






TIKA提取HTML文档
下面给出的是该程序用于从HTML文档提取内容和元数据。
importjava.io.File;importjava.io.FileInputStream;importjava.io.IOException;importorg.apache.tika.exception.TikaException;importorg.apache.tika.metadata.Metadata;importorg.apache.tika.parser.ParseContext;importorg.apache.tika.parser.html.HtmlParser;importorg.apache.tika.sax.BodyContentHandler;importorg.xml.sax.SAXException;publicclassHtmlParse{publicstaticvoidmain(finalString[]args)throwsIOException,SAXException,TikaException{//detecting the file typeBodyContentHandlerhandler=newBodyContentHandler();Metadatametadata=newMetadata();FileInputStreaminputstream=newFileInputStream(newFile("example.htmll"));ParseContextpcontext=newParseContext();//Html parserHtmlParserhtmlparser=newHtmlParser();htmlparser.parse(inputstream,handler,metadata,pcontext);System.out.println("Contents of the document:"+handler.toString());System.out.println("Metadata of the document:");String[]metadataNames=metadata.names();for(Stringname:metadataNames){System.out.println(name+": "+metadata.get(name));}}}
保存上述代码保存为HtmlParse.java,并通过使用下面的命令从命令提示编译:
javacHtmlParse.java
javaHtmlParse
下面给出的是 example.htmll 文档的快照。
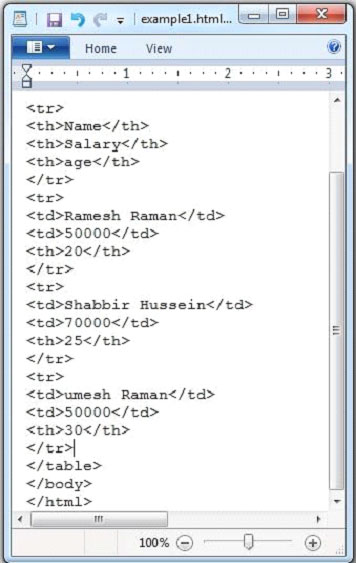
HTML文档有以下属性:
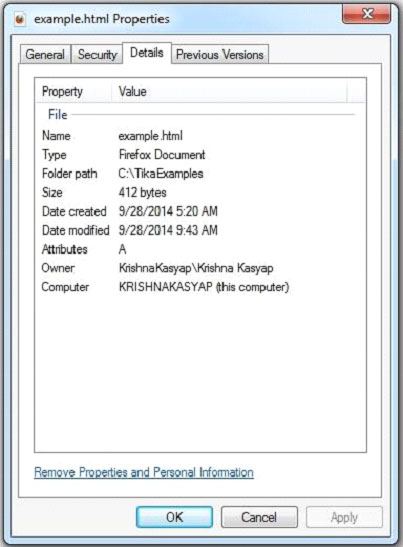
执行上述程序后,将得到下面的输出。
输出:
Contents of the document:
Name Salary age
Ramesh Raman 50000 20
Shabbir Hussein 70000 25
Umesh Raman 50000 30
Somesh 50000 35
Metadata of the document:
title: HTML Table Header
Content-Encoding: windows-1252
Content-Type: text/html; charset=windows-1252
dc:title: HTML Table Header















 2472
2472











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









