






在每天的结算跑批过程中,前面A应用会更新某些值,紧接着B应用就会去查询这批数据。但是,在某一天跑批的过程中,突然自动报警反馈,结算跑批异常。协同开发进行相关问题的跟踪排查,本来是秒级查询结果的任务,但是突然出现了超时好几分的情况,这是哪里的问题?
网络层进行了抓包
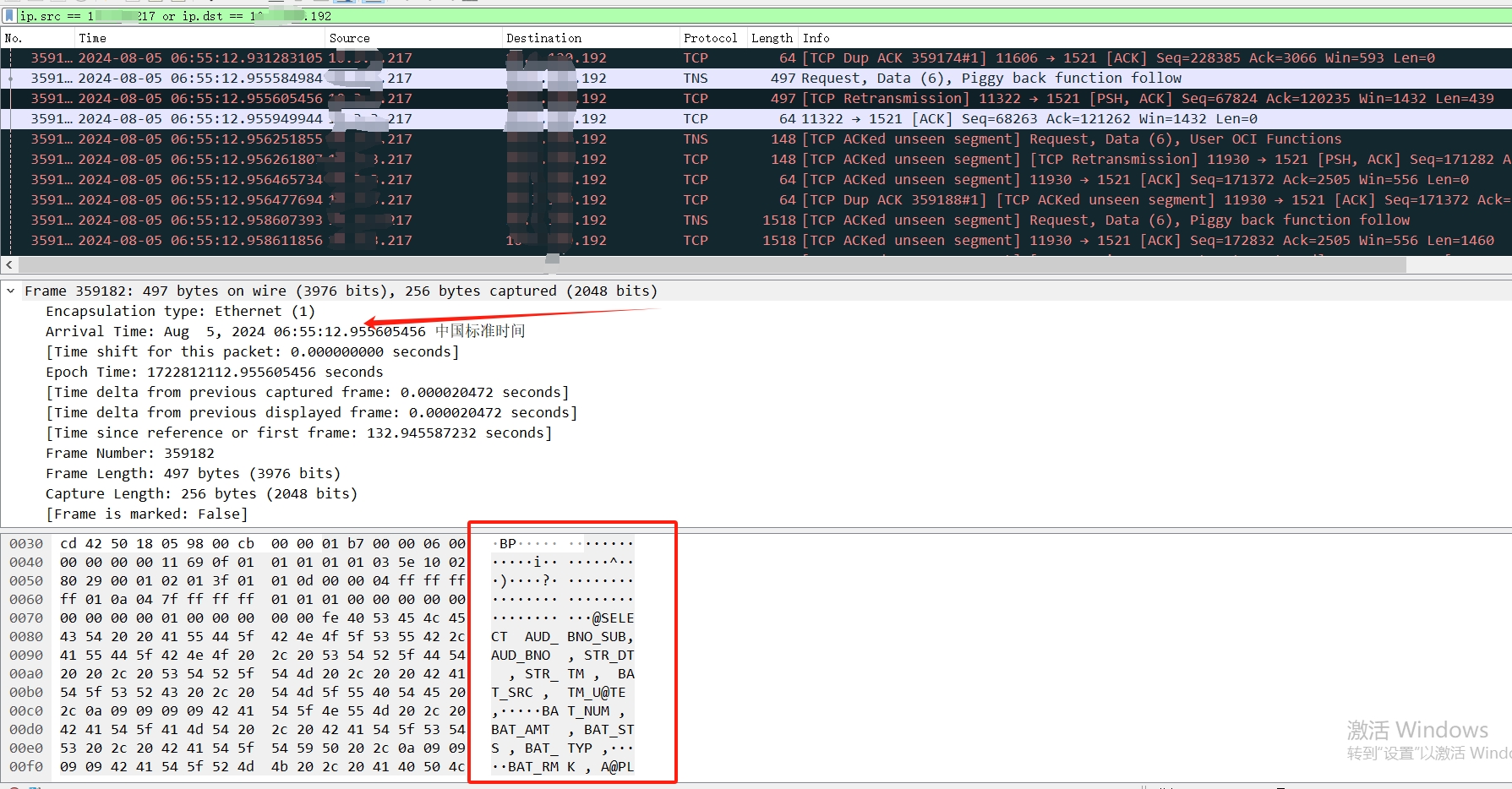
