






python语音特征提取
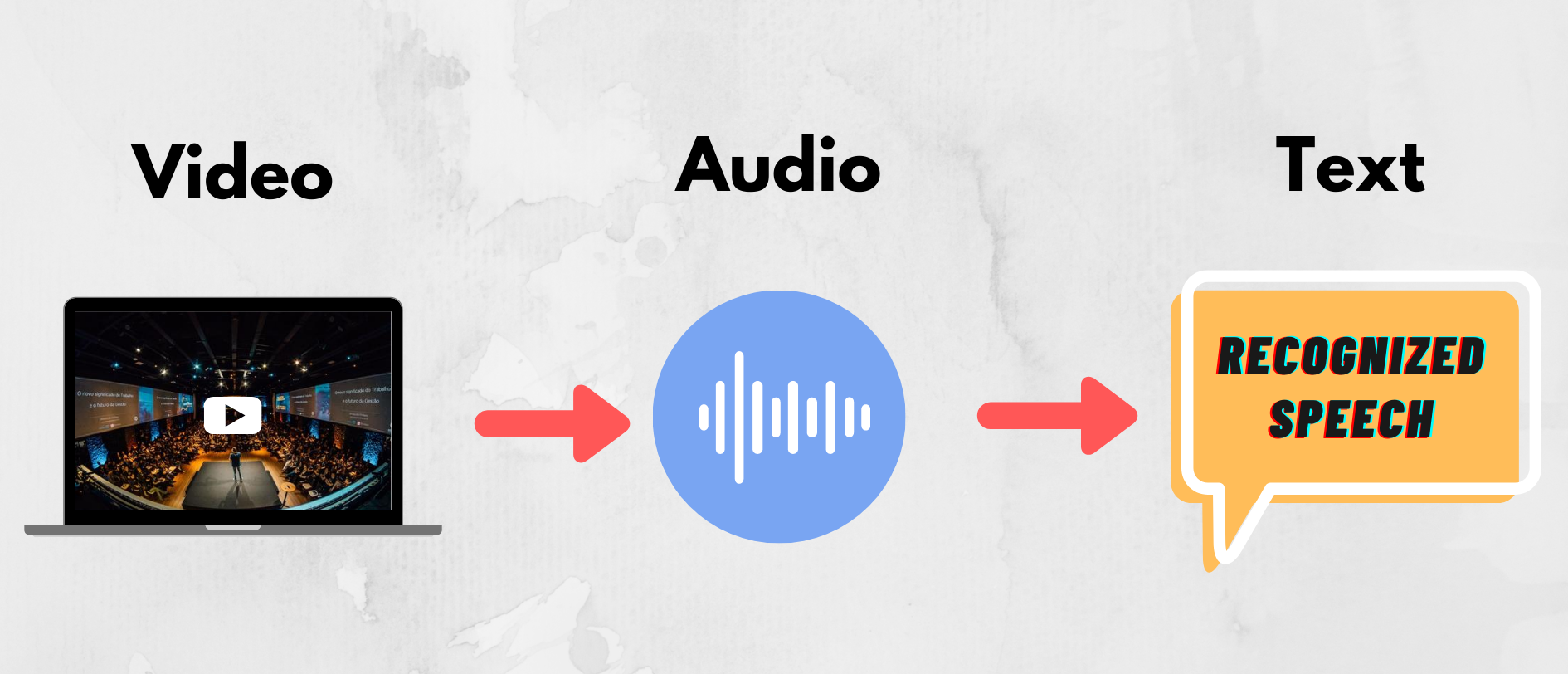
In this post, I will show you how to extract speeches from a video recording file. After recognizing the speeches we will convert them into a text document. This will be a simple machine learning project, that will help you to understand some basics of the Google Speech Recognition library. Speech Recognition is a popular topic under machine learning concepts. Speech Recognition is getting used more in many fields. For example, the subtitles that we see on Netflix shows or YouTube videos are created mostly by machines using Artificial Intelligence. Other great examples of speech recognizers are personal voice assistants such as Google’s Home Mini, Amazon Alexa, Apple’s Siri.
在本文中,我将向您展示如何从视频录制文件中提取语音。 识别语音后,我们会将其转换为文本文档。 这将是一个简单的机器学习项目,它将帮助您了解Google语音识别库的一些基础知识。 语音识别是机器学习概念下的热门话题。 语音识别在许多领域得到越来越多的使用。 例如,我们在Netflix节目或YouTube视频上看到的字幕主要是由使用人工智能的机器创建的。 语音识别器的其他出色示例还包括个人语音助手,例如Google的Home Mini,亚马逊的Alexa,苹果的Siri。
目录: (Table of Contents:)
Getting Started
入门
Step 1: Import Libraries
步骤1:导入库
Step 2: Video to Audio Conversion
第2步:视频到音频的转换
Step 3: Speech Recognition
步骤3:语音识别
Final Step: Exporting Result
最后一步:导出结果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1903
1903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









