




简介:本项目分享了作者在Python中实现基本数据结构和算法的经验,包括数组、链表、栈、队列、堆、二叉树、图、排序和查找算法以及哈希表。这些概念的详细说明和具体实现方法有助于理解复杂问题并提升编程效率,为解决实际项目中的性能挑战打下基础。 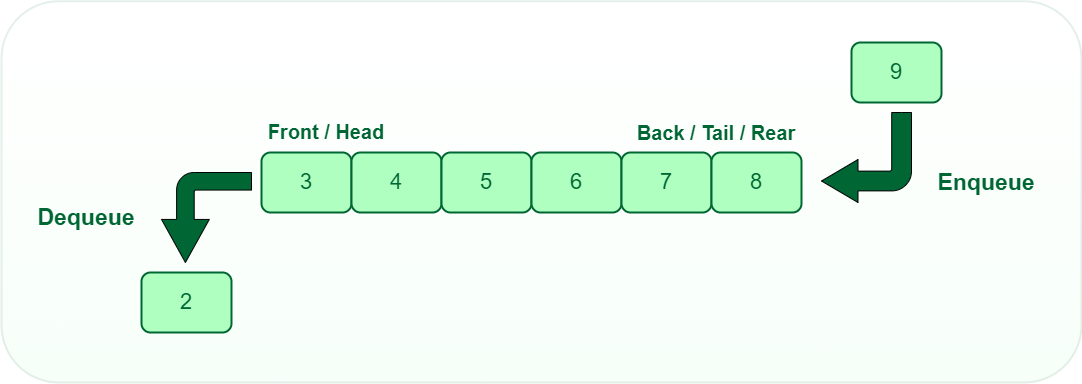
1. 数组(Array)和Python列表实现
1.1 数组的基本概念
数组(Array)是一种线性数据结构,它可以存储固定数量的元素,这些元素具有相同的数据类型,并且通过索引进行访问。在Python中,列表(List)是一种内置的数据结构,它类似于数组,但在功能上更为强大和灵活。
1.2 数组和列表的区别
尽管数组和列表在某些方面相似,但它们在实现和性能上有所不同。数组通常是静态的,一旦创建,其大小就不可改变,而Python列表则是动态的,可以在运行时进行元素的添加和删除。此外,数组通常是同质的,意味着它们只能包含相同类型的数据,而Python列表则不受这种限制。
1.3 Python列表的实现
在Python中,列表是使用动态数组实现的。这意味着列表会根据需要自动调整其大小,而不需要手动管理内存分配和扩容操作。下面是一个简单的Python列表实现示例:
class MyList:
def __init__(self):
self.data = []
def add(self, element):
self.data.append(element)
def remove(self, element):
self.data.remove(element)
def __getitem__(self, index):
return self.data[index]
def __setitem__(self, index, element):
self.data[index] = element
def __str__(self):
return str(self.data)
在这个简单的列表实现中,我们使用Python内置的列表来存储元素。 add 方法用于添加元素, remove 方法用于删除元素, __getitem__ 和 __setitem__ 方法分别用于获取和设置特定索引的元素, __str__ 方法用于将列表转换为字符串形式。
2. 链表(Linked List)的Python类模拟
链表是一种常见的数据结构,它由一系列节点组成,每个节点包含数据部分和指向下一个节点的指针。在Python中,我们可以通过类来模拟链表的行为。本章节我们将深入探讨链表的基本概念和结构,并通过Python类模拟实现链表的操作。
2.1 链表的基本概念和结构
链表的种类有很多,包括单向链表、双向链表和循环链表。每种链表都有其特定的应用场景和优缺点。
2.1.1 单向链表
单向链表是最简单的链表类型,每个节点包含数据和一个指向下一个节点的指针。
class ListNode:
def __init__(self, value=0, next=None):
self.value = value
self.next = next
class SinglyLinkedList:
def __init__(self):
self.head = None
def append(self, value):
new_node = ListNode(value)
if self.head is None:
self.head = new_node
else:
current = self.head
while current.next:
current = current.next
current.next = new_node
2.1.2 双向链表
双向链表的每个节点除了包含指向下一个节点的指针外,还包含一个指向前一个节点的指针。
class DoublyListNode:
def __init__(self, value=0, prev=None, next=None):
self.value = value
self.prev = prev
self.next = next
class DoublyLinkedList:
def __init__(self):
self.head = None
self.tail = None
def append(self, value):
new_node = DoublyListNode(value)
if not self.head:
self.head = new_node
self.tail = new_node
else:
self.tail.next = new_node
new_node.prev = self.tail
self.tail = new_node
2.1.3 循环链表
循环链表的最后一个节点的指针指向链表的头节点,形成一个环。
class CircularListNode:
def __init__(self, value=0):
self.value = value
self.next = None
class CircularLinkedList:
def __init__(self):
self.head = None
def append(self, value):
new_node = CircularListNode(value)
if not self.head:
