







DolphinDB提供了多种灵活的数据导入方法,来帮助用户方便的把海量数据从多个数据源导入。具体有如下4种途径:通过文本文件导入
通过二进制文件导入
通过HDF5接口导入
通过ODBC接口导入
1. DolphinDB数据库基本概念和特点
本章中多处使用到DolphinDB的数据库和表的概念,所以这里首先做一个介绍。
在DolphinDB里数据以结构化数据表的方式保存。数据表按存储介质可以分为:内存表:数据保存在内存中,存取速度最快,但是若节点关闭就会丢失数据。
本地磁盘表:数据保存在本地磁盘上,即使节点关闭,也不会丢失数据。可以方便的把数据从磁盘加载到内存。
分布式表:数据分布在不同的节点的磁盘上,通过DolphinDB的分布式计算引擎,逻辑上仍然可以像本地表一样做统一查询。
按是否分区可以分为:普通表(未分区表)
分区表
在传统的数据库系统,分区是针对数据表定义的,就是同一个数据库里的每个数据表都可以有自己的分区定义;而DolphinDB的分区是针对数据库定义的,也就是说同一个数据库下的数据表只能使用同一种分区机制,这也意味着如果两张表要使用不同的分区机制,那么它们是不能放在一个数据库下的。
2. 通过文本文件导入
通过文件进行数据中转是比较通用化的一种数据迁移方式,方式简单易操作。DolphinDB提供了以下三个函数来载入文本文件:loadText函数相比,速度更快。
以下为将candle_201801.csv导入DolphinDB来演示loadText和loadTextEx的用法。
2.1 loadText
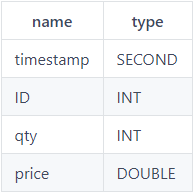
loadText函数有三个参数,第一个参数filename是文件名,第二个参数delimiter用于指定不同字段的分隔符,默认是",",第三个参数schema是用来指定导入后表的每个字段的数据类型,schema参数是一个数据表,格式示例如下:
首先导入数据:dataFilePath = "/home/data/candle_201801.csv"
tmpTB = loadText(dataFilePath);
DolphinDB在导入数据的同时,随机提取一部分的行以确定各列数据类型,所以对大多数文本文件无须手动指定各列的数据类型,非常方便。但有时系统自动识别的数据类型并不符合预期或需求,比如导入数据的volume列被识别为INT类型, 而需要的volume类型是LONG类型,这时就需要使用一个数据类型表作为schema参数。例如可使用如下脚本构建数据类型表:nameCol = `symbol`exchange`cycle`tradingDay`date`time`open`high`low`close`volume`turnover`unixTime
typeCol = `SYMBOL`SYMBOL`INT`DATE`DATE`INT`DOUBLE`DOUBLE`DOUBLE`DOUBLE`INT`DOUBLE`LONG
schemaTb = table(nameCol as name,typeCol as type);
当表字段非常多的时候,写这样一个脚本费时费力,为了简化操作,DolphinDB提供了
整合上述方法,可使用如下脚本以导入数据:dataFilePath = "/home/data/candle_201801.csv"
schemaTb=extractTextSchema(dataFilePath)
update schemaTb set type=`LONG where name=`volume tt=loadText(dataFilePath,,schemaTb);
2.2 ploadText
ploadText函数的特点可以快速载入大文件。它在设计中充分利用了多核CPU来并行载入文件,并行程度取决于服务器本身CPU核数量和节点的localExecutors配置。
首先通过脚本生成一个4G左右的CSV文件:filePath = "/home/data/testFile.csv"
appendRows = 100000000
dateRange = 2010.01.01..2018.12.30
ints = rand(100, appendRows)
symbols = take(string('A'..'Z'), appendRows)
dates = take(dateRange, appendRows)
floats = rand(float(100), appendRows)
times = 00:00:00.000 + rand(86400000, appendRows)
t = table(ints as int, symbols as symbol, dates as date, floats as float, times as time)
t.saveText(filePath)
分别通过loadText和ploadText来载入文件。本例所用节点是4核8超线程的CPU。timer loadText(filePath);
Time elapsed: 39728.393 ms
timer ploadText(filePath);
Time elapsed: 10685.838 ms
结果显示在此配置下,ploadText的性能是loadText的4倍左右。
2.3 loadTextEx
loadText函数总是把所有数据导入内存。当数据文件体积非常庞大时,服务器的内存很容易成为制约因素。DolphinDB提供的;loadTextEx函数可以较好的解决这个问题。它将一个大的文本文件分割
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









