






本篇文章,继续来和大家分享与进程相关的知识。本篇文章主要内容是如何使用fork创建进程和进程的状态。
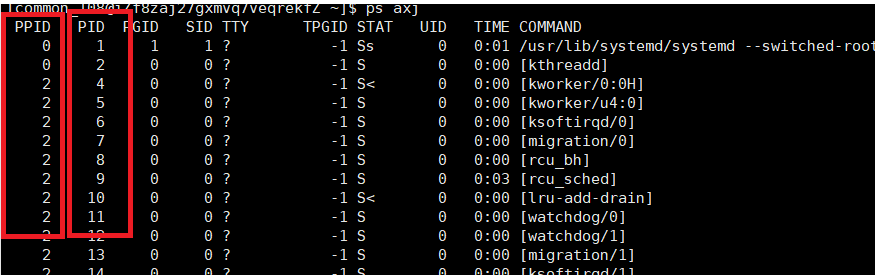
前面,我们了解了ps axj指令,可以查看系统中的运行的进程。
在显示的结果中,PPID表示父进程的PID,而PID就是子进程自身的PID,这个有点类似于学生的学号。
我们可以通过getpid和getppid这个两个函数来获取进程的PID和PPID。
getpid和getppid
这两个函数的功能很明显,一个用来获取pid,一个用来获取父进程pid。我们简单的写个程序和一个脚本来验证。
从监控脚本的结果看,它们两打印的结果是一样的。
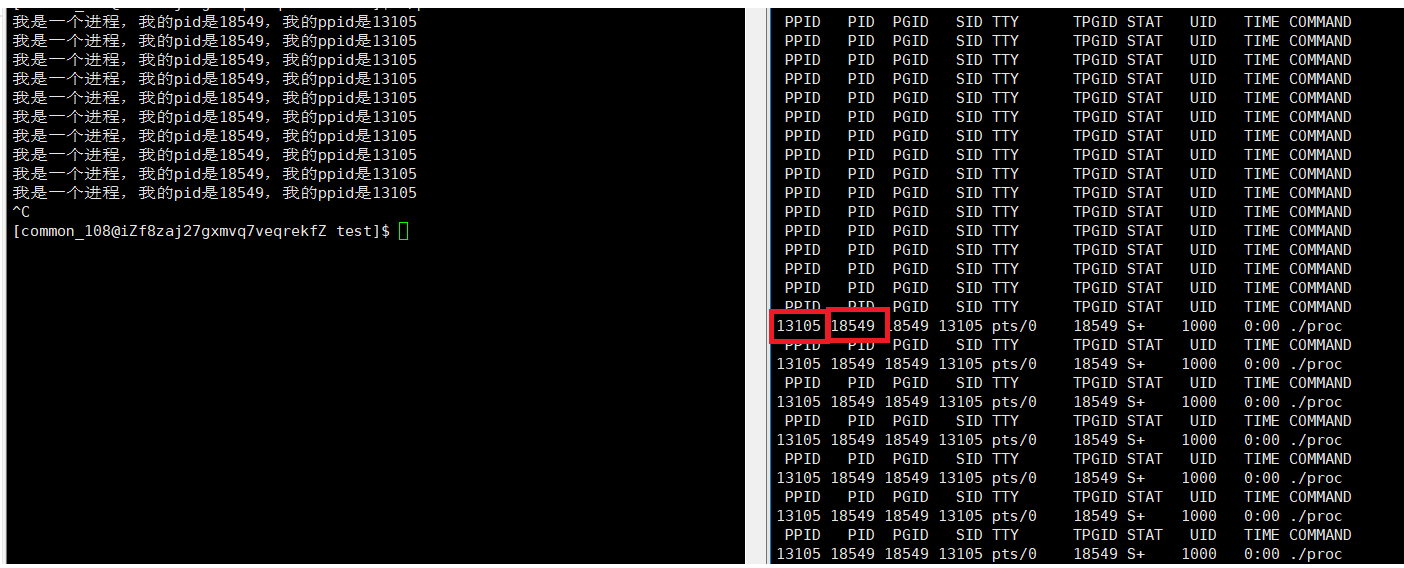
我们将程序重新启动,不难发现该程序的PID变了,但它的PPID没有变。依然是13105。这个是什么进程的PID呢?
