






近日,阿里云人工智能平台PAI与阿里集团安全部内容安全算法团队、华东师范大学何晓丰教授团队合作,在自然语言处理顶级会议ACL2024上发表论文《On the Role of Long-tail Knowledge in Retrieval Augmented Large Language Models》,论文主题为长尾知识检索增强的大语言模型。通过将问题识别为普通可回答和长尾两种性质,让大模型针对性的对长尾问题进行检索文档增强。对于普通可回答的用户提问可以直接通过大模型回答,而不需要进行文档检索增强,从而能增强大模型处理不同类型用户提问的效率。
背景
尽管大型语言模型展现了卓越的性能,在应对诸如产生幻象、依赖陈旧信息及进行不透明且难以追溯的推理过程等难题时仍面临挑战。作为应对这些局限性的新兴策略,检索增强生成(RAG)技术通过融入外部知识数据库,显著增强了模型在处理知识要求高的任务时的精确度与可靠性,确保了知识的及时更新与特定领域信息的融合。RAG体系本质上结合了大型预训练语言模型的内在知识与大规模动态外部数据资源,其核心包括三个步骤:Retrieval、Augmentation和Generation。这一机制利用外部知识库检索最新信息,以此“增强”模型能力,进而生成更为精准的答案,通过在生成内容前查询并整合外部来源信息以构造更加全面的输入提示,极大提升了生成结果的准确度与关联性。然而,当前RAG方法只专注于通过不加区别地使用检索到的信息增强查询来提高LLM的响应质量,而很少关注LLM真正需要什么类型的知识才能更准确地回答原始查询。
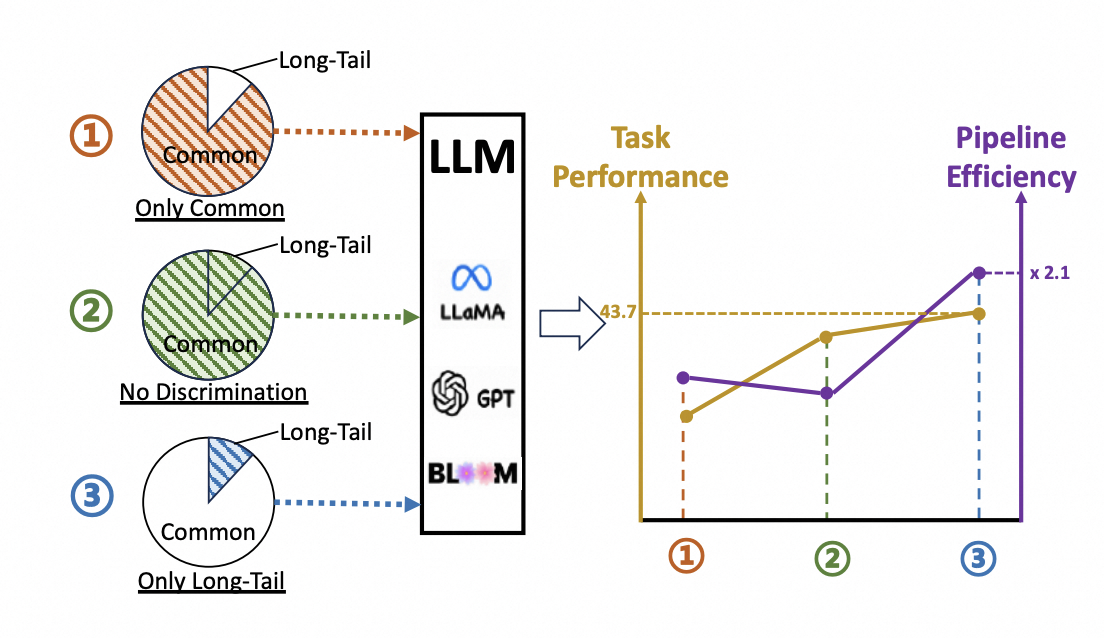
大模型查询中不同知识类型对提升性能和效率的影响
为了进一步解决RAG在LLM回答时遇到的回答效率和检索知识源的问题,提出对问题查询类型进行识别算法来提升LLM推理的效率是必要的。我们将大模型提问所需知识进行了分类,包含了长尾知识,普通知识和两者都有的知识。将该查询输入到大模型中进行区分,发现对于大模型来说,其实不需要将所有对应的知识都召回,只需要对已有的长尾Query部分进行知识召回增强大模型理解能力即可,大模型的性能和处理查询的效率也会快很多。