self.head = new_node
new_node.next = self.head
else:
current = self.head
while current.next != self.head:
current = current.next
current.next = new_node
new_node.next = self.head
2.2 链表的操作实现
链表的操作主要包括节点的增删改查以及链表的遍历。
2.2.1 节点的增删改查
在链表中添加、删除、修改节点的操作都涉及对指针的重新指向。
2.2.2 链表的遍历
遍历链表是链表操作的基础,可以使用迭代或递归的方式进行。
2.3 Python类模拟链表
2.3.1 类的设计和初始化
在Python中,我们可以定义类来模拟链表的行为。
2.3.2 方法的实现和使用
我们将实现链表的常见操作,如添加、删除和遍历节点。
class Node:
def __init__(self, data):
self.data = data
self.next = None
class LinkedList:
def __init__(self):
self.head = None
def append(self, data):
if not self.head:
self.head = Node(data)
else:
current = self.head
while current.next:
current = current.next
current.next = Node(data)
def delete(self, key):
current = self.head
prev = None
if current and current.data == key:
self.head = current.next
current = None
return
while current and current.data != key:
prev = current
current = current.next
if current:
prev.next = current.next
current = None
def display(self):
elements = []
current = self.head
while current:
elements.append(current.data)
current = current.next
return elements
# 使用示例
llist = LinkedList()
llist.append(1)
llist.append(2)
llist.append(3)
print(llist.display()) # 输出: [1, 2, 3]
llist.delete(2)
print(llist.display()) # 输出: [1, 3]
通过本章节的介绍,我们了解了链表的基本概念和结构,并通过Python类模拟实现了链表的操作。链表作为一种基础的数据结构,其应用广泛,掌握其操作对于学习更高级的数据结构和算法有着重要的意义。在本章节中,我们详细探讨了单向链表、双向链表和循环链表的定义和特点,以及如何在Python中通过类来模拟这些数据结构。此外,我们还学习了如何实现链表的增删改查操作,并通过实际代码示例加深了理解。
3. 栈(Stack)的后进先出操作
3.1 栈的定义和特性
3.1.1 栈的基本概念
栈是一种特殊的列表,它只允许在表的一端进行插入和删除操作,这一端被称为栈顶(Top),另一端被称为栈底(Bottom)。栈的操作是后进先出(LIFO, Last In First Out)的,即最后加入的元素最先被移除。这种特性使得栈在很多场景下都非常有用,比如在浏览器的后退功能中,栈可以用来保存访问过的页面地址;在程序设计语言中,函数的调用也是通过栈来实现的。
3.1.2 栈的后进先出(LIFO)特性
栈的LIFO特性意味着元素的移除顺序与添加顺序相反。例如,如果我们在栈中依次添加元素A、B、C,那么在移除元素时,我们会先移除C,然后是B,最后是A。这种特性使得栈非常适合处理那些需要反转元素顺序的场景,如算法中的括号匹配问题,或者在进行深度优先搜索(DFS)时保存访问路径。
3.2 栈的Python实现
3.2.1 使用列表模拟栈
在Python中,我们可以使用内置的列表(list)数据结构来模拟栈的行为。列表提供了append()和pop()方法,这些方法正好对应于栈的push和pop操作。
class Stack:
def __init__(self):
self.items = []
def is_empty(self):
return len(self.items) == 0
def push(self, item):
self.items.append(item)
def pop(self):
if not self.is_empty():
return self.items.pop()
raise IndexError("pop from an empty stack")
def peek(self):
if not self.is_empty():
return self.items[-1]
raise IndexError("peek from an empty stack")
