





作者: 数据源的TiDB学习之路
问题现象
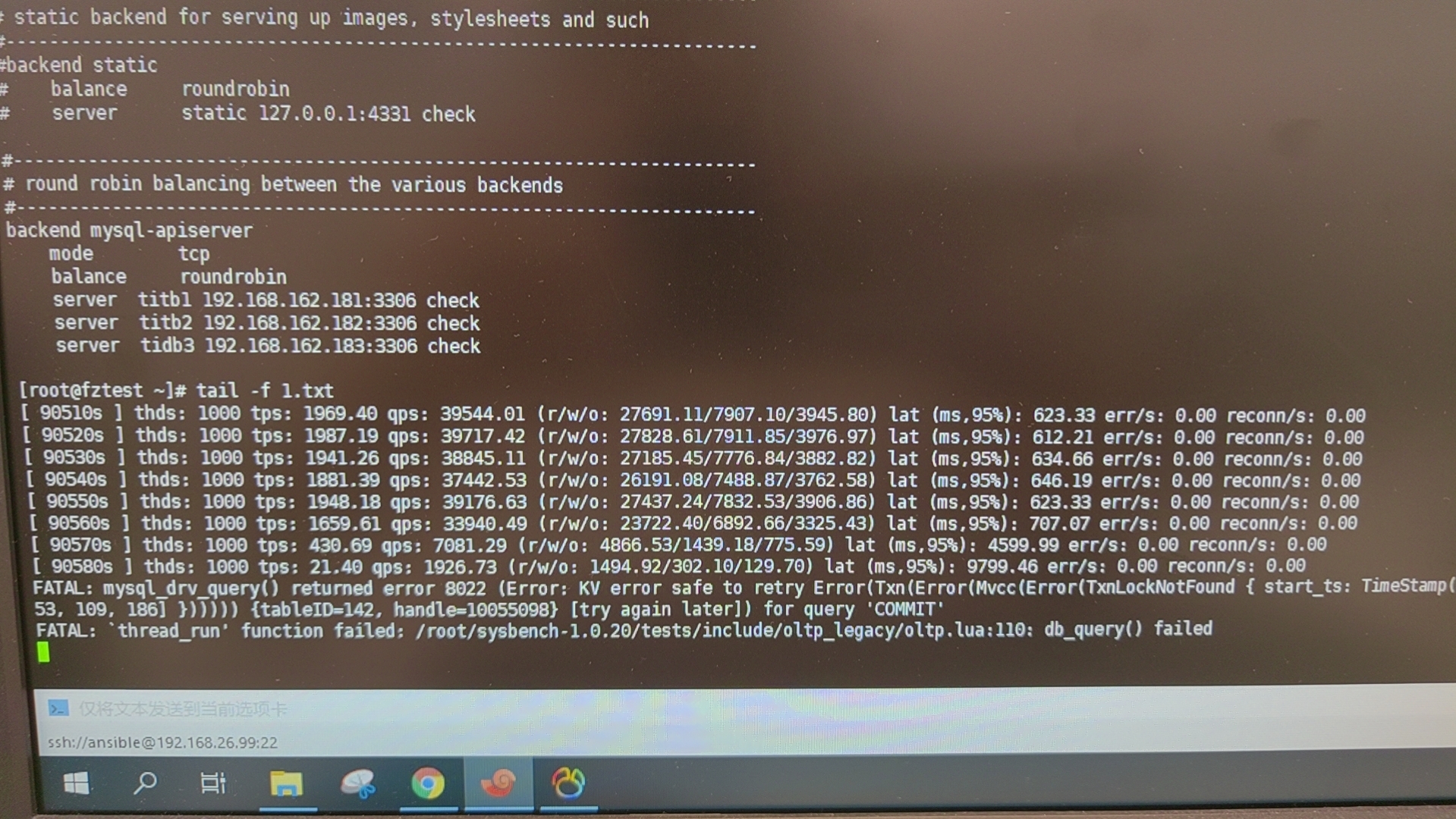
使用 sysbench + haproxy 对 TiDB 进行压测,运行 25 小时后遇到报错。
问题分析步骤
- 根据 sysbench 报错提示 error 8022,判断是事务提交失败出错。
以下日志 185 TiKV 节点对应报错日志,时间点与此事务报错完全一致。
根据官网说明,报错说明事务在 commit 提交时锁已经被清除导致。
https://docs.pingcap.com/zh/tidb/stable/troubleshoot-lock-conflicts#%E9%94%81%E8%A2%AB%E6%B8%85%E9%99%A4-locknotfound-%E9%94%99%E8%AF%AF


- 根据错误信息解析报错日志的开始时间和提交时间,事务的时间范围在 (14:52:19 - 14:52:42)
- 收集 Clinic。根据以下步骤收集 Clinic 并上传进一步分析。
- 分析 Grafana 图表及日志。查看问题时间点的异常情况,发现主要问题点包括:
- 在报错时间点发生 184 TiKV 的 Leader 切换。时间点约 14:53 分。
- Raft 层进行了 Leader 的切换(184节点)和选举(185 186 节点)。
- 通过日志聚合可以看到 184 节点共有 528 次 leader 被降级的情况(received a message with higher term,收到新任期的 leader 信息)(14:52:50-14:53:01),对应上述监控中约 530 左右个 leader 。