算法概述
长尾检测指标ECE
之前传统的工作依赖文本频率来判断实例是否长尾。因此,低频文本往往被归类为长尾类。对于LLM来说,计算以前未知用户查询的文本频率难度较大。预期校准误差(ECE)为测量“长尾”提供了新的视角。ECE测量模型的估计概率与真实(观测)概率的匹配程度。在ECE的计算中,将每个样例的置信度分配到一个特定的区间内,由模型的预测概率得到。准确度由预测标签与实际标签真值的比较确定。每个样本的置信度和准确度之间的绝对差值表示校准度。整个数据集的期望校准度表明了模型的可靠性。形式上,ECE可表述为:
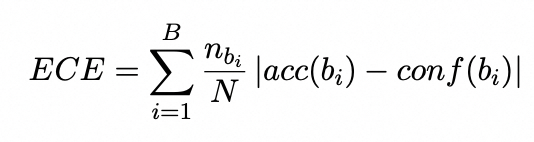
其中i表示第i个bin,N为数据集的样例总数,acc(b_i) 和conf(b_i)表示bin的准确度和置信度,n{b_i}为bin的实例数,B为区间[0,1]内的bin数。在我们的模型中,由于ECE是计算机视觉领域针对长尾判断提出的,我们将ECE扩展到自然语言处理领域,特别是LLM文本生成场景。
基于度量的长尾检测
我们用MENTOR和平均预测概率对传统的ECE公式进行了转换:
- ECE的准确性是衡量预测与标准答案之间的一致性。在生成场景中,我们使用METEOR来衡量预测候选和标准答案之间的一致性和相关性。
- ECE的置信度是模型本身产生的预测概率。同样,我们使用LLMs输出的平均token概率。
此外,为了增强长尾检测的度量能力,我们进一步集成了以下两个因素,有助于我们进一步分离常见sample和长尾sample之间的关系:
- 平均词频,因为词频是长尾文本的基本指标。
- 利用总数据集的平均梯度和特定sample梯度之间的点积来评估差异。该操作是因为长尾实例的梯度与整个数据集的平均梯度相差很大,反之亦然。
从上述算法分析,我们得出GECE指标如下:
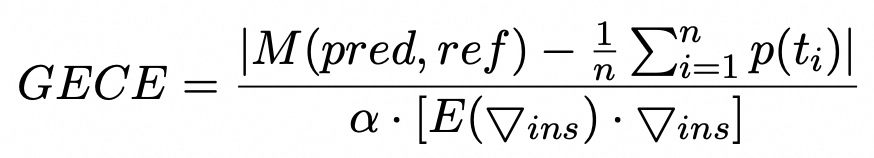