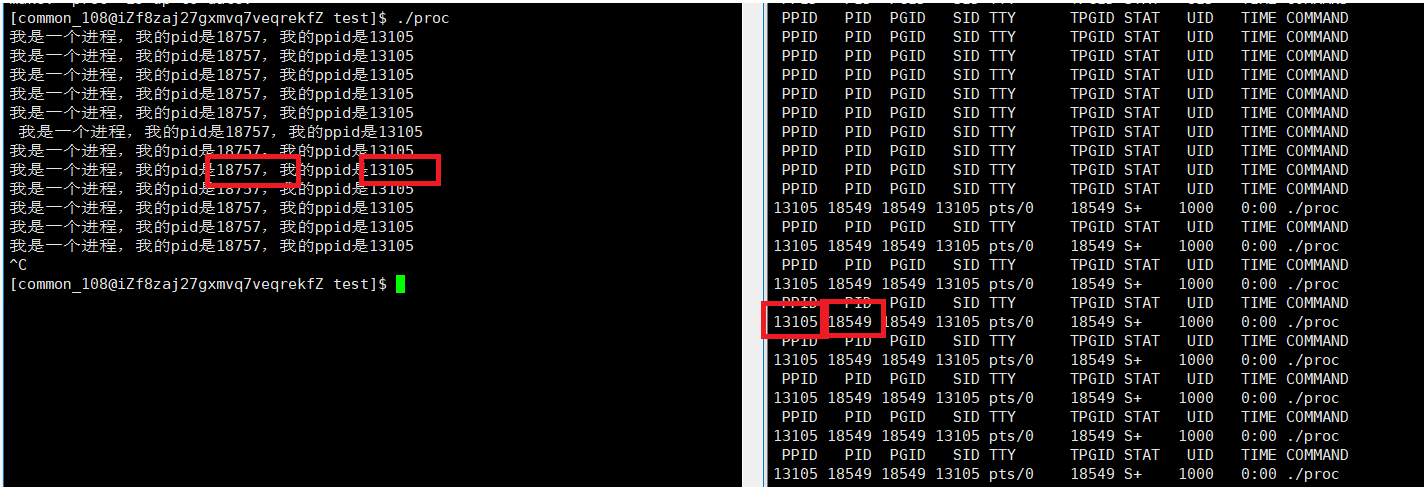
通过指令查询,我们可以看到这是bash命令行解释器的PID。只有在我们重启服务器的时候,它的PID才会变。

如果你细心观察的话,就会发现,我们输入的指令,都会变成一个进程来执行,而且这些进程的父进程都是bash。这是为什么?bash在收到你的指令后,会创建一个进程来执行你的指令。进程由谁创建,谁就是相应进程的父进程。那为什么bash不自己去执行指令,而是创建新的进程去执行呢?如果执行命令出错了,就不会影响bash的正常运行。
创建进程有两种方式,一种是执行指令,另一种是调用fork函数。
fork创建进程
fork函数在man手册第二章。它功能是创建一个进程。

该函数会有两个返回值,在父进程中它会返回子进程的PID,在子进程中它会返回0。

我们可以用if...else语句来做测试一下。
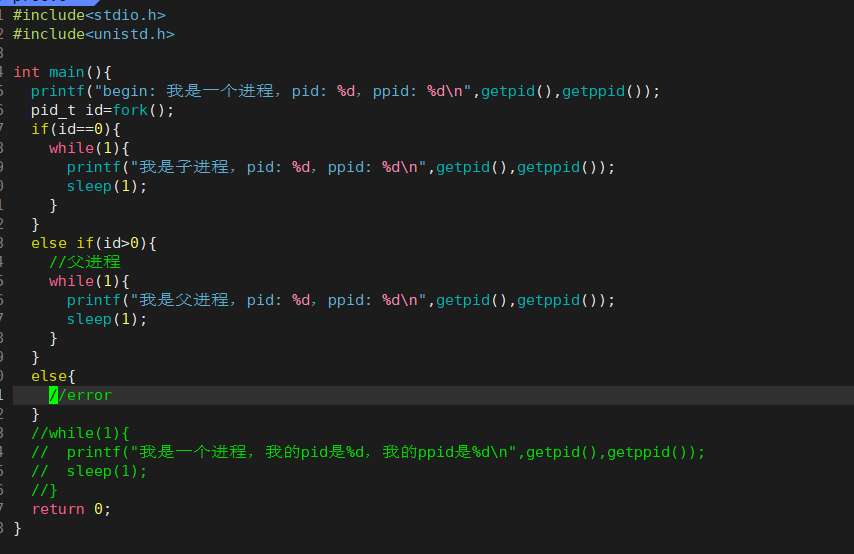
