






日常工作中表格处理时非常令人头疼的一个部分,今天我们来分享一下如何用Python快速的处理表格读写,处理数据,提高我们的效率。
比如我们边读表格边按复杂规则筛选我们的数据、统计我们的数据;或者我们边解析文本边把结果写到表格,形式报告。
上一节我们最后写了一个解析文本(设备上show出来的配置)成字典的列表的脚本,可以和这个相呼应。
我们已经拿到了结构化数据,我们把它写到一个Excel表格里,今天继续用Python实现。
今天的内容主要是分享
1、基于Python内置的CSV的几种读写(可以不看)
2、基于xlrd的读方式(初学者完全可以不看)
3、基于Pandas的表格读写计算(必看,最简方式,没时间直接看这个吧!)
大家各取所需去读对应的即可。
基于Python内置的CSV表格处理
CSV
我们先从简单的CSV处理,不需要装任务第三方包即可解析处理,如果各位是Excel,也可以另存为csv格式的。
概念
CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本 格式,用以存储表格数据,包括数字或者字符。很多程序在处理数据时都会碰到csv这种格式的文件,它的使用是比 较广泛的(Kaggle上一些题目提供的数据就是csv格式),csv虽然使用广泛,但却没有通用的标准,所以在处理csv 格式时常常会碰到麻烦,幸好python内置了csv模块。下面简单介绍csv模块中最常用的一些函数。
读表格
我们用到了一个特殊的数据结构 nametuple可以兼顾字典和对象的一些优点。
import csvfrom collections import namedtuplewith open('accessinfo_base.csv',encoding='utf8') as f: f_csv = csv.reader(f) headers = next(f_csv) print('表头',headers) for row in f_csv: print(row)## named tuplewith open('accessinfo_base.csv',encoding='utf8') as f: f_csv = csv.reader(f) headers = next(f_csv) Row = namedtuple('Row',headers) for r in f_csv: row = Row(*r) print(row,row.role,row.area)## 读取到字典去中with open('accessinfo_base.csv',encoding='utf8') as f: f_csv = csv.DictReader(f) for r in f_csv: print(r)写表格
## 读取到字典去中with open('accessinfo_base.csv',encoding='utf8') as f: f_csv = csv.DictReader(f) for r in f_csv: print(r)## 写入csv,先创建一个csv的writer对象with open('test1.csv', 'w', encoding='utf8') as f: headers = ['ip', 'area', 'role'] rows = [['127.0.0.1', 'A', 'AS'], ['127.0.0.1', 'A', 'AS'], ['127.0.0.1', 'A', 'AS'], ['127.0.0.1', 'A', 'AS']] csv_writer = csv.writer(f) csv_writer.writerow(headers) csv_writer.writerows(rows)# newline很重要,不然会出现间隔的空白行,w代表写文件。with open('test2.csv', 'w', encoding='utf8',newline='') as f: headers = ['ip', 'area', 'role'] rows = [['127.0.0.1', 'A', 'AS'], ['127.0.0.1', 'A', 'AS'], ['127.0.0.1', 'A', 'AS'], ['127.0.0.1', 'A', 'AS']] csv_writer = csv.writer(f,delimiter='\t') csv_writer.writerow(headers) csv_writer.writerows(rows)## 字典的方式写入with open('test3.csv', 'w', encoding='utf8',newline='') as f: headers = ['ip', 'area', 'role'] rows = [{ 'ip': '12', 'area': 'a', 'role': 'as' }, { 'ip': '12', 'area': 'a', 'role': 'as' }, { 'ip': '12', 'area': 'a', 'role': 'as' }, ] csv_writer = csv.DictWriter(f,headers) csv_writer.writeheader() csv_writer.writerows(rows)基于xlrd的读方式
xlrd
如果是anaconda,无需安装,后者cmd执行 pip install xlrd
读Excel文件
支持xls、xlsx
import xlrddef print_excel(filePath): myWbook = xlrd.open_workbook(filePath) mySheet = myWbook.sheet_by_index(0) # 也可以使用函数mySheet = myWbook.sheet_by_name('sheet1') nrows = mySheet.nrows # 行数 ncols = mySheet.ncols # 列数 i = 1 err_num=0 while i < nrows: try: print(mySheet.row_values(i)) a = mySheet.row(i)[0].value b = mySheet.row(i)[1].value c = mySheet.row(i)[2].value print(a,b,c) i = i + 1 except Exception as e: print(e) err_num = err_num + 1 i = i + 1 return err_num # success def print_excel_2(filePath): myWbook = xlrd.open_workbook(filePath) mySheet = myWbook.sheet_by_index(0) # 也可以使用函数mySheet = myWbook.sheet_by_name('sheet1') cell_type = mySheet.cell(1,2).ctype ## 1为字符串、2为数字 3为日期 print(cell_type) #取某个位置的值 print(mySheet.cell(1,1).value) print(mySheet._cell_values) ##读取整个cell if __name__ == '__main__': print_excel_2('accessinfo_base.xls')基于Pandas的表格读写计算