def size(self):
return len(self.items)
代码逻辑解读分析:
-
__init__方法初始化一个空列表self.items,用于存储栈内的元素。 -
is_empty方法检查栈是否为空,返回布尔值。 -
push方法在列表的末尾添加一个元素,模拟栈的入栈操作。 -
pop方法移除并返回列表的最后一个元素,模拟栈的出栈操作。如果栈为空,则抛出IndexError。 -
peek方法返回列表的最后一个元素而不移除它,模拟查看栈顶元素的操作。如果栈为空,则抛出IndexError。 -
size方法返回栈内元素的数量。
3.2.2 栈的基本操作:push, pop, peek
接下来,我们将演示如何使用上面定义的 Stack 类来执行基本操作。
# 创建一个栈实例
stack = Stack()
# 入栈操作
stack.push('A')
stack.push('B')
stack.push('C')
# 查看栈顶元素
print(stack.peek()) # 输出: C
# 出栈操作
print(stack.pop()) # 输出: C
print(stack.pop()) # 输出: B
print(stack.pop()) # 输出: A
# 检查栈是否为空
print(stack.is_empty()) # 输出: True
参数说明:
-
'A','B','C':入栈的元素。 -
stack:栈的实例。
执行逻辑说明:
- 首先,我们创建了一个
Stack类的实例stack。 - 使用
push方法将'A','B','C'依次入栈。 - 使用
peek方法查看栈顶元素,输出应该是'C'。 - 使用
pop方法依次出栈,输出依次是'C','B','A'。 - 最后,使用
is_empty方法检查栈是否为空,输出应该是True,表示栈已经为空。
通过本章节的介绍,我们可以了解到栈的概念、特性和Python中的实现方式。栈是一种非常基础且重要的数据结构,它的后进先出特性在很多算法和应用中都有着广泛的应用。在下一章节中,我们将继续探讨队列的先进先出操作,以及如何在Python中实现它。
4. 队列(Queue)的先进先出实现
队列是一种常见的数据结构,它遵循先进先出(First In First Out, FIFO)的原则。在现实生活中,队列的应用非常广泛,比如排队买票、任务调度等。在计算机科学中,队列常用于实现任务调度、缓冲处理等场景。
4.1 队列的定义和特性
队列作为一种线性数据结构,具有以下基本概念和特性:
4.1.1 队列的基本概念
队列是一种特殊的列表,只能在一端(称为“队尾”)插入新元素,在另一端(称为“队头”)删除元素。队列的操作主要有两种:入队(enqueue)和出队(dequeue)。入队指的是在队尾添加一个元素,而出队指的是移除队头的元素。
4.1.2 队列的先进先出(FIFO)特性
队列的核心特性是先进先出,这意味着最早被添加到队列中的元素将会是第一个被移除的。这个特性使得队列非常适合用于模拟一系列按照特定顺序发生的事件。
4.2 队列的Python实现
在Python中,队列可以通过内置的 list 类型来实现,也可以使用 collections 模块中的 deque 类来实现更高效的队列操作。
4.2.1 使用列表模拟队列
使用列表实现队列是一种简单直观的方法。以下是使用列表模拟队列的一个基本示例:
class Queue:
def __init__(self):
self.items = []
def enqueue(self, item):
self.items.insert(0, item)
def dequeue(self):
return self.items.pop()
def is_empty(self):
return len(self.items) == 0
def size(self):
return len(self.items)
在这个 Queue 类中,我们使用一个列表 items 来存储队列中的元素。 enqueue 方法通过 insert(0, item) 在列表的开始位置插入新元素, dequeue 方法通过 pop() 移除列表的最后一个元素。 is_empty 方法检查队列是否为空, size 方法返回队列的大小。
4.2.2 队列的基本操作:enqueue, dequeue
下面是一个简单的测试代码,演示了如何使用上述 Queue 类进行入队和出队操作:
# 创建一个队列实例
q = Queue()
# 入队操作
q.enqueue('Alice')
q.enqueue('Bob')
q.enqueue('Charlie')
# 出队操作
print(q.dequeue()) # 输出: Alice
print(q.dequeue()) # 输出: Bob
# 检查队列是否为空
print(q.is_empty()) # 输出: False
# 获取队列的大小
print(q.size()) # 输出: 1
在本章节中,我们介绍了队列的基本概念和特性,以及如何在Python中使用列表和 collections.deque 来实现队列。队列是一种非常基础且重要的数据结构,它在许多算法和实际应用中都有着广泛的应用。在下一章节中,我们将继续探讨堆和优先队列的操作。
5. 堆(Heap)和优先队列操作
