






一、把七零八碎的数据拼凑在一起(Python实现多表联合)
1.问题:现在有两张学生表的信息,如何合成一张表呢?
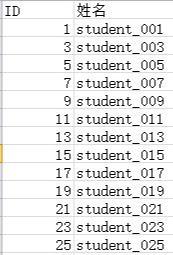
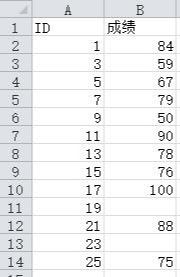
这个在Python里面只需要使用merge函数便可以实现。
import pandas as pdimport matplotlib.pyplot as plt#读Excel工作簿中两张表的数据,数据如上图students = pd.read_excel('students.xlsx',sheet_name='student')scores = pd.read_excel('students.xlsx',sheet_name='score')#将表联合table = students.merge(scores,on='ID')print(table)******************************************************** ID 姓名 成绩0 1 student_001 84.01 3 student_003 59.02 5 student_005 67.03 7 student_007 79.04 9 student_009 50.05 11 student_011 90.06 13 student_013 78.07 15 student_015 76.08 17 student_017 100.09 19 student_019 NaN10 21 student_021 88.011 23 student_023 NaN12 25 student_025 75.0 *******************************************************#merge也可以这么使用,效果是一样的table =pd.merge(students,scores,how='left',on='ID')2.merge 函数
merge( self, right, how="inner", on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=("_x", "_y"), copy=True, indicator=False, validate=None,)
参数说明
left 参与合并的左侧DataFrame
right参与合并的右侧DataFrame
how连接方式:‘inner’(默认);还有,‘outer’、‘left’、‘right’
on用于连接的列名,必须同时存在于左右两个DataFrame对象中,如果位指定,则以left和right列名的交集作为连接键
left_on左侧DataFarme中用作连接键的列
right_on右侧DataFarme中用作连接键的列
left_index将左侧的行索引用作其连接键
right_index将右侧的行索引用作其连接键
sort根据连接键对合并后的数据进行排序,默认为True。有时在处理大数据集时,禁用该选项可获得更好的性能
suffixes字符串值元组,用于追加到重叠列名的末尾,默认为(‘_x’,‘_y’).例如,左右两个DataFrame对象都有‘data’,则结果中就会出现‘data_x’,‘data_y’
copy设置为False,可以在某些特殊情况下避免将数据复制到结果数据结构中。默认总是赋值
大家可以参照上面说明进行优化。
我们联合完之后发现数据里有NaN,即缺失数据,我们一般怎么处理呢?可以使用fillna函数处理
table = students.merge(scores,how='left',on='ID').fillna(0)上面处理的结果就是将缺失值用0填充。fillna里面还有许多其他的方法,大家可以去尝试
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
参数:value : 变量, 字典, Series, or DataFrame
用于填充缺失值(例如0),或者指定为每个索引(对于Series)或列(对于DataFrame)使用哪个字典/Serise/DataFrame的值。(不在字典/Series/DataFrame中的值不会被填充)这个值不能是一个列表。
method : {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, 默认值 None ; 在Series中使用方法填充空白(‘backfill’, ‘bfill’向前填充,‘pad’, ‘ffill’向后填充)
axis : {0 or ‘index’, 1 or ‘columns’}
inplace : boolean, 默认值 False。如果为Ture,在原地填满。注意:这将修改次对象上的任何其他视图(例如,DataFrame中的列的无复制贴片)
limit : int, 默认值 None; 如果指定了方法,则这是连续的NaN值的前向/后向填充的最大数量。 换句话说,如果连续NaN数量超过这个数字,它将只被部分填充。 如果未指定方法,则这是沿着整个轴的最大数量,其中NaN将被填充。 如果不是无,则必须大于0。
downcast : dict, 默认是 None; 如果可能的话,把 item->dtype 的字典将尝试向下转换为适当的相等类型的字符串(例如,如果可能的话,从float64到int64)
join(),contact()函数也可以实现,与merge功能和用法类似,不单独介绍。
二、数据校验
数据校验是我们拿到数据后首先要做的工作,根据数据特性,写出相应规则的校验函数,下面演示最简单的一种。
#校验数据,查找是否存在异常成绩def score_validation(row): if not 0<=row['成绩']<=100: print(f"#%s student %s has an invalid score %s"%(row.ID,row['姓名'],row['成绩'])) #在主函数里面调用.axis=1轴为1表示数据由左向右(行校验),为0表示由上到下(列校验) students.apply(score_validation,axis=1)********************************************************************************************* #1 student student_001 has an invalid score 184#7 student student_007 has an invalid score -79#15 student student_015 has an invalid score 176#19 student student_019 has an invalid score -15#23 student student_023 has an invalid score 111 发现错误数据5条,后期就可以对其进行更正或者其他处理。
三、把一列数据分割成多列数据

1.问题:现在我有一个电话本,我想将电话那列的区号与电话分开为两列,怎么办呢?
2.思路:读取数据列,使用split函数分割,然后再保存文件
import pandas as pd#读取文件datas = pd.read_excel('Tel.xlsx')#对Tel列进行分割,将数据保存在df,expand参数不能省略df=datas['Tel'].str.split('-',expand=True)datas['区号']=df[0]datas['电话']=df[1]datas.to_excel('Tel.xlsx')print(datas)***************************************** name Tel 区号 电话0 zhang1 010-8712491 010 87124911 zhang2 029-8752112 029 87521122 zhang3 09170-8712113 09170 87121133 zhang4 010-4712114 010 47121144 zhang5 010-3712115 010 37121155 wang01 020-8712116 020 87121166 wang02 010-8712117 010 87121177 wang03 021-8512118 021 85121188 wang04 010-8012119 010 80121199 wang05 0910-8712120 0910 8712120函数用法:split(sep,n,expand=false)
sep表示用于分割的字符;n表格分割成多少列;expand表示是否展开为数据款,True输出Series,False输出Dataframe。
下一期见!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