- 取其中某一个 region id 8801 对应日志。
- 先有大量的 scheduler handle 日志(写入请求超过 1 s 的慢日志)后,Raft Leader 进行切换。
- 181 节点 PD 持久化 WAL 花费时间耗时约 8 秒。
- 184 日志信息 大量请求 PD LEADER 失败(14:52:30-14:52:40)
<!---->
- 根据上述现象判断可能是因为网络原因或硬盘延迟导致 Raft 或 WAL 同步延迟。查看 Performance Overview 后发现在故障时间点磁盘延迟极高。
- 181 节点
- 184 节点
<!---->
- 根据上述分析,能够确认由于故障时间点 184 节点磁盘延迟突增,导致此节点上的 Raft 日志无法持久化到磁盘且无法正常向其余 Follower 同步。
- 在 184 节点 TiKV 磁盘不正常导致 scheduler 超长的时间(14:52:20-14:53:00)
- 所有的写入请求只要处理时间超过 1 s 都会记录 scheduler prewrite 日志,14:52:20-14:53:00,共出现 8098 次日志。
<!---->
- 184 节点 Leader 切换的原因是由于 TiDB 在 v5.2 版本后增加了慢节点的自动检测机制。由于磁盘延迟导致此节点严重变慢,184 被标记为慢节点( score 达到 80),从而引发 Leader 全部切换。
