






在计算机中,由于数据的形式,数量和保存形式不同,对数据进行排序的方法也不同.按照排序过程中数据保存的形式不同,分为内部排序和外部排序两大类.
内部排序:
整个排序过程中不需要访问外存:
1. 交换排序: 冒泡排序,快速排序
2. 选择排序: 直接选择排序,堆排序
3. 插入排序: 直接擦汗如排序,希尔排序
4. 合并排序
外部排序:
在适用内部排序的时候,所有待处理的数据都已经调入计算机内存,在排序操作中可以直接使用,但是计算机内存容量是有限的,当对大批量的数据进行排序的时候,不可能一次性将数据全部转入内存,这时可见外存中的数据读取一部分到内存,将内存中的数据排序之后,再存储到外存中,然后再在外存中读取下一部分需要排序的数据. 这样排序数据在内存和外存之间多次数据交换,达到排序整个数据的目的,这就是外部排序

冒泡排序
是一种对相邻数据进行数据交换的排序方法,时间复杂度:O(n2)
基本思想:对关键字逆序从下往上不断扫描,当发现相邻两个关键字的次序与排序规则要求的不一致的时候,将这两个记录进行交换。就像水泡上升一样。
存在问题:当排序已经满足规则了,但是循环还没完,程序并不知道后面的数据是不是有序的,那么就会造成浪费。
改进方法:就是在每一次循环的时候,检查这一次循环的过程是否发生了数据交换,如果没有就直接退出整个循环,这里就用flag这个变量来表示是否发生了数据交换,这就实现了用空间来换取时间的目的。
快速排序(nlog(n)-n2)
快速排序是对冒泡排序的另外一种改进,其思想是:通过一遍排序将要排序的数据划分为两部分,其中一部分数据比另外一部分小,然后再对这两部分分别再进行类似的排序,一直到每一部分都只剩下一个数或者为空的时候,整个排序算法就结束。
思想精华:用到了二分以及分治的思想,可以将大批的数据逐步分解。
具体步骤:
快速排序要进行的第一步,也是最重要的一步就是将数组先分成两部分,一部分数据比另一部分大或者小。
首先对一组无序的数组,随便选取一个元素作为基准值,一般都选第一个(下标为0)。
然后从后向前对每一个元素和这个基准元素进行比较,知道找到一个比基准元素小的元素,则将这个元素和基准元素的位置互换(这就有点像冒泡排序里面的操作了)。
接下来就就从数组的开头向后,将每个元素和基准元素相比,找到第一个大于基准元素的值与其交换位置。(这里是不可能找到刚才调换后的基准值的位置之后的,因为已经确定了基准值之后的已经是小于基准值的了,所以这次从前往后,只要找到比基准值大的就和基准值交换位置,也是为了保证在基准值的后面的元素都比基准值大,在基准值前面的元素都比基准值小)。
上面两步就可以将这个无序的数组分成了两部分,但是这样子仅仅满足了一边大一边小。所以对这两部分分别再进行以上操作。
简单选择排序算法
这个算法思路和实现都比较简单,就是首先从数据中选择一个最小的数据和第一个数据进行交换,接下来就从剩下来的数据中执行刚才一样的操作。
堆排序算法(nlog(n))
它也是一种选择排序算法。这个算法利用到了堆的特性。
什么是堆?
堆其实就是一个完全二叉树,树中每个节点对应原始数据的一个记录,并且每个节点满足一下条件:非叶子节点的数据大于或者等于左右子节点的数据。根据堆的定义,根节点是最大值。所以堆排序的过程分为两步:
1. 将无序的数据构成堆
2. 利用堆排序