我们先来分析一下,程序会自上而下运行。如果fork存在两个返回值,则子进程进入第一个循环,打印自身信息。父进程进入第二个循环,打印自身的信息。
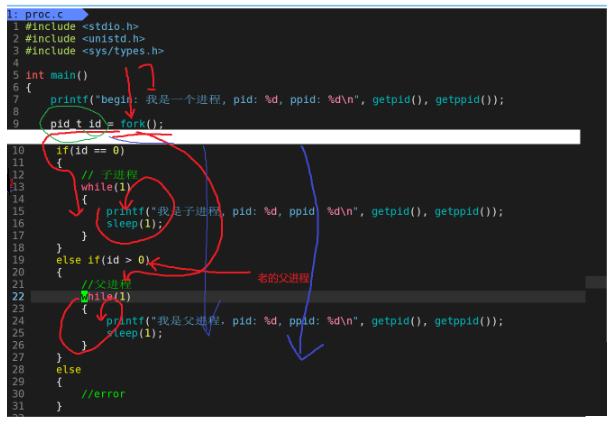
运行结果,和我们预期的一样。
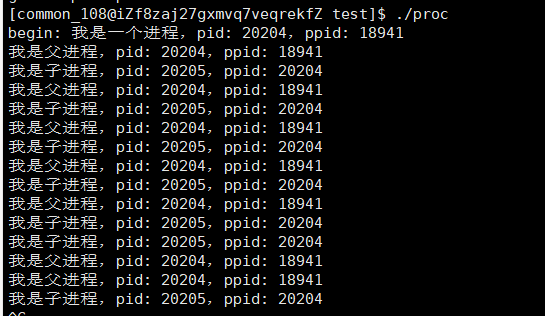
对于fork,有四个值得思考的问题:
第一个问题:为什么fork要给子进程返回0,给父进程返回子进程的PID?现在,我们只是创建了一个进程,将来我们可能会使用for循环来创建一堆的进程,我们该如何区分这些进程呢?通过进程的PID。返回不同的返回值,是为了区分不同进程,不同的执行流,执行不同的代码。
第二个问题:fork函数是如何做到返回两次的?fork本质也是个函数,在fork函数return之前,它已经把创建进程PCB,填充PCB对应内容,以及让父子进程指向同样的代码等核心工作都做完了。简单来说,就是此时子进程已经创建好了。这里有一个结论,我们需要知道,父子进程共享创建子进程位置的后续代码。
