在下面的图表中看到的那样,某些主题可以像数字7一样得到更多的关注,而某些主题像数字4一样可以逐渐消失。尝试掌握流行或将来流行的想法是回顾过去,看看主题是如何变化的,这是一件好事。
Use case
用例
In one of our recent projects for Collegium Civitas we analyzed 50 000 social media posts and comments and performed topic analysis on them. It allowed our client to answer questions like:
在我们针对Colvitaium Civitas的最新项目之一中,我们分析了5万个社交媒体帖子和评论,并对它们进行了主题分析。 它使我们的客户可以回答以下问题:
1) What was discussed in the time span of 2 months in social media?
1)在两个月的社交媒体中讨论了什么?
In the dataset we were able to distinguish 10 different topics, revolving around Covid-19. Discussions covered statistics and covid-19 etiology, everyday life, government response to pandemic, consequences of limitations in traveling, trade market and supplies, everyday life, health care during pandemic, church and politics, common knowledge and conspiracy theories of Covid-19, politics and economy, spam messages and ads.
在数据集中,我们能够区分10个不同的主题,围绕Covid-19。 讨论内容涉及统计数据和covid-19的病因,日常生活,政府对大流行的React,旅行限制,贸易市场和物资供应的影响,日常生活,大流行期间的医疗保健,教堂和政治,常识和阴谋理论,政治和经济,垃圾邮件和广告。
2) How were the discussions influenced by the pandemic situation?
2)讨论如何受到大流行情况的影响?
During the pandemic burst the biggest theme was the origin and statistics of Covid-19. People talked about how the situation is changing and exchanged information about ways of disease spreading . To read more visit Collegium Civitas’ site (Polish version only).
大流行爆发期间,最大的主题是Covid-19的起源和统计数据。 人们讨论了情况的变化情况,并就疾病传播方式交换了信息。 要了解更多信息,请访问Collegium Civitas的网站 (仅波兰版)。
仇恨语音识别 (Hate speech recognition)
Another question that can be answered with machine learning is “what kind of emotion do people express in their comments or posts?” or “is my content generating hateful comments?”. There are only a few solutions for these tasks in the Polish language. That is why we build models based on social media text for Sentiment and Hate Speech recognition at Sotrender. Our solutions were built in two steps.
机器学习可以回答的另一个问题是“ 人们在评论或帖子中表达什么样的情感? ”或“ 我的内容是否引起仇恨评论? ”。 用波兰语完成这些任务的解决方案很少。 这就是为什么我们基于社交媒体文本在Sotrender上建立用于情感和仇恨语音识别的模型的原因 。 我们的解决方案分两步构建。
The first step is to convert text and emojis into numerical vector representation (embeddings) to be used later in neural networks. The main goal of this step is to achieve some kind of language model (LM) that has the knowledge of a human language so that vectors representing similar words are close to each other (for example: queen and king or paragraph and article) which implies that these words have similar meaning (semantic similarity). The property is shown on the graph below.
第一步是将文本和表情符号转换为数字矢量表示形式(嵌入),以供以后在神经网络中使用。 此步骤的主要目标是获得某种具有人类语言知识的语言模型(LM),以便表示相似单词的向量彼此接近(例如:皇后和国王或段落和文章),这意味着这些词具有相似的含义(语义相似性)。 该属性如下图所示。
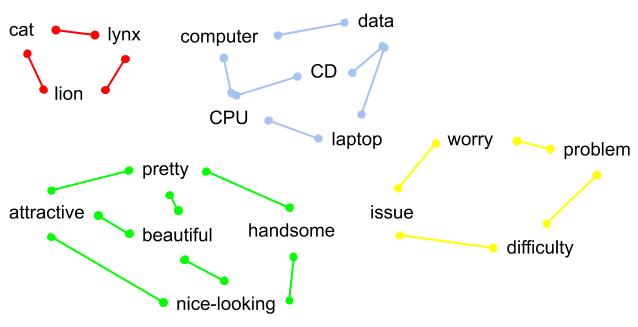
Training this model is similar to teaching a child how to speak by talking to them. Children by listening to their parents talk are able to grasp the meaning of words and the more they hear the more they understand.
训练这种模式类似于教孩子如何通过与他们交谈来说话。 孩子们通过听父母说话可以理解单词的含义,听得越多,他们的理解就越多。
According to this analogy, we have to use a huge set of social media text to train our model to understand its language. That is why we used a set of 100 millions posts and comments to train our model so it can properly assign vectors to words as well as to emojis. Tokens vectorised with an embeddings model provide the input to the neural network.
根据这种类比,我们必须使用大量的社交媒体文本来训练我们的模型以理解其语言。 这就是为什么我们使用了1亿篇帖子和评论来训练我们的模型,以便它可以将矢量正确分配给单词以及表情符号的原因。 用嵌入模型矢量化的令牌为神经网络提供输入。
The second step is designing neural networks for a specific task — Hate speech recognition. The most important thing is the data set — the model needs examples of hate speech and non-hateful texts to learn how to tell them apart. In order to get best results you need to experiment with different architectures and model’s hyperparameters.
