




简介:Perl是一种多平台的脚本编程语言,以其灵活的语法和强大的文本处理能力而受到赞誉。这份“Perl中文手册 CHM”旨在为初学者和经验丰富的开发者提供一个全面的Perl学习资源。CHM格式将众多HTML文档整合为一个可搜索的帮助文件,以便用户快速定位所需信息。手册中详细介绍了Perl的基础语法、正则表达式、文件操作、模块使用、面向对象编程、异常处理、系统交互、函数库、调试技巧以及性能优化等关键知识点,并提供了丰富的实例和练习帮助读者加深理解。 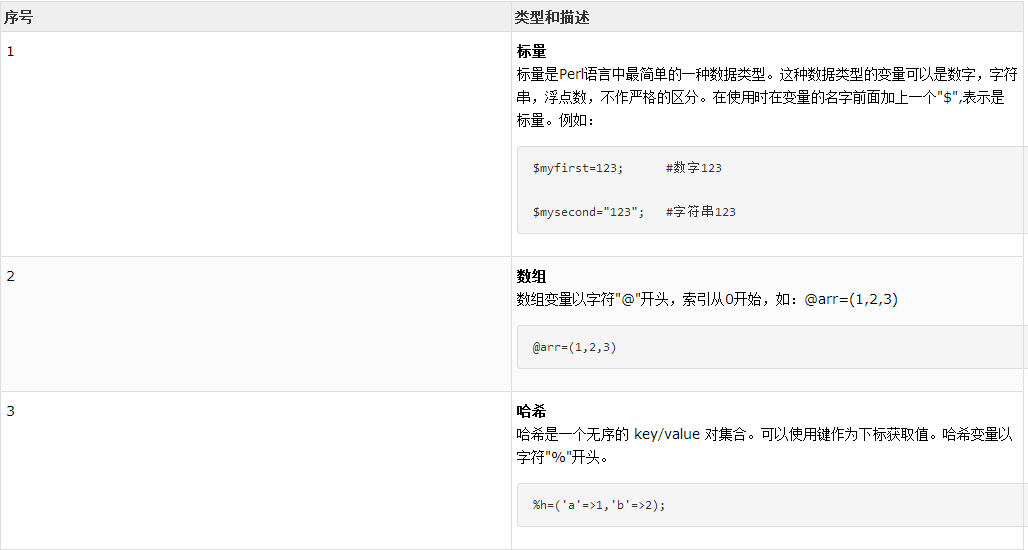
1. Perl基础语法介绍
Perl语言,全名为Practical Extraction and Report Language,是一种高效、灵活、强大的编程语言。它支持多种编程范式,包括过程式、面向对象以及功能式编程。在本章中,我们将对Perl的基础语法进行介绍,为读者理解后续章节中的高级技术和应用打下坚实的基础。
1.1 变量和数据类型
Perl语言的变量不需要显式声明数据类型,它通过变量前缀来区分不同的数据类型。主要有以下几种:
-
$符号代表标量变量,用于存储单个数据项,如整数、浮点数或字符串。 -
@符号代表数组变量,用于存储有序的字符串或数字列表。 -
%符号代表哈希变量,用于存储键值对的集合。
示例代码:
# 标量变量示例
my $name = "John";
my $age = 30;
# 数组变量示例
my @fruits = ('apple', 'banana', 'cherry');
# 哈希变量示例
my %person = ('name' => 'John', 'age' => 30);
1.2 控制结构
Perl提供了一系列的控制结构来管理程序的执行流程,包括条件语句和循环语句等。
条件语句使用 if 、 unless 、 elsif 和 else 来控制代码块的执行:
if ($age > 18) {
print "You are an adult.\n";
} elsif ($age >= 13) {
print "You are a teenager.\n";
} else {
print "You are a child.\n";
}
循环语句可以使用 for 、 foreach 、 while 、 until 等关键字:
# for循环示例
for (my $i = 0; $i < @fruits; $i++) {
print "$fruits[$i]\n";
}
# while循环示例
while ($age > 0) {
print "You have $age years left.\n";
$age--;
}
1.3 子程序与引用
子程序在Perl中定义为一组可以重复使用的代码块。使用 sub 关键字定义子程序:
sub say_hello {
my ($name) = @_;
print "Hello, $name!\n";
}
引用是Perl中非常重要的一部分,允许你传递复杂数据结构,如数组、哈希或子程序到其他子程序,或存储到变量中:
my $sub_ref = \&say_hello; # 引用一个子程序
通过以上的基础语法介绍,我们对Perl有了初步的认识,接下来,我们将继续深入学习Perl的高级特性,如正则表达式和文件操作等。
2. 正则表达式使用详解
2.1 正则表达式的基本概念
正则表达式(Regular Expression),是一种字符模式,用于匹配一组字符串中的特定字符串,广泛应用于文本处理和搜索领域。
2.1.1 正则表达式的核心组成
正则表达式由字符(characters)、元字符(metacharacters)、量词(quantifiers)、边界符(anchors)等构成。其中,字符是构成字符串的基础,如字母、数字和符号;元字符具有特殊意义,如点号( . )表示任意字符,星号( * )表示前一字符的零次或多次出现;量词用于指定字符出现的次数;边界符用于指定正则表达式的开始和结束位置。
2.1.2 字符匹配与定位
在使用正则表达式时,常常需要匹配特定的字符或字符串。字符匹配分为精确匹配和模糊匹配。精确匹配通常使用字符字面量,而模糊匹配可以使用正则表达式的特殊构造,如字符类( [a-z] 表示任意小写字母)、排除字符类( [^a-z] 表示非小写字母)。
定位则是指在目标文本中定位符合正则表达式的起始和结束位置。例如,单词边界( \b )用于确保匹配的是完整的单词,而不是单词的一部分。
2.2 正则表达式的高级特性
随着正则表达式的深入使用,其高级特性显得尤为重要,这些特性允许开发者构建复杂而精确的匹配模式。
2.2.1 捕获组与反向引用
