



 本文介绍了Python处理DataFrame的多种技巧,包括将字符串转换为数字、读取CSV避免设置表头、使用isin()筛选数据、复制表格、追加数据、处理链式赋值警告、检查DataFrame的行数和列数、保存和加载数据、删除行列、重置索引、获取上级目录、文件拷贝、解析字符串中的字典、根据列值获取行索引、以及处理布尔运算时的注意事项。
本文介绍了Python处理DataFrame的多种技巧,包括将字符串转换为数字、读取CSV避免设置表头、使用isin()筛选数据、复制表格、追加数据、处理链式赋值警告、检查DataFrame的行数和列数、保存和加载数据、删除行列、重置索引、获取上级目录、文件拷贝、解析字符串中的字典、根据列值获取行索引、以及处理布尔运算时的注意事项。
1. 将python列表中的string转为数字, 利用map实现
原文件中的数字格式

f = open('filename', 'r')
inf = list(map(float, f.readlines()[0].strip().split()))
print(inf)
2. DataFrame读取csv避免第一行作为表头,header=None
f = pd.read_csv('filename.csv', header=None)3. 对DataFrame表格根据某列的内容进行切片,isin(),无需知道确切的行数

f1 = f[f['Type'].isin(['Bi'])]
print(f1)
4. isin()也可以用逻辑符连接,进行进一步筛选
f1 = f[f['X'].isin([X]) & f['Y'].isin([Y]) & (f['Z']-1.5) < 1.7]5. df.copy()可以复制之前的表格,修改新表格数据时,之前的表格不受影响
df2 = df.copy()6. 使用df.concat([df1, df2], axis=0) 将df2追加到df1末端
7. 警告”A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead“
出现这个警告是链式赋值引起的,在复制表格时候,若令df2=df1,则修改df2中的值之后,df1中对应的值也会被修改,可以用df2=df1.copy(),代替df2=df1
8. DataFrame 表格的行数、列数
df.shape[0] # 行数
df.shape[1] # 列数9. DataFrame 存储csv
df.to_csv('filename.csv') # 当前路径
df.to_csv('path/filename.csv') # 绝对路径,path = os.getcwd()10. 将DataFrame格式的多个sheet保存到excel中(csv不能保存多个sheet)需要用到openpyxl库;当尝试再次修改表格时如何避免覆盖原有表格
假设文件夹中不存在这样一个表格,则会新创建一个表格文件
def func(): # 表格d
a = pd.DataFrame([[1, 1, 1, 1], [2, 2, 2, 2], [5, 4, 3, 3], [3, 5, 3, 4]], columns=['a','b','c','d'])
return a
d = pd.DataFrame(columns=['Note1','Note2']) # 表格d
writer = pd.ExcelWriter('c.xlsx') # 创建一个新表格
c.to_excel(writer, sheet_name='c') # 将c存到excel中
e.to_excel(writer, sheet_name='d') # 将d存到excel中
writer.save()效果
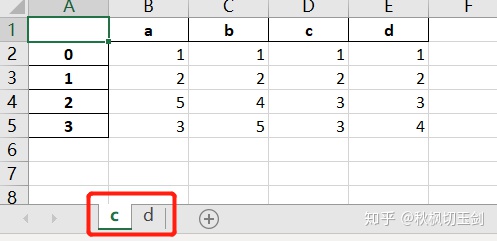
但是以上方法会覆盖已存在的表格,如果只想替换已存在表格中的某个子sheet时,就需要对代码做一些如下调整。
从网上找到的方法,使用openpyxl包的load_workbook,将原有表格用ExcelWriter打开之后的内存地址修改为load_workbook的地址,这样就可以保存进新的子表格了,但是这个方法总会将新的表格保存到一个新的子sheet里,即使sheet名相同也不会覆盖,而是会自动在sheet 名后加上‘1’以区分。有效的具体原因不清楚。
例如
from openpyxl import load_workbook
writer = pd.ExcelWriter('c.xlsx', engine='openpyxl')
book = load_workbook(writer.path)
print(writer.book) # <openpyxl.workbook.workbook.Workbook object at 0x000001A4C05FD3C8>
print(book) # <openpyxl.workbook.workbook.Workbook object at 0x000001A4C10B0080>可看到两个地址不同,加上一行代码
writer = pd.ExcelWriter('c.xlsx', engine='openpyxl')
book = load_workbook(writer.path)
writer.book = book # 加上我
print(writer.book) # <openpyxl.workbook.workbook.Workbook object at 0x000001A70B200160>
print(book) # <openpyxl.workbook.workbook.Workbook object at 0x000001A70B200160>
e.to_excel(excel_writer=writer, sheet_name='c') # 把表格e存入本地
writer.save()
writer.close()则新存储的excel文件中多了一个子sheet 'c1'
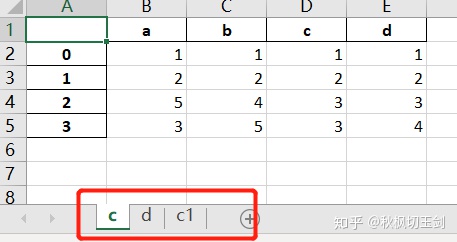
11. 使用DataFrame的检索功能要比使用for遍历快很多,格式是 df[df['列名']==sth],把满足条件的行筛选出来
12. 在处理DataFrame表格数据时,有时需要删除多行或者多列,使用df.drop(labels= 列表, axis)功能,当axis=0时删除行
假设有一表格,需要删除前三行:
df2 = df.drop(labels=[0, 1, 2], axis=0) # 也可以设置labels = range(0, 3)使用以上代码之后:
13. 在删除某些行之后,数据的索引值也被删掉了,导致索引值不连续。如果需要重设索引值,可以用 df.reset_index(drop=True), 这里drop=True是删除旧的index值,如果不写则会保存旧的索引列为一个新的列

