






使用 grep 命令来搜索多个单词要使用 grep 命令来搜索多个字符串或单词,我们该怎么做?例如我想要查找 /path/to/file 文件中的 word1、word2、word3 等单词,我怎么样命令 grep 查找这些单词呢?
grep 命令支持正则表达式匹配模式。要使用多单词搜索,请使用如下语法:
复制代码代码如下:
grep 'word1|word2|word3' /path/to/file
下的例子中,要在一个名叫 /var/log/messages 的文本日志文件中查找 warning、error 和 critical 这几个单词,输入:
复制代码代码如下:
$ grep 'warning|error|critical' /var/log/messages
仅仅只是要匹配单词(即该词两侧是单词分界符,针对西方以空格分隔的语言而言)的话,可以加上 -w 选项参数:
复制代码代码如下:
$ grep -w 'warning|error|critical' /var/log/messages
egrep 命令可以跳过上面的语法格式,其使用的语法格式如下:
复制代码代码如下:
$ egrep -w 'warning|error|critical' /var/log/messages
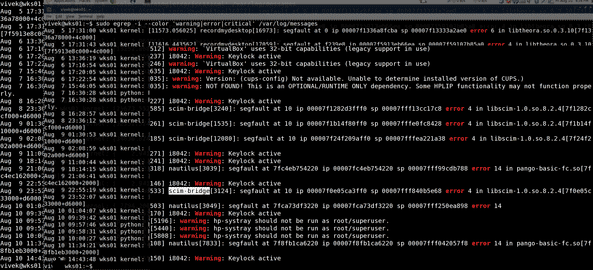
我建义您们加上 -i (忽略大小写) 和 --color 选项参数,如下示:
复制代码代码如下:
$ egrep -wi --color 'warning|error|critical' /var/log/messages
输出示例:
用 grep 命令统计匹配字符串的行数在 Linux 或 UNIX 操作系统下,对于给定的单词或字符串,我们应该怎么统计它们在每个输入文件中存在的行数呢?
您需要通过添加 -c 或者 --count 选项参数来抑制正常的输出。它将会显示对输入文件单词匹配的行数,如下所示:
复制代码代码如下:
$ grep -c vivek /etc/passwd
或者
复制代码代码如下:
$ grep -w -c vivek /etc/passwd
输出的示例:
复制代码代码如下:
1
相反的,使用 -v 或者 --invert 选项参数可以统计出不匹配的输入文件行数,键入:
复制代码代码如下:
$ grep -c vivek /etc/passwd
输出的示例:
复制代码代码如下:
45
Linux系统中的翻页命令more和less使用教程
moremore-在显示器上阅读文件的过滤器[[]]总览(SYNOPSIS)more[-dlfpcsu][-num][+/pattern][+linenum][file...][[]]描述(DESCRIPTION)More是一个过滤器,用于分页显示(一次一屏)文
在Linux笔记本上执行这句命令就能导致设备永久变砖
上个月,有用户在ArchLinux论坛发帖提问,为什么他的笔记本在运行了一个简单的rm-rf-no-preserve-root/命令之后就完全没法启动了。有Linux基础的同学应该知
全面解析Linux的grep命令中正则表达式的用法
Linux附带有GNUgrep命令工具,它支持扩展正则表达式extendedregularexpressions,而且GNUgrep在所有的Linux系统中都是默认有的。Grep命令被用于搜索定位存储在您
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