pandas
如果是anaconda,无需安装,未安装,cmd执行 pip install pandas安装Python的这个优秀的第三方包。
pandas是一款数据处理的工具,基于Numpy去编写的。提供了大量快捷处理数据的函数和方法。
本次我使用它在读写表格的一些便捷的方法,其实有点大材小用。
读表格
实用主义者可以直接去看“以转换dict的list的方式读取”
首先可以先创建一个excel文件当作实验数据,名称为example.xlsx,内容如下:
| name | age | gender |
|---|---|---|
| John | 30 | male |
| Mary | 22 | female |
| Smith | 32 | male |
读取并打印
注意 sheet名要对应起来。
# coding:utf-8import pandas as pddata = pd.read_excel('example.xlsx', sheet_name='Sheet1')print(data)
这里使用了read_excel()方法来读取excel,来看一个read_excel()这个方法的API,这里只截选一部分经常使用的参数:
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None)
这里主要参数为io,sheet_name,header,usecols和names
io:excel文件路径
sheet_name:返回指定的sheet,如果将sheet_name指定为None,则返回第一页,如果需要返回多个表,可以将sheet_name指定为一个列表,例如['sheet1', 'sheet2']
header:指定数据表的表头,默认值为0,即将第一行作为表头。如果表中无表头,此值应为None,对应的表头会用索引表示,也可搭配names,指定表头。
usecols:读取指定的列,例如想要读取第一列和第二列数据:
pd.read_excel("example.xlsx", sheet_name=None, usecols=[0, 1])
index_col 指定某列为索引
遍历所有行
# coding:utf-8import pandas as pddata = pd.read_excel('example.xlsx', )print(data)for index, row in data.iterrows(): print(row['name'], row['age'], row['gender']) print(row[0], row[1], row[2])
以转换dict的list的方式读取
# coding:utf-8import pandas as pddata = pd.read_excel('example.xlsx', )data = data.to_dict(orient='records')print(data)
写表格
DataFrame(data).to_excel('example.xlsx', sheet_name='Sheet1', index=False, header=True)
# coding:utf-8import pandas as pdraw_data = [{'name': 'John', 'age': 30, 'gender': 'male'}, {'name': 'Mary', 'age': 22, 'gender': 'female'}, {'name': 'Smith', 'age': 32, 'gender': 'male'}]data = pd.DataFrame(raw_data)print(data)data.to_excel('example_output.xlsx', sheet_name='Test01', index=False, header=True)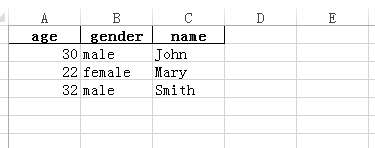
数据的计算
我们只写数据计算部分,不去写读取和写入的部分。
有时候我们需要处理表格中的内容,比如根据表格中的多项字段生成一个新的字段,得到一个新的结论。
比如有时候考试题出的太难了,大家都不及格,我们想让大家都及格,可以这样写。我们没有采用乘以10开根号的办法,我们简单点。
import pandas as pdraw_data = [{'name': 'John', 'score': 30, 'gender': 'male'}, {'name': 'Mary', 'score': 22, 'gender': 'female'}, {'name': 'Smith', 'score': 32, 'gender': 'male'}]data = pd.DataFrame(raw_data)print(data)def jige(row): print(row) if row['score'] < 60: return 60 return row['score']data['new_score'] = data.apply(jige, axis=1)print(data)这个代码的读取和写入我们省略了,大家可以自己补充上。
通过在数据里调用我们的函数,我们成功让大家都及格了。
我们想像下运维中的场景,比如根据端口类型、描述得出某些结论即一个新的字段。
计算此端口上是否有crc err数,甚至可以根据以往记录去计算crc的增长。
判断某些指标是否超过阈值,得出一个个的结论,即很多字段,加之组合生成一个巡检报告。
真的是抛砖。
还是希望分享一些方法,大家学会点基础的后,自己开脑洞!
好了关于Python的入门、读写文件、表格操作我们就讲完了!欢迎大家关注公众号,后续的分享会紧贴网络运维。
后续我们会聚焦网络运维,讲解一些能够提高我们运维效率的工具、技术、代码等等,讲解一些在云计算时代所需要了解的开源组件。
大家有什么想了解的也可以私信我,我会分享我所了解的部分~














 6362
6362











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