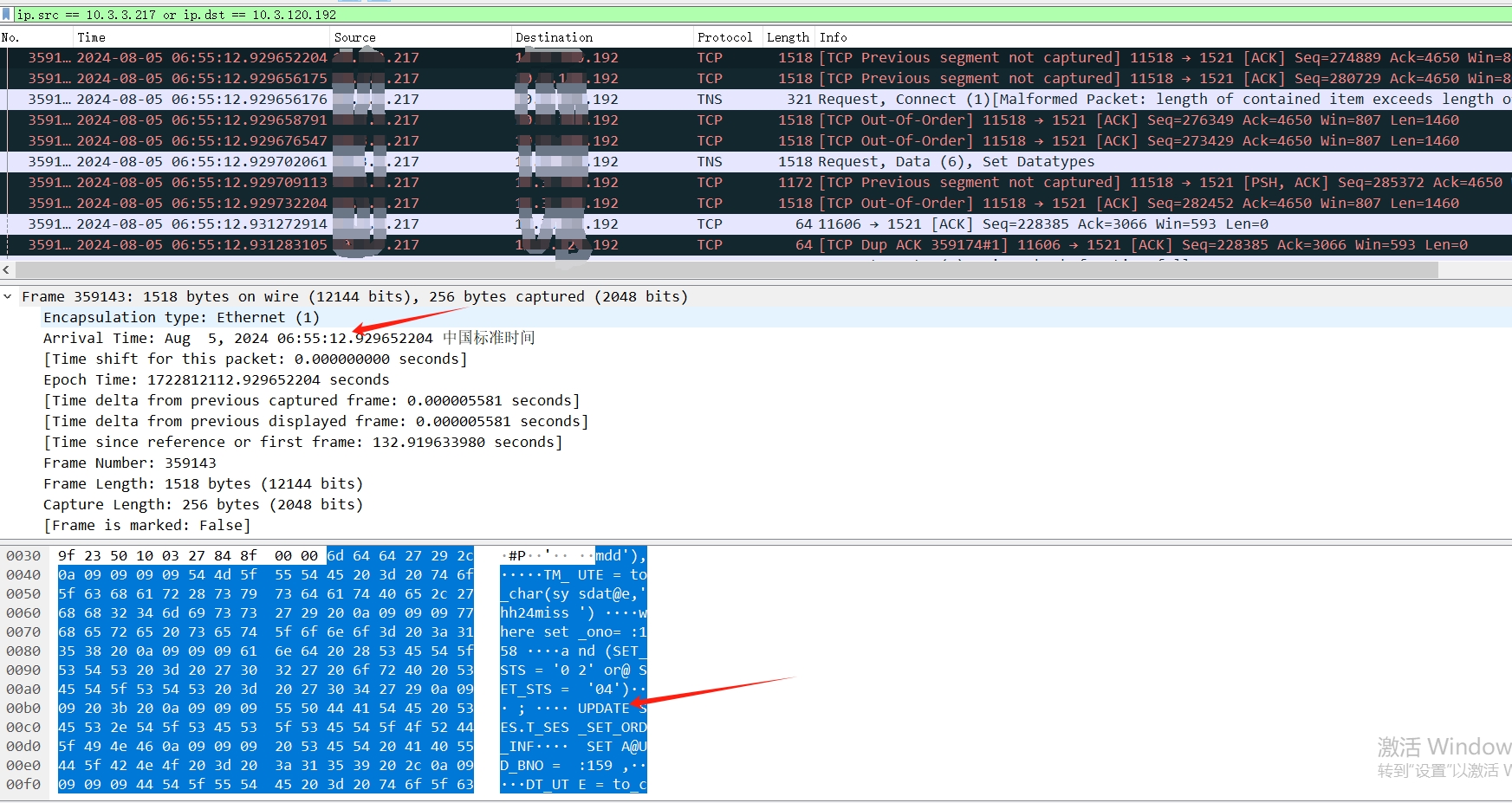
我们能看见开发所说的时间范围内的SQL。那么到底在数据库里面是如何的,我们使用logmner进行日志挖掘,这里说一下,当问题发生的时候,及时保留现场证据是最为重要的,比如当时的alert日志,crs日志,主机messages,osw日志,或者使用tfa及时进行相关证据数据的保留以备不时之需。
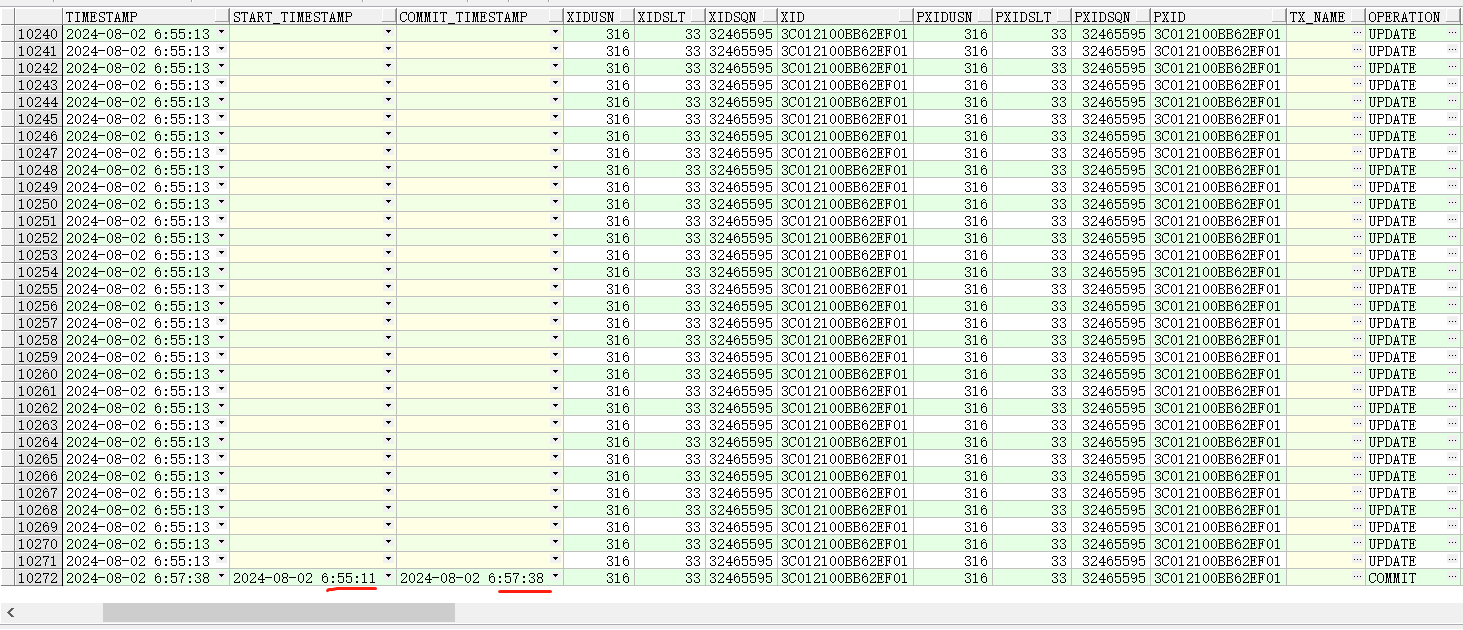