14. 有时想要获得工作目录的上级目录,用path = os.getcwd()可以获得工作目录,而上级目录的获取方法是:
parent_path = os.path.abspath(os.path.dirname(os.getcwd()))15. 利用python拷贝文件到另一个文件夹,将路径1下的文件1拷贝到路径2下,将其命名为文件2
from shutil import copyfile
copyfile(path1 + '' + '文件名1', path2 + '' + '文件名2')16. 将字符串内的字典格式的数据转为字典
我有一个字符串,它是一个字典的列表并被字符串化了,例如
>>> a = "[{'Coordination_to_O': 4}, {'Apc_O': 2}, {'Eqt_O': 2}, {'Vac_num': 2}, {'Apc_Vac': 0}, {'Eqt_Vac': 2}]"
>>> print(type(a))
>>> <class 'str'>现在我想提取a中第一个字典格式的value值,即{'Coordination_to_O': 4}中的数据4。由于字符串里存在中括号,我需要先将a中两侧的列表格式(中括号)去掉,然后通过eval将中括号内的字典转化为真正的字典,并索引第一个字典的值。
print(eval(a.strip('[').strip(']'))[0]['Coordination_to_O'])
>>> 4 # 达成目标17 根据DataFrame的某一列的元素值获取其所在行数(index值),使用df[条件].index.tolist()
我有df2表格如下,现在我想获取'a'所在的行数

>>> index_value = df2[(df2['Seq'] == 'a')].index.tolist()
>>> print(index_value)
>>> print(type(index_value))
>>> print(df2.loc[[2], 'A']) # 0可以拿这个index_value去找到同行的其他列的值, 例如找到第3行第2列的'n'
>>> [2]
>>> <class 'list'>
>>> 2 n
Name: A, dtype: object18 使用Dataframe筛选行的时候报错:
UserWarning: Boolean Series key will be reindexed to match DataFrame index.
当对两个表格进行布尔值运算的时候,如果两个表格的index值不在同一范围,就会报错。如果只进行数学运算,则以index值为参照在相应的行进行运算。
df1 = pd.DataFrame(columns=['a', 'b'])
df1['a'] = [1, 2, 3, 4, 5]
df1['b'] = [10, 10, 40, 50, 70]
print(df1)
# 打印结果, 第一个表格
a b
0 1 10
1 2 10
2 3 40
3 4 50
4 5 70
df2 = pd.DataFrame(columns=['a', 'b'])
df2['a'] = [6]
df2['b'] = [80]
print(df2)
# 打印结果, 第二个表格
a b
0 6 80可以看到第二个表格的index是0,则当两个表格运算时,会对共有的index行进行运算,其他行以Nan补齐
print(df1['a'] + df2['a'])
# 打印结果, 两个表格相加, 可看到只有第一行相加,其他行为空
0 7.0
1 NaN
2 NaN
3 NaN
4 NaN
Name: a, dtype: float64
# 改变df2的index值,再次打印
df2.index = [3]
print(df1['a'] + df2['a'])
# 打印结果
0 NaN
1 NaN
2 NaN
3 10.0
4 NaN即使两个表格的index不在同一范围,在做数学运算的时候仍然自动补齐,不会报错
df2.index = [7]
print(df2)
# 打印结果
a b
7 6 80
print(df1['a'] - df2['a'])
# 打印结果
0 NaN
1 NaN
2 NaN
3 NaN
4 NaN
7 NaN但是,当做布尔运算的时候就会报题目中所述错误
print((df1[df1['a'] - df2['a'] > 0]))
# 打印结果
Empty DataFrame
Columns: [a, b]
Index: []
UserWarning: Boolean Series key will be reindexed to match DataFrame index.
print(df1[df1['a'] - df2['a'] > 0])因此如果利用布尔运算进行切片时,需要注意这一点,最好方法是将df2里的值提出来作为一个数字去参加运算。使用Dataframe.at[行名, 列名]
index = df2[df2['a']==6].index.tolist()[0]
val = df2.at[index, 'a']
print(val)
# 打印结果
6
print(df1[df1['a'] - val > 0])
# 打印结果
Empty DataFrame
Columns: [a, b]
Index: []
Process finished with exit code 0
# 没有报错
















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









