





regex 正则表达式
Most of the data in the world are unstructured data form because, in human communication, message transmission happens in words, not in a table or other structured data format. Each day we produce unstructured data from emails, SMS, tweets, feedback, social media posts, blogs, articles, documents, etc.
在世界上的数据的M个OST是非结构化数据形式,因为在人类传播,消息传输中发生的话,而不是在一个表格或其它结构化数据格式。 每天,我们都会通过电子邮件,短信,推文,反馈,社交媒体帖子,博客,文章,文档等生成非结构化数据。
As we all know, the text is the most unstructured form of all the available data. Extracting Meaning from Text is Hard. Computers can’t yet truly understand text data even English Language in the way that humans do, but they can already do a lot with text data. In some areas using a computer or machine, what you can do with NLP already seems like magic.
众所周知,文本是所有可用数据中最非结构化的形式。 从文本中提取含义很难。 电脑还无法像人类那样真正理解文本数据,甚至是英语,但它们已经可以对文本数据做很多事情。 在某些使用计算机或机器的区域中,使用NLP可以做的事情似乎已经很神奇了。
NLP helps us to organize the massive chunks of text data and solve a wide range of problems such as — Machine Translation, Text Summarization, Named Entity Recognition (NER), Topic Modeling and Topic Segmentation, Semantic Parsing, Question and Answering (Q&A), Relationship Extraction, Sentiment Analysis, and Speech Recognition, etc.
NLP帮助我们组织大量的文本数据并解决各种问题,例如:机器翻译,文本摘要,命名实体识别(NER),主题建模和主题细分,语义解析,问题与回答(Q&A),关系提取,情感分析和语音识别等
NLP algorithms are based on machine learning algorithms. Doing anything complicated in machine learning usually means building a pipeline. The idea is to break up your problem into very small pieces and then use machine learning to solve each smaller piece separately. Then by chaining together several machine learning models that feed into each other, you can do very complicated things.
NLP算法基于机器学习算法。 在机器学习中做任何复杂的事情通常意味着建立一条管道 。 想法是将您的问题分解成很小的部分,然后使用机器学习分别解决每个较小的部分。 然后,通过将相互馈送的多个机器学习模型链接在一起,您可以做非常复杂的事情。
You might be able to solve lots of problems and also save a lot of time by applying NLP techniques to your own projects. Using NLP, We’ll break down the process of understanding text (English) into small chunks of words and see how each one works.
通过将NLP技术应用于自己的项目,您也许能够解决很多问题,并节省大量时间。 使用NLP,我们将把理解文本(英语)的过程分解成小的单词,并查看每个单词的工作方式。
Sentence Hierarchy:
句子层次结构:
A sentence typically follows a hierarchical structure consisting of the following components:
句子通常遵循由以下组件组成的层次结构:

Standard NLP Workflow
标准NLP工作流程
CRISP-DM Model is a Cross-industry standard process for data mining, known as CRISP-DM, which is an open standard process model that describes common approaches used by data mining experts. It is the most widely-used analytics model. Typically, any NLP-based problem can be solved by a methodical workflow that has a sequence of steps. The major steps are depicted in the following figure.
CRISP-DM模型是用于数据挖掘的跨行业标准过程,称为CRISP-DM,它是一种开放标准过程模型,描述了数据挖掘专家使用的常用方法。 它是使用最广泛的分析模型。 通常,任何基于NLP的问题都可以通过有步骤的有条理的工作流程来解决。 下图描述了主要步骤。