捕获组(capturing groups)是通过括号将一部分正则表达式包围起来,使得这部分表达式匹配的字符串可以在后续处理中被引用。例如, ([a-z]+)\s+\1 匹配连续重复的单词。
反向引用(backreferences)是引用之前已经捕获的组的内容。在替换操作中, \1 、 \2 等可以用来引用第一、第二捕获组匹配的内容。
2.2.2 零宽断言与边界匹配
零宽断言(lookaround assertions)是正则表达式中的一个强大工具,它允许你声明某个位置前后应该出现(或不应出现)的模式,而不消耗任何字符。例如, (?<=foo)bar 表示匹配位于"foo"后面的"bar"。
边界匹配(word boundaries)确保匹配发生在单词的边界,如 \bfoo\b 将匹配独立的"foo"单词,而不会匹配"foobar"中的"foo"部分。
2.2.3 正则表达式的优化技巧
正则表达式的性能对文本处理的速度有着直接的影响。优化技巧包括减少回溯(例如,避免使用嵌套量词)、使用字符集代替多个选择符(如 [a-z] 优于 a|b|c|...|z )、以及使用非捕获组(如 (?:foo) )来避免不必要的内存开销。
例如,使用 ^(?>\S+\s)+$ 代替 ^(\S+\s)+$ 可以减少不必要的回溯,从而提高性能。
2.3 正则表达式应用实例
下面的表格展示了在不同场景下如何应用正则表达式的捕获组和反向引用:
| 场景 | 正则表达式示例 | 解释 | |---------------------|-------------------------------|--------------------------------------------------------------| | 验证电子邮件地址 | ^\S+@\S+\.\S+$ | 匹配形如***的电子邮件地址 | | 提取网页中的链接 | <a href="([^"]+)"> | 匹配 <a> 标签内的href属性值,即链接地址 | | 去除重复单词 | (^\s*|\b)(\w+)(?=\s+\1\b) | 匹配并删除连续出现的相同单词 |
通过以上实例,我们可以看到正则表达式在文本处理和验证中的强大应用。掌握正则表达式的使用技巧,对于任何需要进行文本分析和处理的开发者而言,都是一项宝贵的技能。
3. 文件操作技术细节
3.1 文件的读写操作
在Perl中,文件读写是日常编程的基本功之一。程序通常需要从文件中读取配置信息或数据,或者将数据写入文件以供后续使用。本节将会介绍如何在Perl中打开、读取、写入以及关闭文件。
3.1.1 文件打开与关闭
Perl通过 open 函数来打开文件。其基本用法如下:
open(my $fh, '<', 'filename.txt') or die "无法打开文件: $!";
这段代码将会打开名为 filename.txt 的文件用于读取,并将文件句柄赋给 $fh 。如果文件无法打开,则执行 die 语句,打印错误信息。
文件句柄(文件描述符)用于后续的文件读写操作。完成操作后,需要使用 close 函数关闭文件,如:
close($fh) or die "无法关闭文件: $!";
3.1.2 行读取与文本处理
Perl提供了一种便捷的方法来读取文件中的每一行,并将其存储在数组中:
open(my $fh, '<', 'filename.txt') or die "无法打开文件: $!";
my @lines = <$fh>;
close($fh) or die "无法关闭文件: $!";
这段代码将会把 filename.txt 文件中的每一行存储在 @lines 数组中。使用 chomp 函数可以去除每行末尾的换行符。
. . . 表格:文件打开模式
| 模式字符 | 描述 | |----------|--------------------------------| | < | 用于读取文件 | | > | 创建文件用于写入;如果文件存在,则截断为0字节 | | >> | 创建文件用于追加;如果文件存在,则追加到文件末尾 | | +< | 用于读写打开 | | +> | 创建文件用于读写;如果文件存在,则截断为0字节 | | +>> | 创建文件用于读写;如果文件存在,则追加到文件末尾 |
3.2 文件系统的高级操作
在处理文件和目录时,可能会涉及到更复杂的文件系统操作,例如目录遍历、文件测试、文件锁定等。
3.2.1 目录遍历与文件测试
使用 glob 函数可以列出目录中的文件:
foreach my $file (glob '*') {
print "找到文件: $file\n";
}
此外, -e , -f , -d 等文件测试运算符可以用来检查文件或目录的存在性和类型:
if (-e 'filename.txt') {
print "文件存在\n";
}
3.2.2 文件锁定与并发处理
