







Downloader Middleware处理的过程主要在调度器发送requests请求的时候以及网页将response结果返回给spiders的时候,所以从这里我们可以知道下载中间件是介于Scrapy的request/response处理的钩子,用于修改Scrapy request和response。
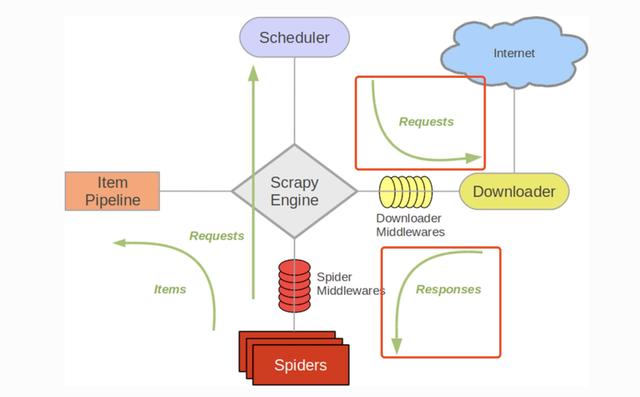
编写自己的下载器中间件
编写下载器中间件,需要定义以下一个或者多个方法的python类
为了演示这里的中间件的使用方法,这里创建一个项目作为学习,这里的项目是关于爬去httpbin.org这个网站
scrapy startproject httpbintest
cd httpbintest
scrapy genspider example example.com
创建好后的目录结构如下:
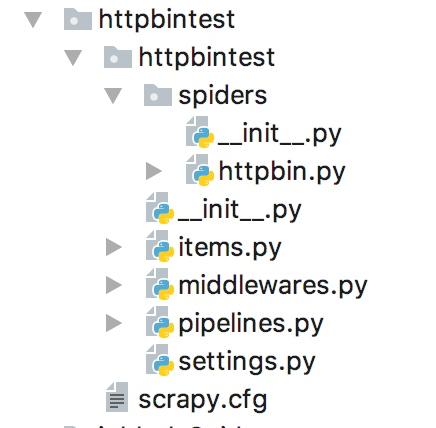
这里我们先写一个简单的代理中间件来实现ip的伪装
创建好爬虫之后我们讲httpbin.py中的parse方法改成:
def parse(self, response): print(response.text)然后通过命令行启动爬虫:scrapy crawl httpbin
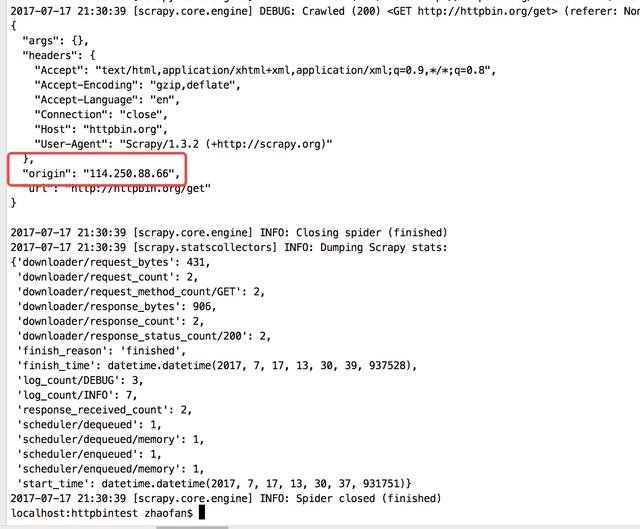
在最下面我们可以看到"origin": "114.250.88.66"
我们在查看自己的ip:
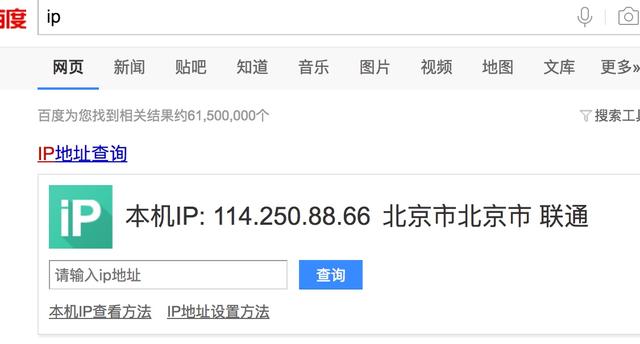
而我们要做就是通过代理中间件来实现ip的伪装,在middleares.py中写如下的中间件类:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 6880
6880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