https://docs.pingcap.com/zh/tidb/stable/tikv-configuration-file#inspect-interval

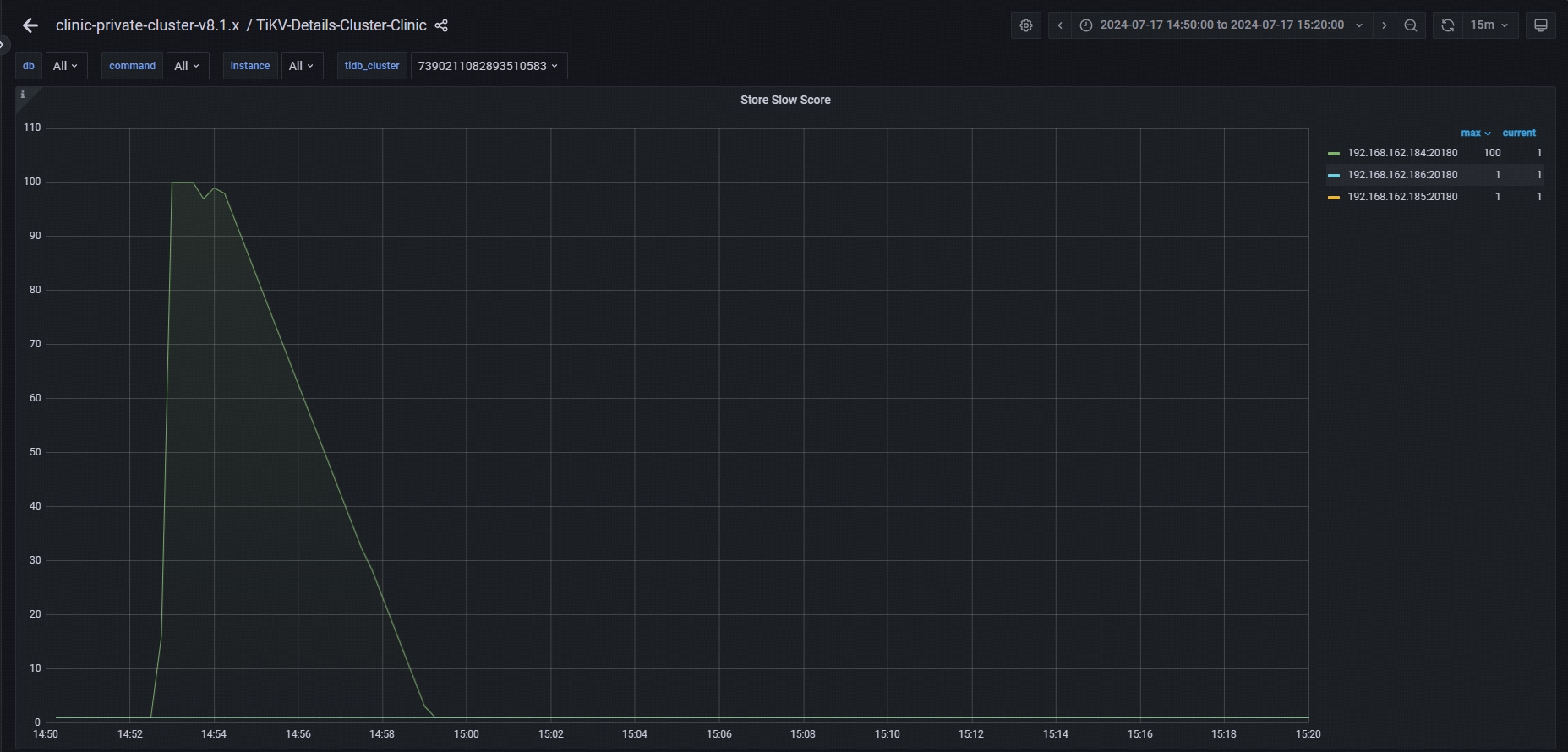
从 182 PD 日志也证明产生了 evict-slow-store-scheduler 调度任务
- 在 184 节点 TiKV 磁盘不正常导致 scheduler 超长的时间(14:52:20-14:53:01)和报错对应事务提交时间 14:52:42.792 重叠 (启动时间 14:52:19.94 ~ 提交时间 14:52:42.792),属于“建议检查下是否是因为写入性能的缓慢导致事务提交的效率差,进而出现了锁被清除的情况。”
分析结论
分布式事务中持有的锁在事务提交前,是需要不断得进行 TTL 续期的,TTL 的设计是为了防止由于事务异常中断,存储引擎上锁信息长期不释放的情况,导致其他事务无法获得该记录的锁的情况,第一次持有时间是 20 s。因为磁盘延迟突增引发写入性能严重下降的原因,导致锁的 TTL 续期不正常,其他会话获得锁时发现该记录上的锁已经过期,进行清除处理,最终原事务提交时发现锁被其他会话清理,已经不存在,不符合提交条件,事务提交失败。
有关 TiDB 锁行为分析,可参考 https://tidb.net/blog/bbcb5a11















 122
122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