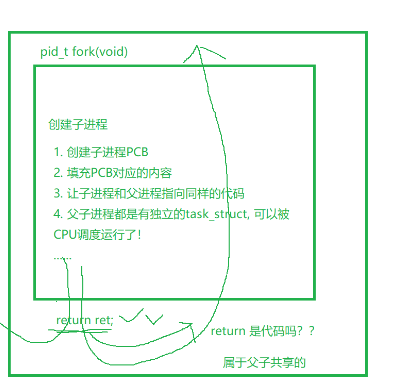
我们可以做一个简单的验证,将程序改成如下这样:
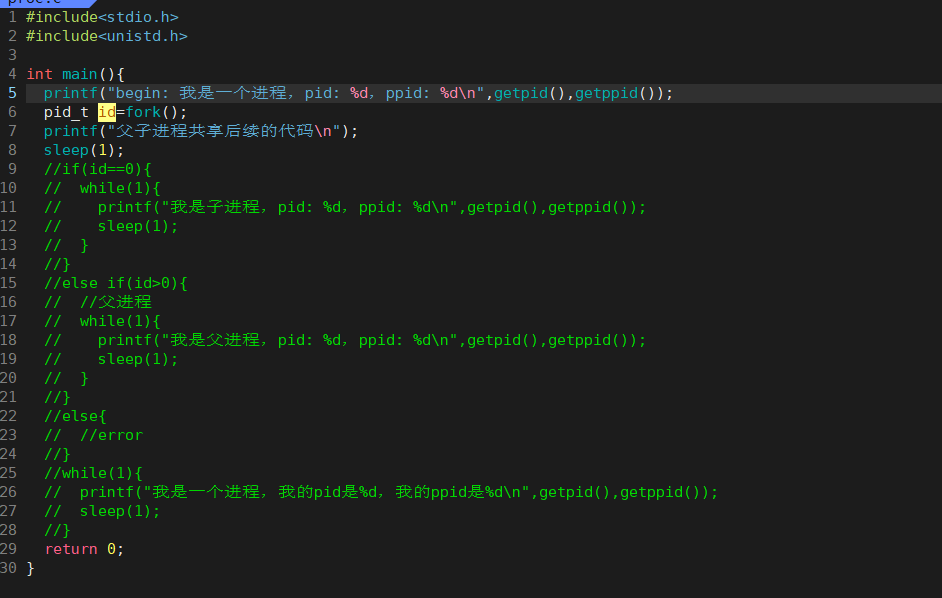
编译运行,我们的刚刚的结论得到验证,父子进程共享后续代码。

我们回到刚刚的话题,在fork函数return之前,子进程已经创建好了。return也是代码,父子进程共享,所以,会有两次返回。
第三个问题:我们定义的变量id,明明是一个变量,为什么会有不同的内容?这个问题现在还说不清,到后面再为大家解答。
第四个问题:fork函数究竟做了什么?创建子进程,在系统中就是多了一个进程,进程=内核数据结构+代码和数据,fork会为子进程相应的PCB,并将父进程PCB中的信息复制填充到里面,子进程没有自己的代码,只能和父进程共享一份代码,所以,fork之后,父子进程的代码共享。但它们的一些信息不能相同比如说PID,fork需要修改子进程的PID。在任何平台里,进程都是独立的,相互之间不影响。fork之后,父子进程的数据也是指向同一份的,如果子进程进行数据的修改,岂不是影响到了父进程。