





 本文介绍了如何在偏最小二乘(PLS)算法中利用Hotelling T²变换进行变量选择。Hotelling变换是一种统计方法,常用于数据分析和机器学习领域,以识别和剔除不重要的输入变量。
本文介绍了如何在偏最小二乘(PLS)算法中利用Hotelling T²变换进行变量选择。Hotelling变换是一种统计方法,常用于数据分析和机器学习领域,以识别和剔除不重要的输入变量。
hotelling变换
背景 (Background)
One of the most common challenges encountered in the modeling of spectroscopic data is to select a subset of variables (i.e. wavelengths) out of a large number of variables associated with the response variable. It is common for spectroscopic data to have a large number of variables relative to the number of observations. In such a situation, the selection of a smaller number of variables is crucial especially if we want to speed up the computation time and gain in the model’s stability and interpretability. Typically, variable selection methods are classified into two groups:
在光谱数据的建模中遇到的最常见的挑战Òne为选择的变量的子集(即,波长)了大量的与该响应相关联的变量的变量。 光谱数据相对于观测数量通常具有大量变量。 在这种情况下,选择较小数量的变量至关重要,尤其是在我们希望加快计算时间并提高模型稳定性和可解释性的情况下。 通常,变量选择方法分为两类:
• Filter-based methods: the most relevant variables are selected as a preprocessing step independently of the prediction model.• Wrapper-based methods: use the supervised learning approach.
•基于过滤器的方法:与预测模型无关,选择最相关的变量作为预处理步骤。•基于包装器的方法:使用监督学习方法。
Hence, any PLS-based variable selection is a wrapper method. Wrapper methods need a selection criterion that relies solely on the characteristics of the data at hand.
因此,任何基于PLS的变量选择都是包装器方法。 包装方法需要一个选择标准,该选择标准仅依赖于手头数据的特征。
方法 (Method)
Let us consider a regression problem for which the relation between the response variable y (n × 1) and the predictor matrix X (n × p) is assumed to be explained by the linear model y = β X, where β (p × 1) is the regression coefficients. Our dataset is comprised of n = 466 observations from various plant materials, and y corresponds to the concentration of calcium (Ca) for each plant. The matrix X is our measured LIBS spectra that includes p = 7151 wavelength variables. Our objective is therefore to find some columns subsets of X with satisfactorily predictive power for the Ca content.
让我们考虑假定的量,响应变量Y(N×1)和预测器矩阵X(N×P)之间的关系由线性模型Y =βX,其中β(P×1说明一个回归问题)是回归系数。 我们的数据集由来自各种植物材料的n = 466个观测值组成,并且y对应于每种植物的钙(Ca)浓度。 矩阵X是我们测得的LIBS光谱,其中包括p = 7151个波长变量。 因此,我们的目标是找到一些X的子集,这些子集对于Ca含量具有令人满意的预测能力。
ROBPCA建模 (ROBPCA modeling)
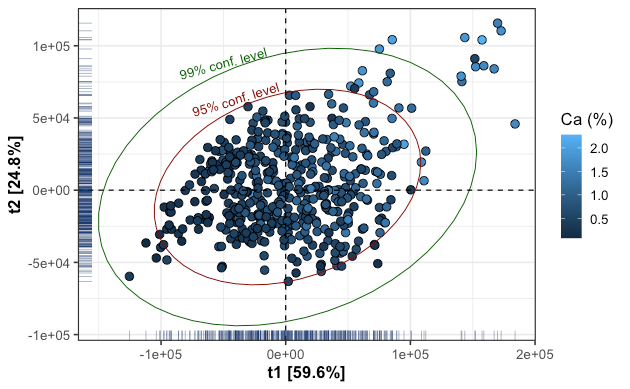
Let’s first perform robust principal components analysis (ROBPCA) to help visualize our data and detect whether there is an unusual structure or pattern. The obtained scores are illustrated by the scatterplot below in which the ellipses represent the 95% and 99% confidence interval from the Hotelling’s T². Most observations are below the 95% confidence level, albeit some observations seem to cluster on the top-right corner of the scores scatterplot.