在多线程或多进程环境中,文件锁定可以防止数据竞争和不一致性。Perl提供了 flock 函数来处理文件锁定:
open(my $fh, '+<', 'filename.txt') or die "无法打开文件: $!";
flock($fh, LOCK_EX) or die "无法获取锁: $!";
# 文件读写操作
flock($fh, LOCK_UN) or die "无法释放锁: $!";
close($fh) or die "无法关闭文件: $!";
. . . Mermaid 流程图:文件锁定与解锁流程
graph LR;
A[开始] --> B[打开文件];
B --> C[获取文件锁];
C --> D[文件读写操作];
D --> E[释放文件锁];
E --> F[关闭文件];
F --> G[结束];
3.3 高级文件操作的代码实践
下面是一个综合的Perl脚本示例,它展示了如何读取一个文件,对内容进行处理,并将结果写入另一个文件,同时应用了文件锁定机制以确保并发操作的安全性:
use strict;
use warnings;
use Fcntl qw(LOCK_EX LOCK_UN); # 导入文件锁常量
open(my $read_handle, '<', 'input.txt') or die "无法打开输入文件: $!";
open(my $write_handle, '+>', 'output.txt') or die "无法打开输出文件: $!";
flock($write_handle, LOCK_EX) or die "无法获取输出文件锁: $!";
while (my $line = <$read_handle>) {
chomp($line); # 去除行末换行符
# 这里可以添加处理逻辑
my $processed_line = process_line($line);
print $write_handle $processed_line . "\n";
}
flock($write_handle, LOCK_UN) or die "无法释放输出文件锁: $!";
close($read_handle) or die "无法关闭输入文件: $!";
close($write_handle) or die "无法关闭输出文件: $!";
sub process_line {
my $line = shift;
# 示例处理逻辑:将文本转换为小写
return lc($line);
}
在上述脚本中,我们首先打开了 input.txt 用于读取,并创建了 output.txt 用于写入。通过 flock 函数获取了输出文件的独占锁,确保在写入数据时不会有其他进程或线程干扰。每个文件操作后都进行了异常处理,以确保资源被正确释放。
通过本节的介绍,我们对Perl中文件的读写操作有了深入的了解,包括文件的打开、读取、写入和关闭等基础操作,以及文件锁定等高级技术。掌握这些技术能够帮助我们更好地管理文件资源,提高程序的健壮性和效率。
4. Perl模块的获取与应用
在本章节中,我们将探讨Perl模块的获取、安装、管理以及如何将这些模块应用于具体的项目中。Perl拥有一个庞大的模块生态系统,通过CPAN(Comprehensive Perl Archive Network)可以方便地获取和安装几乎任何你所需要的模块。了解如何高效地使用这些模块,对于提高开发效率和代码质量至关重要。
4.1 Perl模块的安装与管理
Perl模块安装和管理的便捷性是其受欢迎的一个重要原因。CPAN提供了一个用户友好的界面来帮助开发者搜索、下载和安装模块。在进行模块的安装和管理之前,了解一些基本的概念和步骤是必要的。
4.1.1 CPAN使用简介
CPAN是一个开放源代码的项目,它是一个庞大的Perl模块仓库,几乎包含了所有你能想到的模块。使用CPAN,你可以轻松安装任何模块,而无需手动下载和解压。对于大多数Perl开发环境,CPAN工具已经预装,可以直接在命令行中使用。
安装模块的基本步骤如下:
- 首先,你可以使用
cpan命令进入CPAN的命令行界面。 - 输入
install 模块名称命令来安装所需的模块。 - CPAN会自动处理模块的依赖关系,下载和安装所有依赖的模块。
- 安装过程中可能需要你进行一些交互,比如确认模块的安装位置或自动连接到互联网。
CPAN命令行界面(cpan shell)是一个功能强大的工具,它支持许多高级选项,例如:
-
autodie:自动处理模块安装时可能出现的错误。 -
o conf prerequisites_policy follow:安装模块时,CPAN会自动安装所有依赖的模块。 -
o conf build_requires_install_policy yes:在安装模块时,将安装所有编译所需依赖。