We usually start with a corpus of text documents and follow standard processes of text wrangling and pre-processing, parsing, and basic exploratory data analysis. Based on the initial insights, we usually represent the text using relevant feature engineering techniques. Depending on the problem at hand, we either focus on building predictive supervised models or unsupervised models, which usually focus more on pattern mining and grouping. Finally, we evaluate the model and the overall success criteria with relevant stakeholders or customers and deploy the final model for future usage.
我们通常从文本文档的语料库开始,并遵循文本整理和预处理,解析以及基本探索性数据分析的标准过程。 基于最初的见识,我们通常使用相关的特征工程技术来表示文本。 根据当前的问题,我们要么专注于构建预测性监督模型,要么专注于非监督模型,后者通常更多地关注模式挖掘和分组。 最后,我们与利益相关者或客户一起评估模型和总体成功标准,并部署最终模型以供将来使用。
NLP Pipeline:
NLP管道:
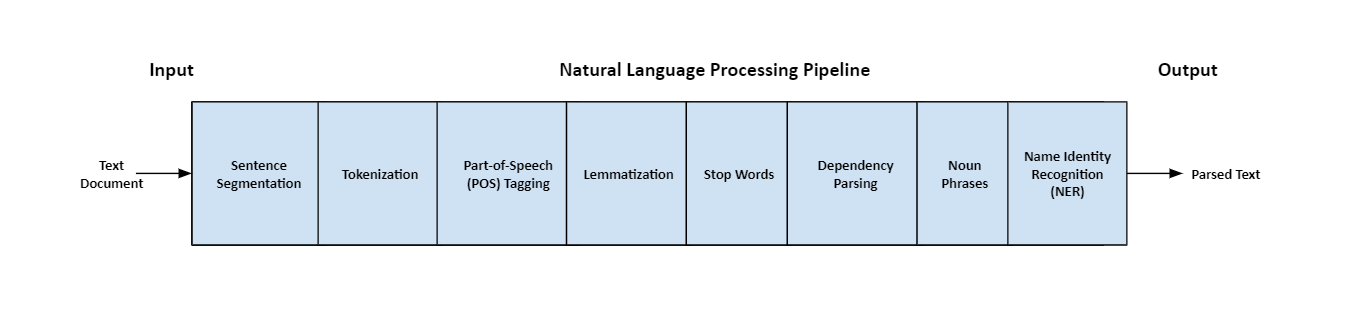
Above mentioned steps are used in a typical NLP pipeline, but you will skip steps or re-order steps depending on what you want to do and how your NLP library is implemented. For example, some libraries like spaCy do sentence segmentation much later in the pipeline using the results of the dependency parse.
上面提到的步骤在典型的NLP管道中使用,但是您将跳过步骤或对步骤进行重新排序,这取决于您要执行的操作以及NLP库的实现方式。 例如,像spaCy这样的一些库会在管道中使用依赖项解析的结果进行句子分割。
NLP管道:分步 (NLP Pipeline: Step-by-step)
Converting text to lowercase:
将文本转换为小写:
In-text normalization process, very first step to convert all text data into lowercase which makes all text on a level playing field. With this step, we are able to cover each and every word available in text data.
文本规范化过程,这是将所有文本数据转换为小写字母的第一步,这使所有文本都处于公平的竞争环境中。 通过此步骤,我们可以覆盖文本数据中可用的每个单词。
Removing HTML Tags:
删除HTML标签:
HTML tags are typically one of these components which don’t add much value towards understanding and analyzing text. When we used text data collected using techniques like web scraping or screen scraping, it contained a lot of noise. We can remove unnecessary HTML tags and retain the useful textual information for further process.
HTML标记通常是这些组件之一,不会为理解和分析文本增加太多价值。 当我们使用通过网络抓取或屏幕抓取等技术收集的文本数据时,其中包含很多噪音。 我们可以删除不必要HTML标记,并保留有用的文本信息以供进一步处理。
使用正则表达式(Regex)删除HTML标签 (Remove HTML Tags using Regular Expression (Regex))
In [01]:
在[01]中:
# Import libraryimport reTAG_RE = re.compile(r'<[^>]+>')def remove_tags(text): #define remove tag funtion
return TAG_RE.sub('', text)In [02]:
在[02]中:
text = """<div> <h1>Title</h1> <p>A long text........ </p> <a href=""> a link </a> </div>"""In [03]:
在[03]中:
text = remove_tags(text)
textOut[04]:
出[04]:
' Title A long text........ a linkRemoving accented characters
删除重音字符
Usually, in any text corpus, you might be dealing with accented characters/letters, especially if you only want to analyze the English language. Hence, we need to make sure that these characters are converted and standardized into ASCII characters. A simple example — converting é to e.
通常,在任何文本语料库中,您都可能要处理带重音的字符/字母,尤其是如果您只想分析英语时。 因此,我们需要确保将这些字符转换并标准化为ASCII字符。 一个简单的示例-将é转换为e。
Expanding Contractions
扩大收缩
Contractions are words or combinations of words that are shortened by dropping letters and replacing them by an apostrophe. Let’s have a look at some examples:
收缩是单词或单词组合,可通过删除字母并将其替换为撇号来缩短。 让我们看一些例子:
we’re = we are; we’ve = we have; I’d = I would
我们是=我们是; 我们有=我们有; 我会=我会
We can say that contractions are shortened versions of words or syllables. Or simply, a contraction is an abbreviation for a sequence of words.
我们可以说收缩是单词或音节的缩写。 或简单地说,收缩是单词序列的缩写。
In NLP, we can deal with constraints by converting each contraction to its expanded, original form helps with text standardization.
在NLP中,我们可以通过将每个压缩转换为其扩展的原始格式来处理约束,从而有助于文本标准化。
Removing Special Characters
删除特殊字符
Special characters and symbols are usually non-alphanumeric characters or even occasionally numeric characters (depending on the problem), which adds to the extra noise in unstructured text. Usually, simple regular expressions (regexes) can be used to remove them.