从上图我们可以看见,数据库开启事务时间是6:55:11秒、结束时间是6:57:38秒,相差2分钟。而开发给出的结果是,当前A事务在更新完成后,使用架构框架会自动提交,然后紧接着B应用,就会去查询,如果查询不到会走降级处理。2分钟查询不到怀疑是数据库的问题。
而DBA这里反复与开发沟通的是,库内确认提交的时间在2分钟后。为此陷入了扯皮环节或者在自证清白环节。这里我在重新把该事故进行相关梳理罗列:
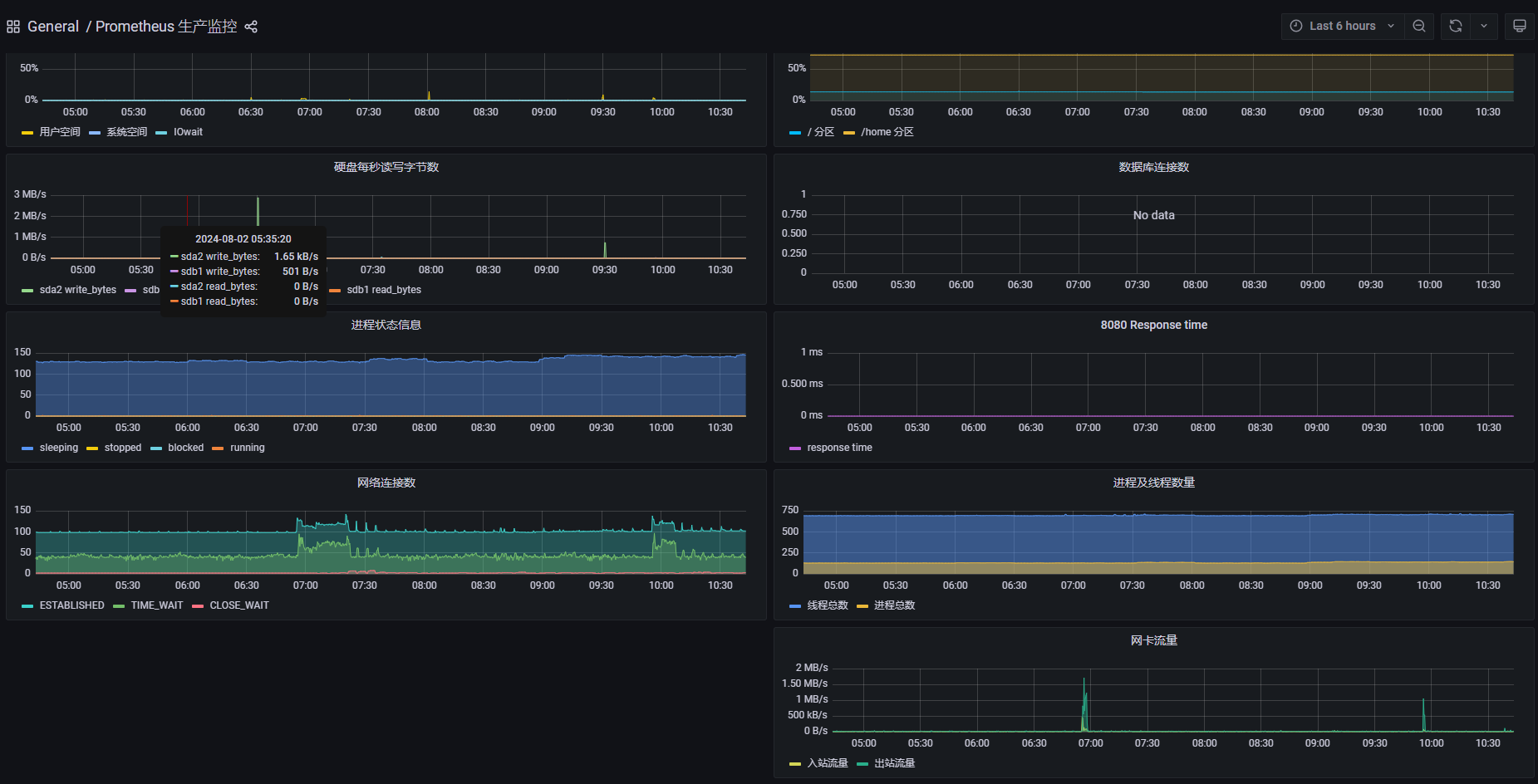
网络流量确实有凸起,找网络同事排查,该服务器确实有一些丢包问题。那么回归疑问,为啥51个事务,会是同一个XID?
让我们敬畏生产~保持一颗求真的心,by 2024年立秋绝日前~
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