在使用CPAN时,可能会遇到的问题是如何选择最佳的镜像站点。CPAN可以自动检测并选择速度最快的镜像站点,你也可以通过设置参数来手动指定。
4.1.2 模块依赖与解决方法
在安装Perl模块时,依赖关系可能成为一项挑战。开发者经常发现,一个简单的模块安装可能会带来一系列复杂的依赖问题。幸运的是,CPAN已经为我们处理了大部分依赖关系的管理。
CPAN在安装过程中会检查模块所声明的依赖,并自动安装缺失的依赖。如果遇到某些依赖无法自动安装,CPAN会提供错误信息,并指导用户如何手动解决这些问题。
以下是一些解决依赖问题的常见方法:
- 重新配置CPAN以使用特定的代理服务器或镜像站点。
- 更新CPAN到最新版本,有时候依赖问题可能是由于旧版本CPAN的bug造成的。
- 清理并重新初始化CPAN,使用
o conf init和o conf makepl_arg等命令来重置CPAN配置。 - 手动安装缺失的依赖模块。
- 使用
force install命令来强制安装模块,尽管这可能会导致未来的兼容性问题。
4.2 模块的应用实例分析
Perl模块是Perl编程的核心。它们为开发者提供了大量即插即用的功能,可以显著提高开发效率,并帮助开发者避免重复发明轮子。
4.2.1 实用模块推荐与应用场景
Perl社区有许多实用的模块,可以根据不同场景推荐使用。以下是一些推荐模块以及它们的典型应用场景:
-
Modern::Perl:简化Perl语法,特别是对于Perl 5.10及以上版本。它为现代Perl开发提供了一组约定。 -
Moose:一个强大的Perl面向对象框架,为Perl提供了类似Perl 6的属性和角色支持。 -
Plack:Perl的Web服务器网关接口框架,用于构建Web应用和服务。 -
DBI:数据库接口模块,提供了一个数据库无关的接口,用于在Perl中操作各种数据库系统。
这些模块能够覆盖从基础编程到Web开发等多个场景。
4.2.2 模块代码的集成与调试
在将模块集成到你的Perl脚本或应用中时,需要遵循一定的步骤以确保一切正常工作。以下是一个通用的模块集成流程:
- 在你的Perl脚本中,使用
use或require语句来加载模块。 - 确保你的项目中包含了模块的依赖,并且正确地放置在Perl的库路径中。
- 如果需要,配置模块并调用模块提供的功能。
这里是一个简单的示例代码块,演示如何加载并使用一个模块:
use Modern::Perl;
use DBI;
# 连接数据库
my $dbh = DBI->connect("dbi:SQLite:dbname.db", "", "", { RaiseError => 1 })
or die "无法连接数据库: $DBI::errstr";
# 创建一个数据库句柄并执行查询
my $sql = "SELECT * FROM users";
my $sth = $dbh->prepare($sql);
$sth->execute();
# 遍历结果集
while (my @row = $sth->fetchrow_array) {
print "@row\n";
}
# 关闭数据库句柄
$sth->finish;
$dbh->disconnect;
调试模块代码时,可以使用Perl的内置调试器。它提供了设置断点、单步执行、堆栈跟踪等多种调试功能。你可以在命令行中使用 perl -d 来启动调试器,或者在你的代码中添加 use Devel::ptkdb; 来启用图形化的调试界面。
# 使用Devel::ptkdb调试器
use Devel::ptkdb;
my $self = { name => 'foo' };
my $other = { name => 'bar' };
# 在此处设置一个断点,以便调试
break subname => 0x00aabbcc;
# 启动调试器
my $db = Devel::ptkdb->new();
$db->run;
通过上述步骤,你将能够有效地集成和调试Perl模块,从而在你的项目中利用这些强大的功能。
5. 面向对象编程概念
面向对象编程(Object-Oriented Programming,简称OOP)是现代编程语言中的一种核心编程范式。Perl语言虽然最初不是完全以OOP为中心设计的,但是它支持OOP并且提供了强大的面向对象编程的能力。本章将详细介绍Perl面向对象编程的基础概念和高级技术。
5.1 面向对象编程基础
面向对象编程是一种编程范式,它使用“对象”来表示数据和处理数据的代码。对象可以包含数据(通常称为属性或字段)以及可以操作这些数据的方法(函数或行为)。Perl的面向对象编程通过几个关键概念来实现,包括类、对象、封装、继承和多态性。
5.1.1 类与对象的定义
