






chime-4 lstm
关于比赛 (About the competition)
Not so long ago, there was a challenge for speech separation and recognition called CHIME-6. CHIME competitions have been held since 2011. The main distinguishing feature of these competitions is that conversational speech recorded in everyday home environments on several devices simultaneously is used to train and evaluate participants’ solutions.
不久前,语音分离和识别面临一个挑战,称为CHIME-6 。 CHIME竞赛自2011年以来一直举行。这些竞赛的主要区别在于,在日常家庭环境中同时在几种设备上记录的对话语音用于培训和评估参与者的解决方案。
The data provided for the competition was recorded during the “home parties” of the four participants. These parties were recorded on 32 channels at the same time (six four-channel Microsoft Kinects in the room + two-channel microphones on each of the four speakers).
为比赛提供的数据是在四名参与者的“家庭聚会”期间记录的。 这些参与者同时记录在32个通道上(房间中有六个四通道Microsoft Kinects +四个扬声器中的每个都有两个通道麦克风)。
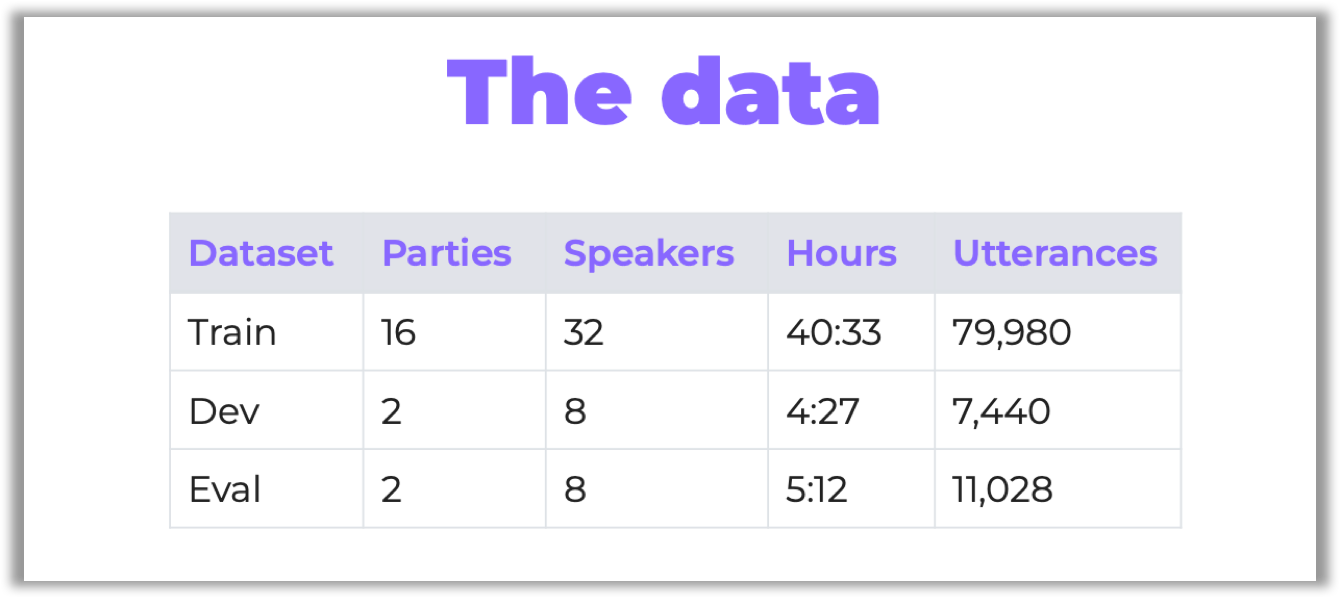
There were 20 parties, all of them lasting 2–3 hours. The organizers have chosen some of them for testing:
有20个聚会,所有聚会持续2-3小时。 组织者选择了其中一些进行测试:
By the way, it was the same dataset that had been used in the previous CHIME-5 challenge. However, the organizers prepared several techniques to improve data quality (see the description of software baselines on GitHub, sections “Array synchronization” and “Speech enhancement”).
顺便说一句,它与之前的CHIME-5挑战赛中使用的数据集相同。 但是,组织者准备了几种提高数据质量的技术(请参阅GitHub上软件基线的描述,“数组同步”和“语音增强”部分)。
To find out more about the competition and data preparation here, visit its GitHub page or read the overview on Arxiv.org.
要在此处找到有关竞赛和数据准备的更多信息,请访问其GitHub页面或在Arxiv.org上阅读概述 。
This year there were two tracks:
今年有两条路:
Track 1 — multiple-array speech recognition;Track 2 — multiple-array diarization and recognition.
音轨1-多阵列语音识别; 专题2 –多阵列分析和识别。
And for each track, there were two separate ranking categories:
对于每个曲目,都有两个单独的排名类别:
Ranking A — systems based on conventional acoustic modeling and official language modeling;
排名A-基于常规声学建模和官方语言建模的系统;
Ranking B — all other systems, including systems based on the end-to-end ASR baseline or systems whose lexicon and/or language model have been modified.
等级B-所有其他系统,包括基于端到端ASR基线的系统或已修改其词典和/或语言模型的系统。
The organizers provided a baseline for participation, which includes a pipeline based on the
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 9281
9281











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