第二步是为特定任务(讨厌的语音识别)设计神经网络。 最重要的是数据集-该模型需要仇恨言论和非仇恨文本的示例,以学习如何区分它们。 为了获得最佳结果,您需要尝试使用不同的体系结构和模型的超参数。
As a result of the hate speech recognition model, we get another grouping of our data set. Now we can see how our audience reacts, how many hateful comments or posts it’s creating. What’s more, by combining it again with the time of publication of each comment, we can see if there was a specific time period when the most hateful comments were generated like shown in a histogram below.
仇恨语音识别模型的结果是,我们得到了另一组数据集。 现在我们可以看到观众的React,正在创建多少可恶的评论或帖子 。 此外,通过将其与每个评论的发布时间再次结合,我们可以查看是否在特定时间段内生成了最令人讨厌的评论,如下面的直方图所示。
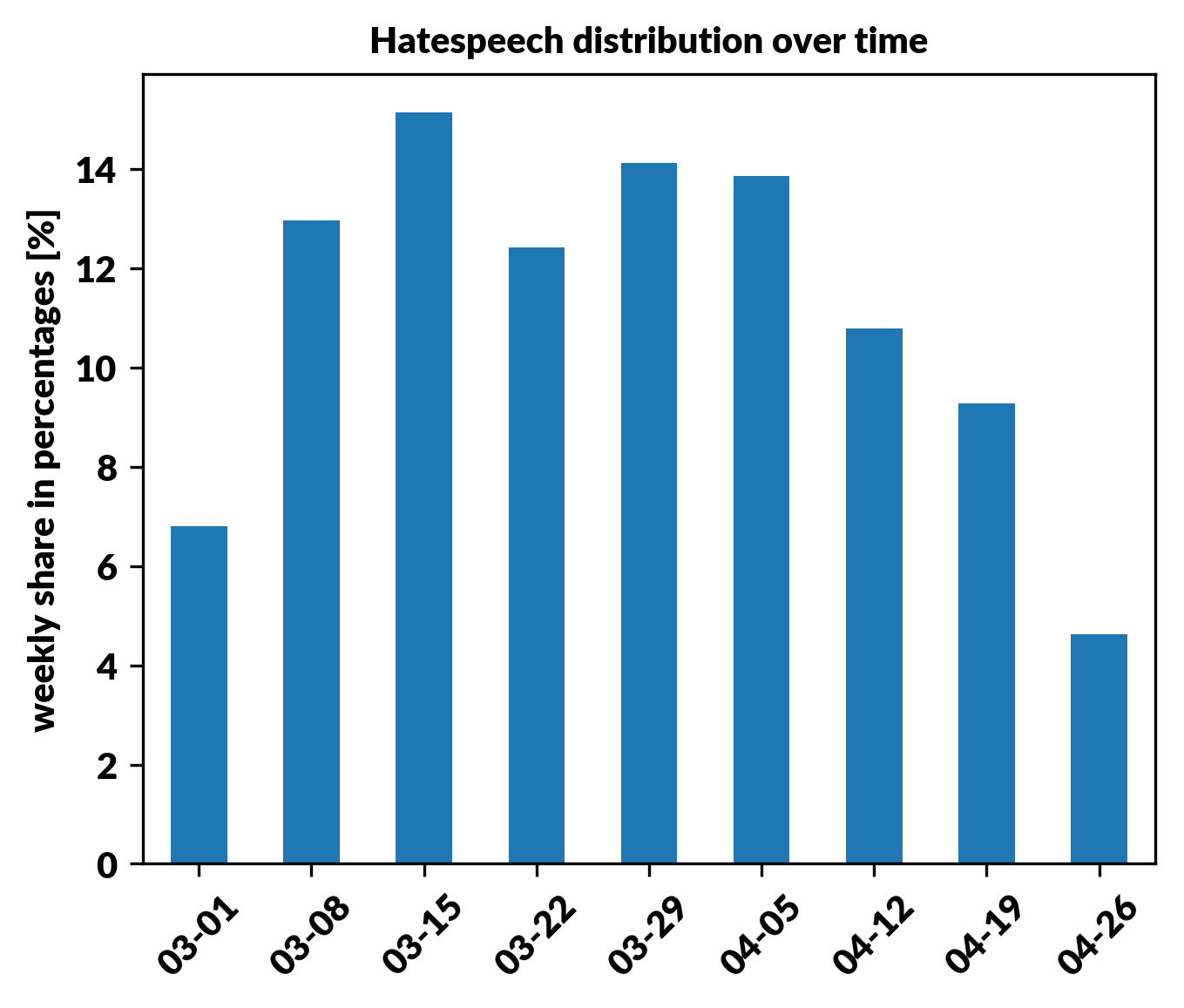
Combining this distribution with recent posts or events can give you insight into the type of content that provokes people. Also changes of hate speech contribution in time can be related with changes in topic distribution. Combining all the information from analysis can provide an in-depth image of the dataset.