特殊字符和符号通常是非字母数字字符,有时甚至是数字字符(取决于问题),这会增加非结构化文本中的额外杂音。 通常,可以使用简单的正则表达式(regexes)删除它们。
Stemming
抽干
To understand the stemming, we have to gain some knowledge about the word stem. Word stems are also known as the base form of a word, and we can create new words by attaching affixes to them in a process known as inflection.
要理解词干,我们必须了解一些关于词干的知识。 词干也被称为单词的基本形式,我们可以通过在词缀变化过程中将词缀附加到词上来创建新词。
You can add affixes to it and form new words like JUMPS, JUMPED, and JUMPING. In this case, the base word JUMP is the word stem.
您可以在其上添加词缀并形成新单词,例如JUMPS,JUMPD和JUMPING。 在这种情况下,基本词JUMP是词干。
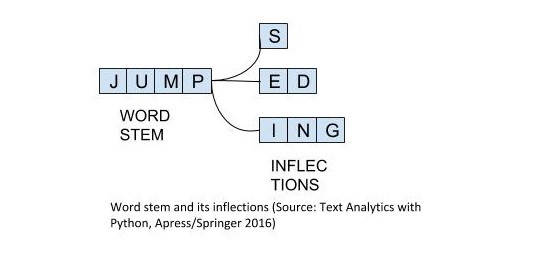
The figure shows how the word stem is present in all its inflections since it forms the base on which each inflection is built upon using affixes. The reverse process of obtaining the base form of a word from its inflected form is known as stemming. Stemming helps us in standardizing words to their base or root stem, irrespective of their inflections, which helps many applications like classifying or clustering text, and even in information retrieval.
该图显示了词干一词在其所有变体中是如何出现的,因为它形成了使用词缀建立每次变体的基础。 从词的屈折形式获取单词基本形式的相反过程称为词干。 词干帮助我们将单词标准化为词根或词根,而不管其词尾变化如何,这有助于许多应用程序,例如对文本进行分类或聚类,甚至在信息检索中。
Different types of stemmers in NLTK are PorterStemmer, LancasterStemmer, SnowballStemmer.
NLTK中不同类型的茎干是PorterStemmer,LancasterStemmer和SnowballStemmer。
Lemmatization:
合法化:
In NLP, lemmatization is the process of figuring out the root form or root word (most basic form) or lemma of each word in the sentence. Lemmatization is very similar to stemming, where we remove word affixes to get to the base form of a word. The difference is that the root word is always a lexicographically correct word (present in the dictionary), but the root stem may not be so. Thus, the root word, also known as the lemma, will always be present in the dictionary. It uses a knowledge base called WordNet. Because of knowledge, lemmatization can even convert words that are different and cant be solved by stemmers, for example converting “came” to “come”.
在NLP中,词义化是弄清楚句子中每个单词的词根形式或词根(最基本的形式)或词缀的过程。 词法化与词干法非常相似,在词干法中,我们删除词缀以得到词的基本形式。 区别在于根词始终是词典上正确的词(在词典中存在),但是根词干可能并非如此。 因此,根词(也称为引理)将始终存在于字典中。 它使用称为WordNet的知识库。 由于知识,词根化甚至可以转换词干不能解决的不同单词,例如将“来”转换为“来”。
StopWords
停用词
Words which have little or no significance, especially when constructing meaningful features from text, are known as stopwords or stop words. These are usually words that end up having the maximum frequency if you do a simple term or word frequency in a corpus. Consider words like a, an, the, be etc. These words don’t add any extra information in a sentence.
几乎没有意义或没有意义的单词,尤其是从文本构造有意义的特征时,被称为停用词或停用词。 如果您在语料库中做一个简单的词或词频,这些词通常会以最大频率出现。 考虑诸如a,an,the,be等的单词。这些单词不会在句子中添加任何额外的信息。
整合所有内容—构建文本规范化器 (Bringing it all together — Building a Text Normalizer)
Text normalization includes:
文本规范化包括:
- Converting Text (all letters) into lower case 将文本(所有字母)转换为小写
- Removing HTML tags 删除HTML标签
- Expanding contractions 宫缩扩大
- Converting numbers into words or removing numbers 将数字转换为单词或删除数字
- Removing special character (punctuations, accent marks, and other diacritics) 删除特殊字符(标点符号,重音符号和其他变音符号)
- Removing white spaces 删除空格
- Word Tokenization 词标记化
- Stemming and Lemmatization 词干和词法化
- Removing stop words, sparse terms, and particular words 删除停用词,稀疏词和特定词
In NLP, we can deal with constraints by converting each contraction to its expanded, original form helps with text standardization.
在NLP中,我们可以通过将每个压缩转换为其扩展的原始格式来处理约束,从而有助于文本标准化。
翻译自: https://medium.com/@suneelpatel.in/nlp-pipeline-building-an-nlp-pipeline-step-by-step-7f0576e11d08
regex 正则表达式














 260
260











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