我父进程可没说要改数据哦!怎么办?系统说,子进程你别着急,我先帮你开辟一段空间帮你拷贝一下数据先。空间有了,数据拷贝好了。系统说,你现在可以修改数据了。我们把这种,在对共享数据进行更改时,才进行拷贝的方式,称之为写时拷贝。
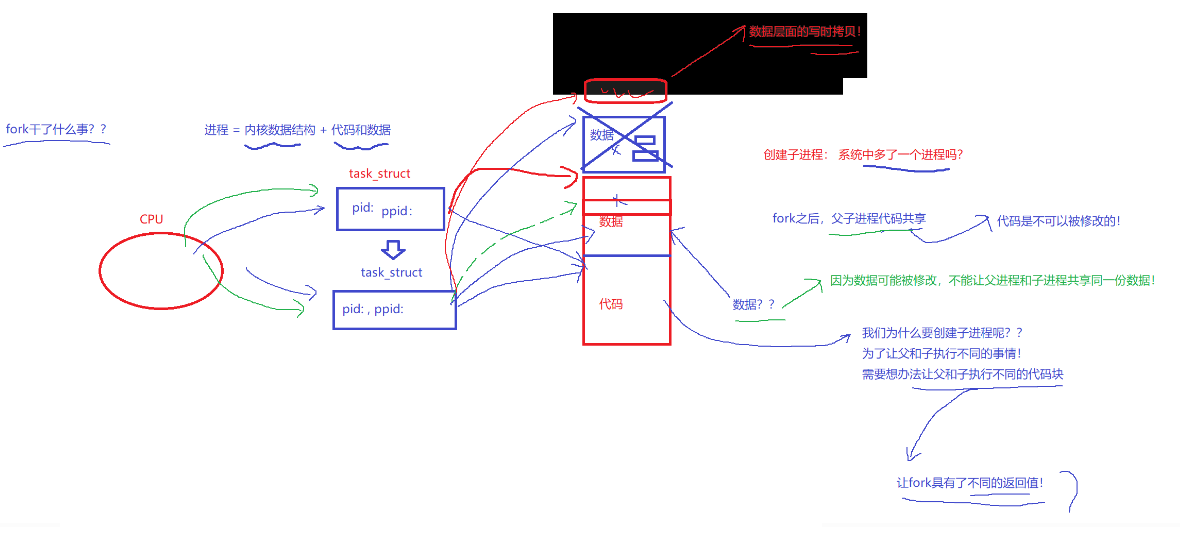
fork之后,父子进程谁先执行,由调度器来决定。
进程状态
进程的状态有新建状态,就绪态,运行态,阻塞态,终止态等等。对于不同的教材,有不同的看法,新建态就是刚创建的进程的状态。终止态,就是一个进程运行结束了。
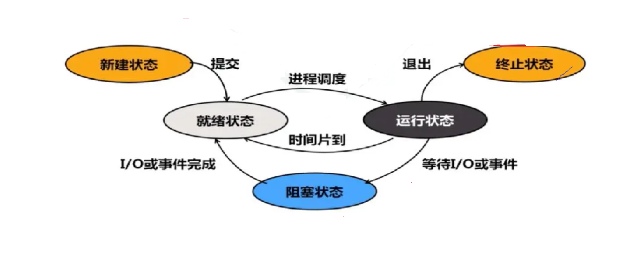
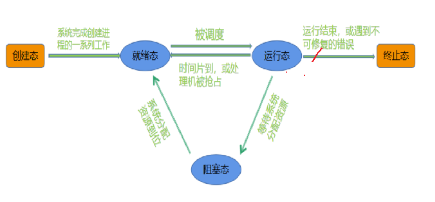
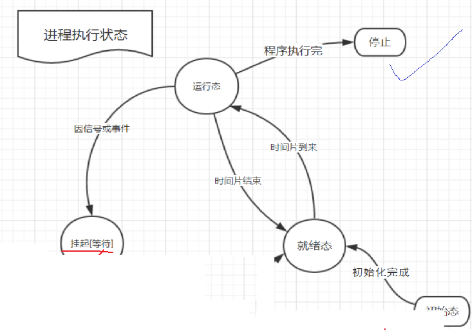
我们这里只讲运行,阻塞,挂起这三种,其他的状态,概念不是很明确。
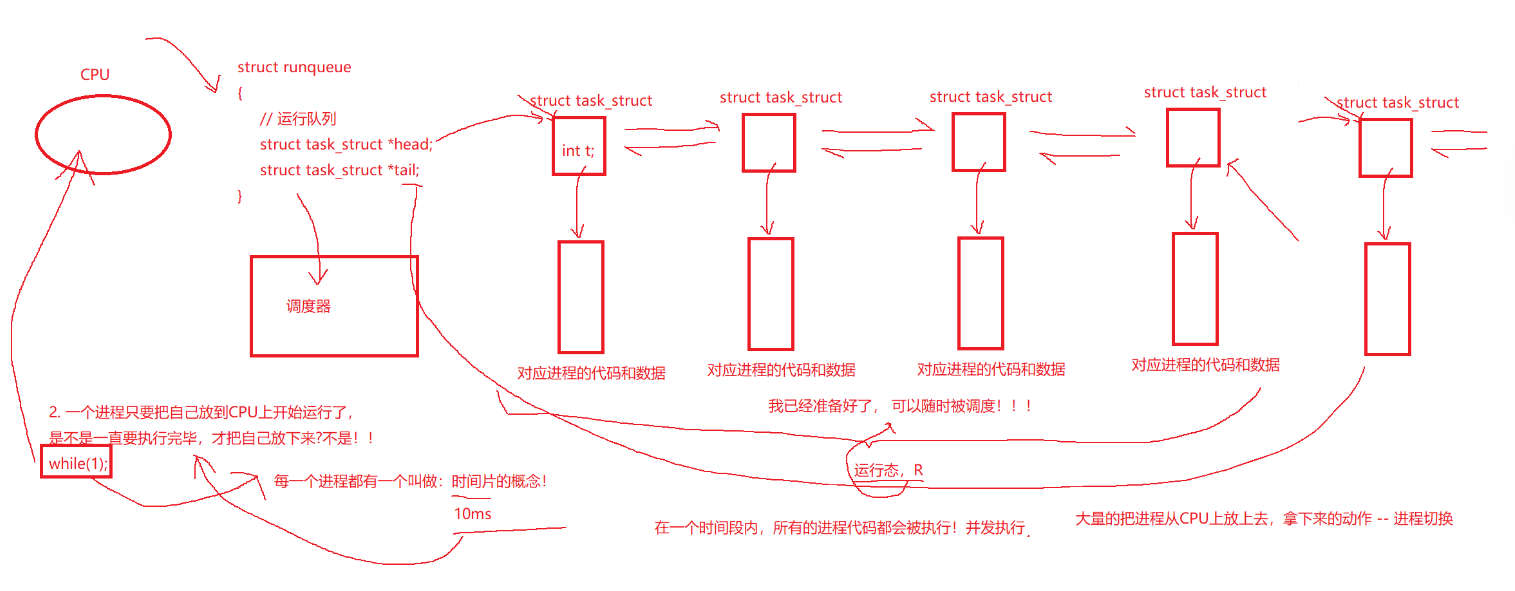