在Perl中,类是构建对象的模板,它定义了对象的属性和方法。Perl并不强制使用严格意义上的类定义,因为它是一种松散类型的语言,但是通常使用 package 关键字来声明类。对象是类的实例,可以通过类来创建。
示例代码:
package Person;
sub new {
my $class = shift;
my $self = {};
bless $self, $class;
return $self;
}
sub speak {
print "Hello, I am a Person.\n";
}
在上面的代码中,我们定义了一个 Person 类,并为它提供了 new 构造函数和 speak 方法。 new 方法使用 bless 函数将匿名哈希(通常作为对象的内部结构)与类关联起来,使它成为一个对象。
对象通常使用 new 方法来创建,如下所示:
my $person = Person->new();
$person->speak();
5.1.2 封装、继承与多态性
封装是指将数据和操作数据的代码捆绑在一起,对外隐藏对象的实现细节。Perl中可以通过私有属性和方法来实现封装。继承是面向对象编程中的一种机制,允许一个类获得另一个类的属性和方法。多态性是指允许不同类的对象对同一消息做出响应的能力。
封装:
在Perl中,可以通过前缀符号来控制变量的作用域,例如使用 my 声明的变量为局部变量,而使用 our 声明的变量为包变量。因此,可以在构造函数内部使用 my 来创建私有属性,而使用 our 来创建公有属性。
继承:
Perl通过 @ISA 数组来实现继承,这个数组包含了基类的名字。当调用一个方法时,Perl会在对象的类及其继承链上的所有类中搜索该方法。
package Student;
use parent 'Person';
sub new {
my $class = shift;
my $self = $class->SUPER::new();
bless $self, $class;
return $self;
}
sub study {
print "I am studying.\n";
}
多态性:
在Perl中实现多态性,需要依靠继承和方法重载。当使用继承时,子类可以覆盖或扩展基类的方法。这意味着我们可以用相同的调用方式来调用不同对象上的方法,但每个对象会根据其自己的类来响应。
5.2 高级面向对象技术
Perl的面向对象编程不仅限于基础的类和对象定义,它还支持更多的高级面向对象技术,如构造函数与析构函数、方法重载与克隆等。
5.2.1 构造函数与析构函数
在Perl中, new 方法通常用来创建对象,这是类的一个构造函数。与之对应的是析构函数,它在对象生命周期结束时被调用,通常使用 DESTROY 方法实现。
示例代码:
sub new {
my $class = shift;
my $self = { name => 'Anonymouse', age => 30 };
bless $self, $class;
return $self;
}
sub DESTROY {
print "The object has been destroyed.\n";
}
5.2.2 方法重载与克隆
方法重载允许在不同的上下文中使用同一个方法名,但执行不同的代码。Perl中的方法重载是通过特殊的函数 AUTOLOAD 来实现的。克隆是创建对象的副本,可以通过 UNIVERSAL::can 和 UNIVERSAL::copy 来实现。
示例代码:
sub AUTOLOAD {
my $self = shift;
my $method = $AUTOLOAD;
$method =~ s/^.*:://; # 移除命名空间前缀
# 假设我们有get和set方法
if ($method =~ /^get/) {
my $attr = lc($method =~ s/^get//);
return $self->{$attr};
} elsif ($method =~ /^set/) {
my ($attr, $value) = ($method =~ s/^set//, pop);
$self->{$attr} = $value;
}
}
通过上述代码,我们定义了一个类,其中 AUTOLOAD 方法允许我们在不事先定义所有方法的情况下,动态地处理 get 和 set 方法的调用。
本章介绍了Perl面向对象编程的基础,包括类和对象的定义、封装、继承以及多态性等核心概念。同时,我们也探索了一些高级技术,比如构造函数与析构函数、方法重载与克隆。在下一章节中,我们将进一步探讨异常处理的基本原理和高级技巧。
6. 异常处理实践
异常处理是编程中的一个重要方面,它能够帮助程序在遇到意外情况时优雅地处理错误,避免程序崩溃。Perl 语言提供了一套相对完善的异常处理机制,允许开发者编写更为健壮的代码。