将此分布与最近的帖子或事件相结合,可以使您深入了解引起人们注意的内容类型 。 仇恨言论贡献的及时变化也可能与主题分布的变化有关。 结合来自分析的所有信息可以提供数据集的深入图像。
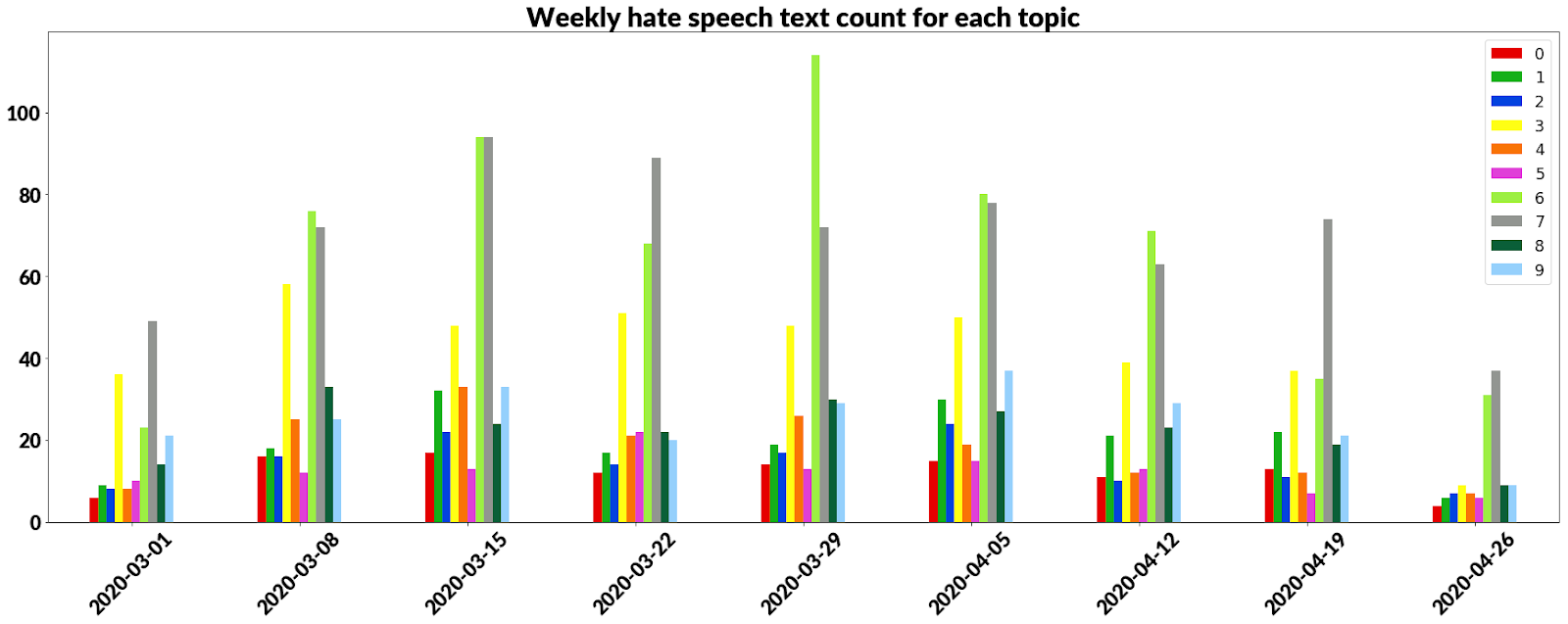
As the histogram above shows most hate is connected to topic 3, 6 and 7. Knowing what makes people angry gives the opportunity to avoid sensitive topics in the future.
如上面的直方图所示,大多数仇恨都与主题3、6和7有关。 知道什么使人生气会使将来有机会避免敏感主题。
Same goes for sentiment analysis. We can produce similar visualizations for positive, negative or neutral comments and see their distribution in time or topics. If you would like to read thewhole report build based on our analysis of the 8 weeks of data you can find it here (only Polish version).
情绪分析也是如此。 我们可以为肯定,否定或中立的评论提供类似的可视化效果,并查看它们在时间或主题上的分布。 如果您想根据我们对8周数据的分析来阅读整个报告,则可以在此处找到(仅限波兰语版本)。
结论 (Conclusion)
In Sotrender we have models for hate speech and sentiment recognition that are constantly improved and updated for social media texts. What’s more we have experience in building topic modeling models for individual cases. As you can see there’s a lot of benefits coming from this type of analysis:
在Sotrender中,我们提供了针对仇恨言论和情感识别的模型,这些模型会针对社交媒体文本进行不断改进和更新。 此外,我们在为个别案例构建主题建模模型方面经验丰富。 如您所见,这种分析有很多好处:
- Getting to know your audience 了解你的听众
- Having in depth look into topics of comments 深入研究评论主题
- Discovering trending themes 发现热门主题
- Finding source of hatred or negativity in our content 在我们的内容中找到仇恨或否定的根源
To name just a few!
仅举几例!
需求分析与建模最佳实践


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