需要运行的进程有很多,CPU需要把它们管理起来,怎么管理?先组织,再描述。CPU只需要用一个将需要运行的进程的PCB用一个队列链接起来就可以将对进程的管理转换成对队列的管理。这个队列称之为运行队列,每次都选取队头的进程放入CPU中运行。那什么样的进程处于运行态呢?存在运行队列的进程,就处于运行态。根据我们的生活经验来看,一个进程并不是在CPU上一直执行,直到完成的。每个进程都会有一个时间片,时间片用完了,就会切换下一个进程到CPU中运行。这个时间片很短,短到我们察觉不到。我们认为的,电脑上几个程序同时在运行,而在计算机中,它们是交替运行的。我们把在一段时间内的运行的程序,称之为并发执行。
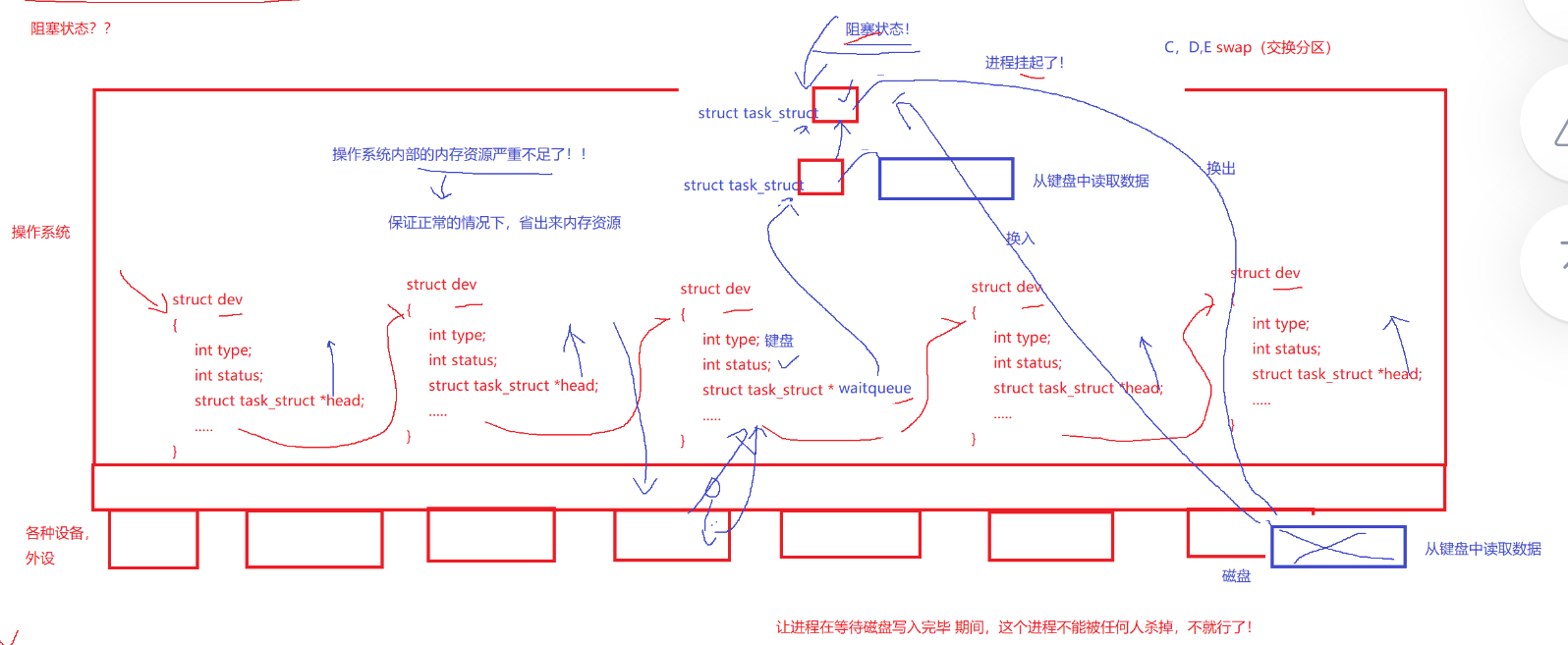
在OS之下,有很多的硬件,每个硬件都有自己对应的结构体。我们假设其中的一个结构用来描述键盘。此时,来了一个进程,需要从键盘上获取数据才能继续执行,可键盘迟迟不见有数据输入。这可怎么办?系统会把它从该进程的PCB链入到,描述键盘的结构体中的等待队列中,进行等待。而存在于等待队列的进程,我们称之为处于阻塞状态。那什么是挂起呢?键盘一直没有数据输入,等待的进程越来越多,把内存给占满了。可又有新的进程启动需要调度运行,这可怎么办?你不是在等待队列里等待资源就绪吗?你的代码和数据暂时还用不上,我帮你们把它换出去,只留下PCB在哪等就可以了,待你们获取到了数据,我再把你们的代码和数据换进来。于是,内存就腾出了大量的空间,新的进程又可以正常的被调度运行。我们把只有进程PCB存在内存里面的进程,称之为处于挂起状态。
好了,到这里,我们本次的分享就到此结束了,不知道我有没有说明白,给予你一点点收获。关于更多和Linux相关的知识,会在后面的文章更新。如果你有所收获,别忘了给我点个赞,这是对我最好的回馈,当然你也可以在评论发表一下你的收获和心得,亦或者指出我的不足之处。如果喜欢我的分享,别忘了给我点关注噢。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