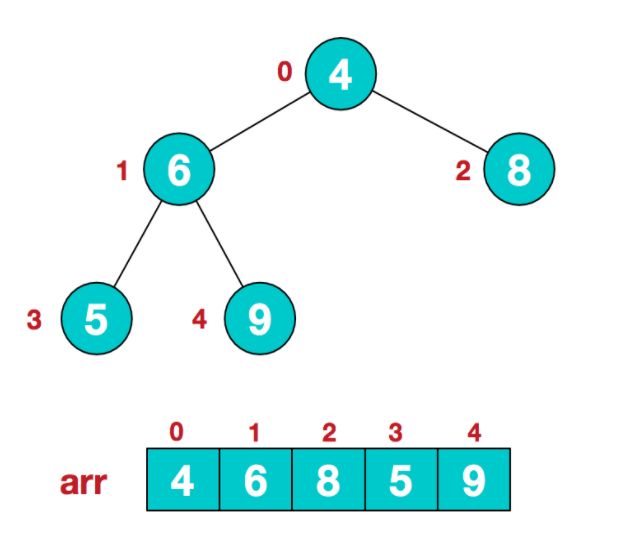
对于一颗完全二叉树来说,可以用数组的的下标来表示其在二叉树中的位置,对于任意节点i,只要不是根节点,其父节点编号为i/2,其左子节点的编号为2i+1,右子节点编号为2i+2.给一个图可能看得更清楚。
.
可以看到如果用数组的下标来表示其在完全二叉树中的位置的时候,相邻下标的数组元素并一定是在二叉树中位置相邻。理解这一点很重要。
堆排序算法的第一步就是要改造将一组数组数据构成堆,堆的定义也说过了,就是对于任何一个非叶子节点,其值要大于或者等于左右子节点。
步骤就是:
1) 从第一个非叶子节点(n/2-1),比较这个节点的左右子节点的大小,如果有子节点大的话,就用根节点(当前节点)和(当前节点的)右子节点进行比较。
2) 如果有子节点比根节点大的话,则就替换根节点和右子节点的位置。
3) 但是这样的话就影响了原来右子节点作为根节点的那一个堆,那么就需要对这个堆重新整理。
构造好堆之后,利用根节点是最大值的原理,将根节点和末尾元素替换,并将根节点存在数组的最后。
下面是各个算法的实现
#include#include#includeint Rand(int arr[],int n,int start,int end){
int flag,i,j;
srand(time(NULL));//随机数生成器初始化函数
if(end-start+1i;j--){
//如果相邻两个数 的排序规则不满足要求的话就替换
if(arr[j]>arr[j-1]){
tmp=arr[j];
arr[j]=arr[j-1];
arr[j-1]=tmp;
}
}
}
end=time(NULL);
printf("我用时%d",end-now);
}
//冒泡排序的改进算法
void Bubble_Pro(int arr[],int n){
int i,j,tmp,flag;
time_t now,end;
now=time(NULL);
for(i=0;ii;j--){
//如果相邻两个数 的排序规则不满足要求的话就替换
if(arr[j]>arr[j-1]){
tmp=arr[j];
arr[j]=arr[j-1];
arr[j-1]=tmp;
}
// flag来标志某次查询是不是进行了数据变换,这样的话就多用到了一个变量空间,就是以空间来换时间
flag=1;
}
if(flag==0)
break;
}
end=time(NULL);
printf("改进之后用时%d",end-now);
}
//快速排序算法 --数组切割
int Div(int arr[],int left,int right){
int base=arr[left];
while(leftbase)
--right;
arr[left]=arr[right];
while(left=0;i--){
//将arr[0]到arr[n-1]构成堆
Heap(arr,i,n);
}
for(i=n-1;i>0;i--){
t=arr[0];
arr[0]=arr[i];
arr[i]=t;
Heap(arr,0,i);
}
}
int main(){
int a[100];
Rand(a,10,0,9);
Print(a,10);
//printf("*********************快速排序之后********************************\n");
//Quick(a,0,9);
printf("*********************堆排序之后********************************\n");
Quick(a,0,9);
Print(a,10);
//对a数组进行冒泡排序
//printf("*********************冒泡排序之后********************************\n");
//Bubble(a,10);
}















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