让我们首先执行健壮的主成分分析( ROBPCA ),以帮助可视化我们的数据并检测是否存在异常的结构或模式。 所获得的分数由下面的散点图说明,其中椭圆表示距Hotelling T 2的95%和99%置信区间。 尽管有些观察似乎聚集在分数散点图的右上角,但大多数观察都低于95%的置信度。
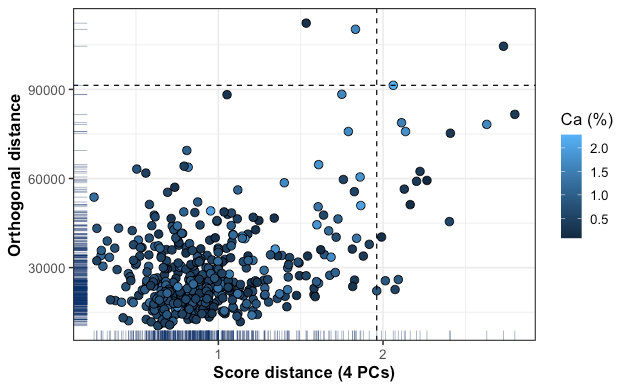
However, when looking more closely, for instance using the outlier map, we can see that ultimately there are only three observations that seem to pose a problem. We have two observations flagged as orthogonal outliers and only one as a bad leverage point. Some observations are flagged as good leverage points, whilst most are regular observations.
但是,当更仔细地观察时(例如,使用离群值地图),我们可以看到最终只有三个观测值似乎构成问题。 我们有两个观测值标记为正交离群值,只有一个观测值标记为不良杠杆点。 一些观察值被标记为良好的杠杆点,而大多数是常规观察值。
PLS建模 (PLS modeling)
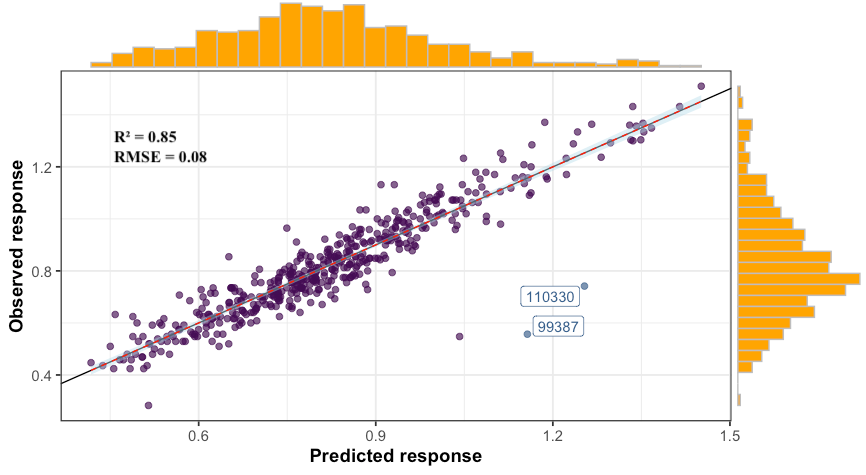
It is worth mentioning that in our regression problem, ordinary least square (OLS) fitting is no option since n ≪ p. PLS resolves this by searching for a small set of the so-called latent variables (LVs), that performs a simultaneous decomposition of X and y with the constraint that these components explain as much as possible of the covariance between X and y. The figures below are the results obtained from the PLS model. We obtained an R² of 0.85 with an RMSE and MAE of 0.08 and 0.06, respectively, which correspond to a mean absolute percentage error (MAPE) of approximately 7%.