其中pred和ref分别表示生成的文本和引用的基本事实。M(pred,ref)是METEOR得分,p(t_i)表示由LLM产生的第i个token的概率,n是token序列长度。 对于分母部分,α是平均词频。我们可以看到,长尾实例的α值较小,因此其倒数将较大。较大的GECE值意味着更高的长尾识别准确度。例如,我们将GECE应用于NQ数据集“谁被评为2014年度非洲足球先生”的查询,值为34.6。而对于长尾、更专业的NQ查询“谁在歌剧魅影中扮演过拉乌尔”,GECE值为112.7。
RAG Pipeline扩展
作为对普通RAG pipeline的扩展,我们只从数据源检索与长尾查询相关的文档,而不考虑通用sample。检索过程由密集检索器实现,以检索相关的WikiPedia文档。对于长尾实例,我们将与调用的相关文档连接的查询输入LLMs以获得答案。对于通用sample,我们只将查询本身输入到LLMs。
算法评测
为了更好的评估基于该长尾数据识别增强的RAG方法,我们选取了多个知识覆盖场景的公开数据集进行评测,模型效果如下图所示,同时,我们对GECE只针对长尾实体进行识别进行了充分的时间效率评估,效果如下。
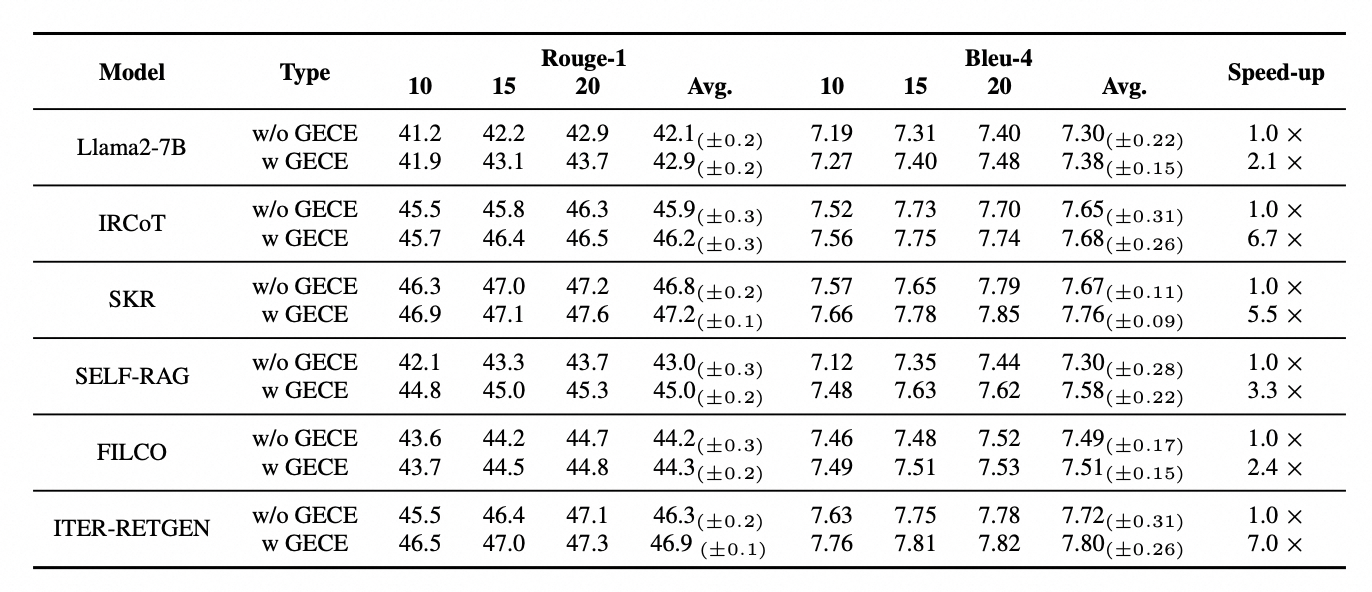
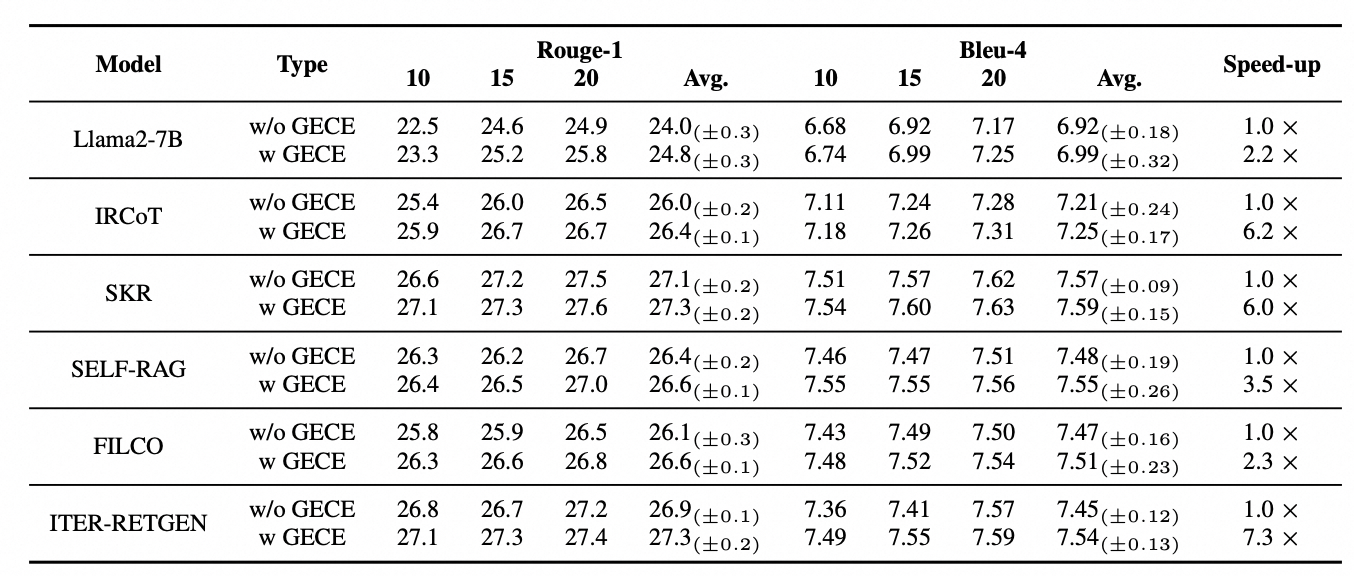
我们发现在相关baseline算法基础上,加入GECE扩展模块不仅仅提高了在各个知识密集型数据集上的效果,同时由于过滤掉一些涉及通用知识的Query,模型执行数据的速度也随之提高。
参考文献
- Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2023. Self-rag: Learning to retrieve, generate, and critique through self-reflection. CoRR, abs/2310.11511
- Satanjeev Banerjee and Alon Lavie. 2005. METEOR: an automatic metric for MT evaluation with improved correlation with human judgments. In ACL, pages 65–72.
- Zhangyin Feng, Xiaocheng Feng, Dezhi Zhao, Maojin Yang, and Bing Qin. 2023. Retrieval-generation synergy augmented large language models. CoRR, abs/2310.05149.
- Gautier Izacard, Patrick S. H. Lewis, Maria Lomeli, Lucas Hosseini, Fabio Petroni, Timo Schick, Jane Dwivedi-Yu, Armand Joulin, Sebastian Riedel, and Edouard Grave. 2023. Atlas: Few-shot learning with retrieval augmented language models. J. Mach. Learn. Res., pages 251:1–251:43.
- Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, and Colin Raffel. 2023. Large language models struggle to learn long-tail knowledge. In ICML, pages 15696–15707.
论文信息
论文名字:On the Role of Long-tail Knowledge in Retrieval Augmented Large Language Models
论文作者:李东阳,严俊冰,张涛林,汪诚愚,何晓丰,黄龙涛,薛晖,黄俊
论文pdf链接: https://arxiv.org/pdf/2406.16367
阿里云人工智能平台PAI长期招聘研究实习生。团队专注于深度学习算法研究与应用,重点聚焦大语言模型和多模态AIGC大模型的应用算法研究和应用。简历投递和咨询:chengyu.wcy@alibaba-inc.com。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