6.1 异常处理的基本原理
6.1.1 错误类型与异常对象
在 Perl 中,错误可以是简单的警告信息,也可以是终止程序的致命错误。异常对象则是对错误的封装,它可以包含错误类型、错误消息以及一些其他相关信息。
Perl 使用 eval 块来捕获异常。如果在 eval 块中发生异常,它会被 die 函数抛出,并且可以在 eval 块外部被捕获。
eval {
die "An error occurred!\n";
};
if ($@) {
print "Caught an error: $@";
}
在这个例子中, eval 块内部的 die 被调用会抛出一个异常, $@ 变量将会包含异常信息。
6.1.2 语句块与异常捕获
异常可以被 eval 语句块捕获。如果 eval 块执行过程中没有遇到任何异常,则返回 undef ;如果遇到异常,则 eval 块返回异常信息字符串。
通常我们会检查 $@ 是否包含错误信息来确定是否需要执行错误处理代码。
eval {
# 代码可能会抛出异常的代码块
# ...
};
if ($@) {
# 执行错误处理逻辑
handle_error($@);
} else {
# 执行正常逻辑
}
6.2 异常处理的高级技巧
6.2.1 异常的抛出与传播
在 Perl 中,异常抛出通常是通过 die 函数完成的,该函数可以抛出一个包含错误信息的字符串。
为了更好的异常处理实践,我们可以定义自定义的异常类,这些类继承自 Perl 的 Exception 类,使得错误处理更加灵活和强大。
package MyApp::Exception::UserDefined;
use parent 'Exception';
# 可以添加其他属性和方法
sub new {
my ($class, %args) = @_;
my $self = $class->SUPER::new("User defined error: " . $args{message});
# 设置额外的属性
return bless $self, $class;
}
# 抛出自定义异常
die MyApp::Exception::UserDefined->new(message => "An error occurred.");
6.2.2 错误日志与调试信息
异常处理不应该仅限于捕获错误,还应该包括将错误信息记录到日志文件中,这有助于分析问题的根源。
我们可以使用 Perl 的 Log::Log4perl 模块来记录详细的错误信息和调试信息。
use Log::Log4perl;
# 初始化日志系统
Log::Log4perl->init(<<'LOGCFG');
log4perl.logger = INFO, LOGFILE
log4perl.appender.LOGFILE = Log::Log4perl::Appender::File
log4perl.appender.LOGFILE.filename = /path/to/your/logfile.log
log4perl.appender.LOGFILE.layout = Log::Log4perl::Layout::PatternLayout
log4perl.appender.LOGFILE.layout.ConversionPattern = %-5p %c - %m%n
LOGCFG
# 记录日志信息
warn "Warning message";
error "Error message";
debug "Debug message"; # 只有在设置为 DEBUG 级别时才会记录
在这个配置中,日志系统被初始化为记录信息级别的日志,并将日志记录到指定的文件中。通过适当配置日志级别,可以轻松地调整所需记录的详细程度。
异常处理不仅仅关乎代码的健壮性,它还涉及到调试、日志记录和错误分析等多个层面。通过在 Perl 中合理使用异常处理机制,可以显著提高程序的可靠性和维护性。下一章,我们将探讨如何通过系统交互来扩展 Perl 程序的能力。
简介:Perl是一种多平台的脚本编程语言,以其灵活的语法和强大的文本处理能力而受到赞誉。这份“Perl中文手册 CHM”旨在为初学者和经验丰富的开发者提供一个全面的Perl学习资源。CHM格式将众多HTML文档整合为一个可搜索的帮助文件,以便用户快速定位所需信息。手册中详细介绍了Perl的基础语法、正则表达式、文件操作、模块使用、面向对象编程、异常处理、系统交互、函数库、调试技巧以及性能优化等关键知识点,并提供了丰富的实例和练习帮助读者加深理解。


















 1496
1496

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