值得一提的是,在我们的回归问题,普通最小二乘法(OLS)拟合是由于N“P别无选择。 PLS通过搜索一小组所谓的潜在变量(LVs)来解决此问题,该变量在约束X和y尽可能解释X和y之间的协方差的约束下执行X和y的同时分解。 下图是从PLS模型获得的结果。 我们获得的R²为0.85,RMSE和MAE分别为0.08和0.06,这对应于大约7%的平均绝对百分比误差(MAPE)。
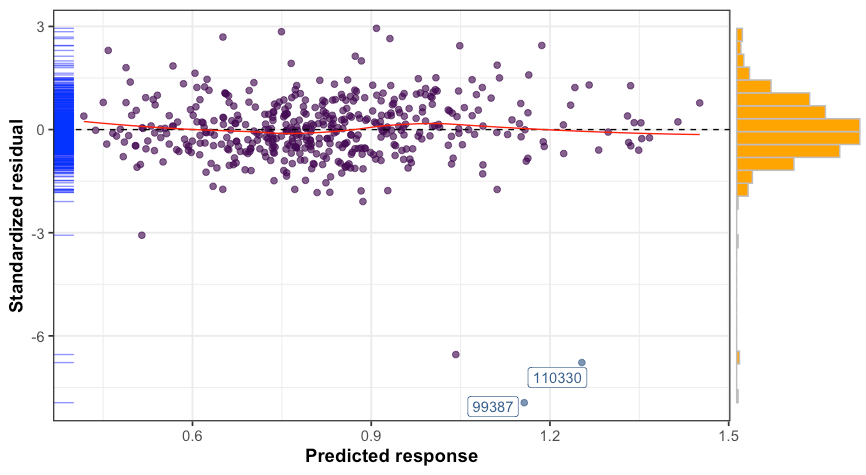
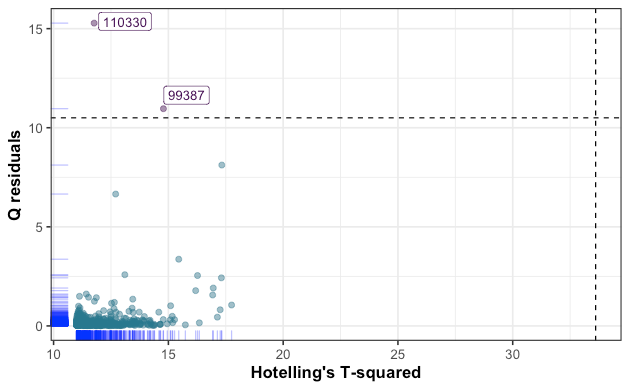
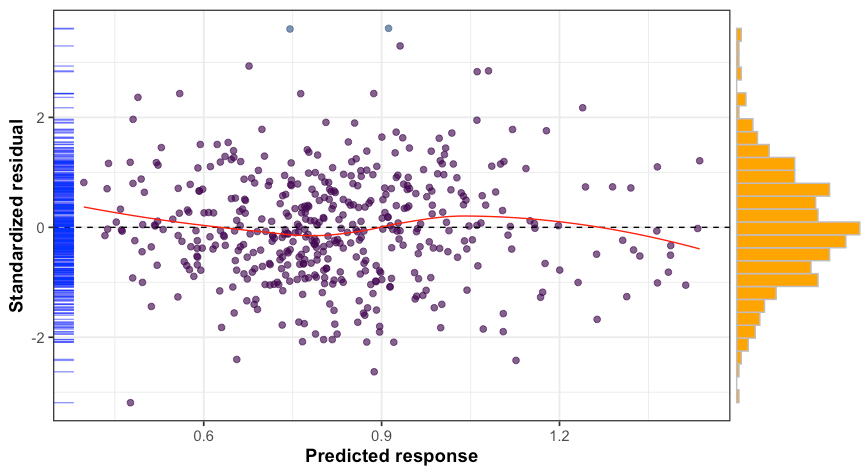
Similarly to the ROBPCA outlier map, the PLS residual plot has flagged three observations that exhibit high standardized residual value. Another way to check for outliers is to calculate Q-residuals and Hotelling’s T² from the PLS model, then define a criterion for which an observation is considered as an outlier or not. High Q-residual value corresponds to an observation which is not well explained by the model, while high Hotelling’s T² value expresses an observation that is far from the center of regular observations (i.e, score = 0). The results are plotted below.
与ROBPCA离群图相似,PLS残差图标记了三个观测值,这些观测值表现出较高的标准残差值。 检查异常值的另一种方法是从PLS模型计算Q残差和Hotelling的T²,然后定义一个标准,对于该标准,观察值是否视为异常值。 高Q残差值对应于模型无法很好解释的观测值,而高Hotelling的T²值表示远离常规观测值中心的观测值(即,得分= 0)。 结果绘制在下面。
基于Hotelling-T²的变量选择 (Hotelling-T² based variable selection)
Let’s now perform variable selection from our PLS model, which is carried out by computing the T² statistic (for more details see Mehmood, 2016),
现在,让我们从我们的PLS模型中执行变量选择,该模型是通过计算T²统计信息来实现的(有关更多详细信息,请参阅Mehmood,2016 ),
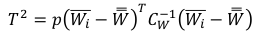
where W is the loading weight matrix and C is the covariance matrix. Thus, a variable is selected based on the following criteria,
其中W是装载权重矩阵, C是协方差矩阵。 因此,根据以下条件选择变量:
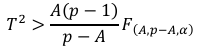
where A is number of LVs from our PLS model, and 1-𝛼 is the confidence level (with 𝛼 equals 0.05 or 0.01) from the F-distribution.
