



在数据仓库里对于数据的加工一直有一个很有意思的话题,就是ETL和ELT,我记得零几年那会儿,刚开始有商业智能或者数据仓库概念的时候,只有ETL,直到后来行业逐渐成熟了起来,才又有了ELT的概念。
他们到底是怎么回事从技术角度来解释的方法很多,最近在Linkedin上看到一个图,很有意思,大体如下:
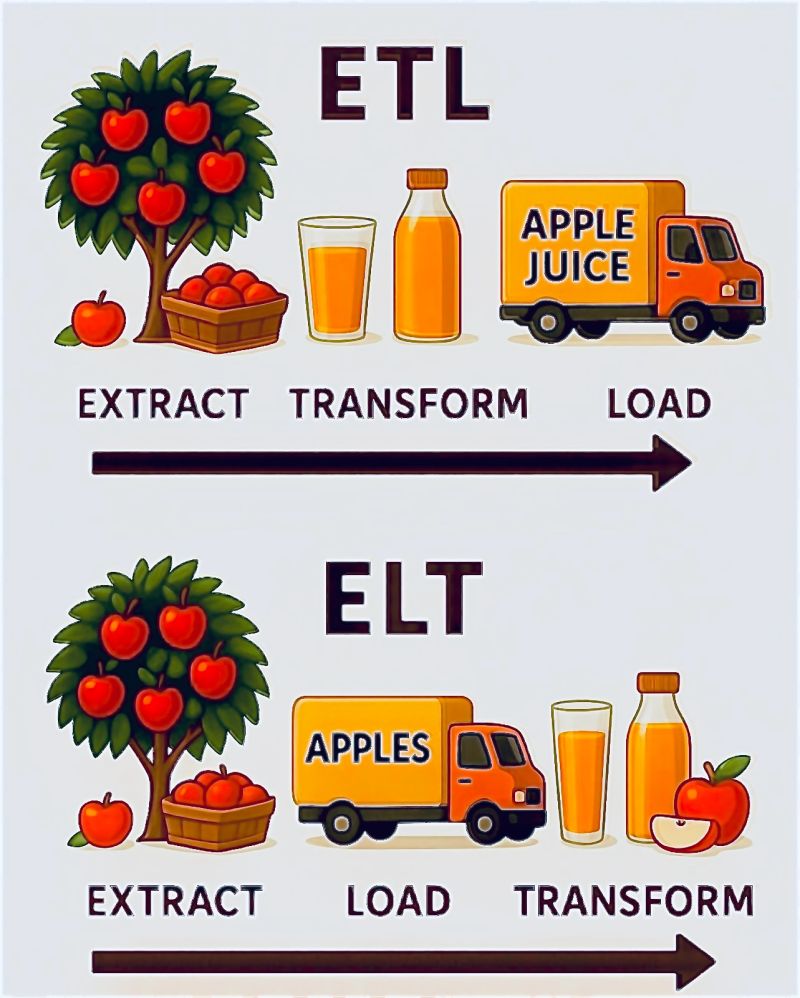
技术领域的理解
这个图片生动的展示了ETL和ELT的区别,也就是你是把水果加工成果汁之后拿去卖,还是把水果运走之后再找地方加工成果汁之后然后拿去卖。
在我们的实际的数据仓库项目中,对应的区别就是,你要去获取的数据,是先原封不动的拿过来,还是拿过来的时候就做好相应的转换。
现实世界中的理解以及问题的提出
我很喜欢这个图,所以在我朋友圈发了出来,很多朋友都看到了,都对这种解释方式很认可,包括我媳妇,虽然她不是做数据方面的,但是她作为一个领域外的人居然看懂了。
不过她的一个问题很有意思,就是什么情况下应该选择前者,什么情况下选择后者呢?
所以在我们数据仓库的建设中,实际上就是根据项目规模的大小来决定,如果是个小型的项目,那么就ETL,如果是大型项目那么就ELT.
所以回到现实世界,回到这个图,就是取决于水果厂的规模,如果只是村里的小规模简单加工,都是农户自己家采摘自己家地里的水果并且自己加工的,比如老张家的果汁,老李家的果汁。
但如果你是一个国内比较大的水果厂,通常这些大厂会在水果产地建立一个比较大的工厂,他们不会从老张家或者老李家去收购果汁,而是会从不止老李家或者老张家去收购水果,把村里镇里或者市里所有的水果都收购了,统一加工处理。这样才能保证产量的基础之上,提高生产效率。而老张家和老李家也不用担心每年的水果和自产的果汁都卖给谁。
关于ETL和ELT的进一步衍生
在数据仓库领域中,后续除了从ETL衍生出了ELT,实际也衍生出过更进一步的方法,比如ETLT,也就是在数据E之后先进行一个T,专注于数据的标准化处理,或者是异构数据的处理。对应到果汁的故事里,就好比在地方工厂里我收集到水果,先把水果加工成浓缩果汁,然后再送给下一步的工厂,加工或者还原成果汁,比如混合型果汁,这种方式应该是目前最主流的方式。当然这又涉及到了原榨果汁和浓缩果汁的区别,讨论起来除了成本和市场占有量之外仍是一个非常复杂的话题,这里超出了本文的范围所以不过多讨论。
关于本文的一些补充:
由于最近在做跟AI相关的事,以前没接触的时候没指望它能帮助太多,但是逐渐了解并且看身边的人使用之后才发现这个东西有时候真的能帮你打开一扇窗。
比如对于这个果汁加工问题的理解,刚开始我以为大厂都是从全国收集水果然后到国内某一个加工大厂一起护理的,经过字节旗下的豆包查询后,我了解到原来大厂不是这么操作的,并且进一步了解到他们都是在产地周边建厂,以减少水果在运输中产生的损耗。所以为了严谨我修改了现实世界中故事的讲述方式。
当然在我对我的理解不是100%确定正确的情况下,我也会在豆包里问ETL和ELT的区别,豆包会汇总它所收集到的信息帮我提炼出区别,让我快速理解,好判断出我描述的方式是否有很大的偏差。
经过这个写作的过程,我们可以看到AI确实是可以帮助我们解决一些特定的问题,而实际了解下不难发现,实际很多人都已经开始这么工作了,原来自己被时代落下了这么远的距离。
所以无论如何,即使你不从事AI方面的工作,我也建议你了解下AI工具,比如我提到的字节旗下的豆包,真的是一个很亲民的平台,没有那么多的门槛,直接拿来用就行。
当然如果你是一个程序员,你也可以了解下字节旗下的AI代码助手,通过博客园顶部的链接就可以了解到,用赵本山的话说:谁用谁知道。


















 1352
1352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