堆是一种特殊的树形数据结构,具体来说,它是一种完全二叉树。在堆中,每个节点的值都必须大于或等于(最大堆)或小于或等于(最小堆)其子节点的值。这种性质使得堆成为实现优先队列的极佳数据结构,其中元素的优先级由堆的性质决定。
5.1 堆的基本概念
5.1.1 堆的定义和性质
堆通常被定义为一个特殊的完全二叉树,其中每个父节点的值都大于或等于(在最大堆中)或小于或等于(在最小堆中)其子节点的值。堆的性质决定了其操作的特性和效率。堆通常用于实现优先队列,其中元素的优先级由其在堆中的位置决定。
堆的一个关键性质是它的完全二叉树结构,这意味着除了最后一层外,所有层都被完全填满,最后一层的节点集中在左侧。这个结构使得堆非常适合使用数组来实现,数组的索引可以用来计算父节点和子节点之间的关系。
堆的另一个重要性质是其高度平衡的特性,这保证了堆操作的对数时间复杂度。在最大堆中,最大元素始终位于根节点,这使得它非常适合实现具有最高优先级的元素总是最先被处理的场景。
5.1.2 堆的操作:堆化(heapify)
堆化是堆结构的核心操作之一,它用于重新排列数组,使其满足堆的性质。堆化通常用于构建堆或在修改堆后恢复其性质。在最大堆中,堆化过程会从最后一个非叶子节点开始,向上进行,确保每个节点都满足最大堆的性质。最小堆的堆化过程与之类似,但是它是确保每个节点都满足最小堆的性质。
堆化的时间复杂度为 O(n),其中 n 是堆中元素的数量。这是因为堆的高度为 log(n),而堆化的每一步都只需要 O(log(n)) 的时间。因此,对于整个堆来说,时间复杂度是线性的。
堆化的代码实现如下:
def heapify(arr, n, i):
largest = i
left = 2 * i + 1
right = 2 * i + 2
# 如果左子节点存在且大于当前节点
if left < n and arr[i] < arr[left]:
largest = left
# 如果右子节点存在且大于当前最大节点
if right < n and arr[largest] < arr[right]:
largest = right
# 如果最大节点不是当前节点,交换并继续堆化
if largest != i:
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
def build_heap(arr):
n = len(arr)
# 从最后一个非叶子节点开始向上堆化
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i)
# 示例数组
arr = [3, 5, 9, 6, 8, 20, 10, 12, 18, 9]
build_heap(arr)
print("Heapified array is:", arr)
5.2 优先队列的实现
5.2.1 优先队列的基本概念
优先队列是一种抽象数据类型,它允许插入新的对象,并且每次删除(或访问)时返回优先级最高的对象。在堆中实现的优先队列通常具有对数级的时间复杂度,这是因为堆的高度为 log(n)。优先队列在许多算法中都有应用,例如在图的算法中,用于找到最短路径的 Dijkstra 算法就使用了优先队列。
5.2.2 使用堆实现优先队列
在 Python 中,我们可以使用列表来模拟堆,并且使用堆操作来实现优先队列。我们可以定义一个类 PriorityQueue ,它包含插入( enqueue )和删除( dequeue )方法。插入方法将新元素添加到列表的末尾,然后通过堆化过程将其移动到正确的位置。删除方法返回并移除堆的根节点(最大或最小元素),然后将堆的最后一个元素移动到根节点的位置,并进行堆化。
以下是使用最小堆实现优先队列的示例代码:
import heapq
class PriorityQueue:
def __init__(self):
self.heap = []
def enqueue(self, item):
heapq.heappush(self.heap, item)
def dequeue(self):
return heapq.heappop(self.heap)
def __repr__(self):
return f"PriorityQueue({self.heap})"
pq = PriorityQueue()
pq.enqueue(5)
pq.enqueue(3)
pq.enqueue(10)
pq.enqueue(1)
print(pq) # PriorityQueue([1, 3, 10, 5])
print(pq.dequeue()) # 1
print(pq) # PriorityQueue([3, 5, 10])
在这个示例中,我们使用了 Python 的 heapq 模块来实现堆操作。 PriorityQueue 类的 enqueue 方法使用 heapq.heappush 来添加元素,而 dequeue 方法使用 heapq.heappop 来移除并返回堆的根节点。这样,我们就得到了一个简单的优先队列实现。
6. 二叉树(Binary Tree)结构和二叉搜索树(BST)
6.1 二叉树的基本概念
6.1.1 二叉树的定义和类型
二叉树是每个节点最多有两个子树的树结构,通常子树被称作“左子树”和“右子树”。二叉树的递归定义如下:
- 空树是二叉树。
- 如果一个节点有左子树和右子树,则这两个子树也必须分别是二叉树。
二叉树的类型主要有以下几种:
- 完全二叉树:除了最后一层外,每一层都被完全填满,且所有节点都尽可能地向左。
- 满二叉树:每一层的所有节点都有两个子节点,除了叶子节点。
- 平衡二叉树(AVL树):任何节点的两个子树的高度差不超过1。
- 二叉搜索树(BST):对于树中的每个节点,其左子树中的所有元素都小于该节点,右子树中的所有元素都大于该节点。
6.1.2 二叉树的遍历算法:前序、中序、后序
二叉树的遍历通常有三种主要方式:
- 前序遍历(Pre-order Traversal):首先访问根节点,然后遍历左子树,最后遍历右子树。
- 中序遍历(In-order Traversal):首先遍历左子树,然后访问根节点,最后遍历右子树。对于二叉搜索树,中序遍历可以得到有序的节点值。
- 后序遍历(Post-order Traversal):首先遍历左子树,然后遍历右子树,最后访问根节点。
以下是使用递归方式实现三种遍历的Python代码示例:
class TreeNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def preorder_traversal(root):
if root:
print(root.value, end=' ')
preorder_traversal(root.left)
preorder_traversal(root.right)
def inorder_traversal(root):
if root:
inorder_traversal(root.left)
print(root.value, end=' ')
inorder_traversal(root.right)
def postorder_traversal(root):
if root:
postorder_traversal(root.left)
postorder_traversal(root.right)
print(root.value, end=' ')
6.2 二叉搜索树(BST)的实现
6.2.1 二叉搜索树的性质
二叉搜索树(BST)是一种特殊的二叉树,它满足以下性质:
- 对于树中的每个节点X,其左子树中所有元素的值都小于X的值。
- 对于树中的每个节点X,其右子树中所有元素的值都大于X的值。
- 左右子树也分别为二叉搜索树。
6.2.2 BST的插入、删除和查找操作
BST的插入、删除和查找操作都是基于上述性质进行的。以下是BST的基本操作的Python代码示例:
class TreeNode:
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def insert(root, value):
if root is None:
return TreeNode(value)
else:
if value < root.value:
root.left = insert(root.left, value)
else:
root.right = insert(root.right, value)
return root
def find(root, value):
if root is None or root.value == value:
return root
if value < root.value:
return find(root.left, value)
return find(root.right, value)
def delete(root, value):
if root is None:
return root
if value < root.value:
root.left = delete(root.left, value)
elif value > root.value:
root.right = delete(root.right, value)
else:
if root.left is None:
temp = root.right
root = None
return temp
elif root.right is None:
temp = root.left
root = None
return temp
temp = minValueNode(root.right)
root.value = temp.value
root.right = delete(root.right, temp.value)
return root
def minValueNode(node):
current = node
while current.left is not None:
current = current.left
return current
请注意,删除操作的逻辑需要特别注意,当要删除的节点有两个子节点时,通常用其右子树中的最小节点来替换它。这是因为在二叉搜索树中,右子树的最小值一定大于左子树的所有值,并且大于当前节点的值,满足BST的性质。
简介:本项目分享了作者在Python中实现基本数据结构和算法的经验,包括数组、链表、栈、队列、堆、二叉树、图、排序和查找算法以及哈希表。这些概念的详细说明和具体实现方法有助于理解复杂问题并提升编程效率,为解决实际项目中的性能挑战打下基础。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