其中A是我们的PLS模型中LV的数量,1-𝛼是F分布的置信度(𝛼等于0.05或0.01)。
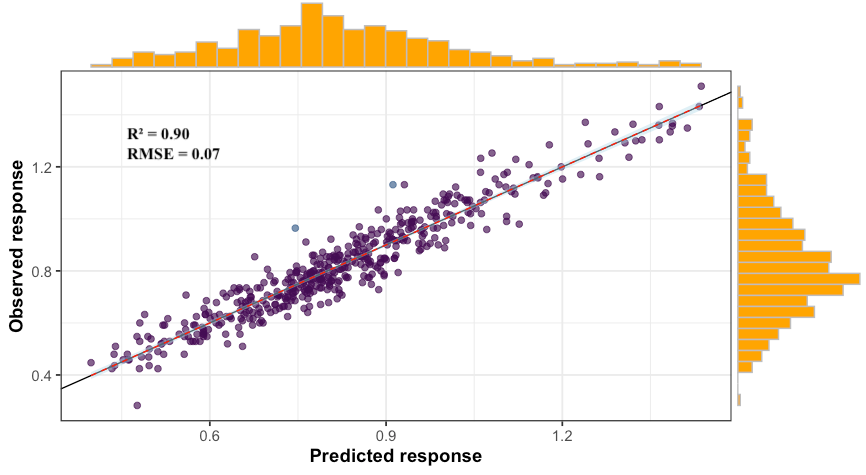
Thus, from 7151 variables in our original dataset, only 217 were selected based on the aforementioned selection criterion. The observed vs. predicted plot is displayed below along with the model’s R² and RMSE.
因此,从我们原始数据集中的7151个变量中,仅基于上述选择标准选择了217个。 观察到的与预测的图以及模型的R²和RMSE一起显示在下面。
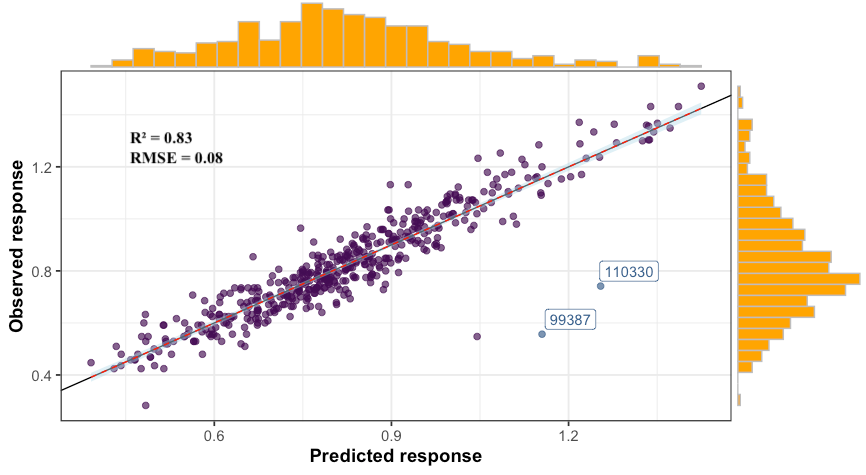
In the results below, the three observations that were flagged as outliers were removed from the dataset. The mean absolute percentage error is 6%.
在以下结果中,从数据集中删除了标记为异常值的三个观察值。 平均绝对百分比误差为6%。
摘要 (Summary)
In this article, we successfully performed Hotelling-T² based variable selection using partial least squares. We obtained a huge reduction (-97%) in the number of selected variables compared to using the model with the full dataset.
在本文中,我们使用偏最小二乘成功地执行了基于Hotelling-T²的变量选择。 与使用具有完整数据集的模型相比,我们选择的变量数量大大减少了(-97%)。
hotelling变换















 3621
3621

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









