






本发明涉及计算机网络技术领域,确切地说是一种网页数据结构化提取的方法。
背景技术:
随着互联网的快速发展,网站页面的表示技术越来越多样化;在舆情领域中,都会涉及到网页结构化数据的提取,在多数情况下,为了便于数据分析,一般会提取标题、正文、发布时间、作者等结构化数据;排除不需要的干扰信息;可以说提取数据结果的好坏,直接影响数据分析结果的好坏。
目前主流的提取技术主要是基于规则的提取方式,例如依赖正则表达式的规则提取方式,该方式提取精准,但是互联网的复杂多样性,导致该方式规则录入的工作量非常巨大,而且网站升级改版就可以导致原有的正则表达式不可用,因此无法适用于全网数据采集的场景。
技术实现要素:
本发明要解决的技术问题是目前主流的提取技术主要是基于规则的提取方式,例如依赖正则表达式的规则提取方式,该方式提取精准,但是互联网的复杂多样性,导致该方式规则录入的工作量非常巨大,而且网站升级改版就可以导致原有的正则表达式不可用,因此无法适用于全网数据采集的场景。
为解决上述技术问题,本发明采用如下技术手段:
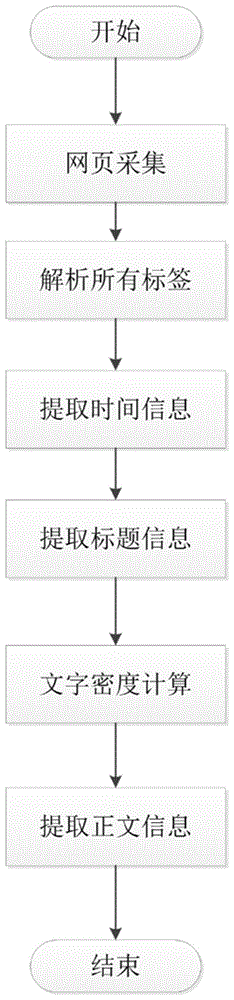
一种网页数据结构化提取的方法,网页数据结构化提取方法:
步骤1:网页源代码获取:获取html源代码信息为初始信息;
步骤2:解析页面标签:解析初始信息并遍历所有的页面标签;
步骤3:提取时间信息:提取html里面的时间信息;
步骤4:判断标题特征:解析页面标签,并判断具有标题特征的信息;
步骤5:提取信息:提取所有标签的文字长度,基于文字长度,计算文字密度,根据文字密度的分布提取正文内容;
步骤6:完成分析:完成对网页数据结构化提取的分析。
本发明需要解决的技术问题是提供一个准确率高并且分析速度快的网页正文提取方法。
作为优选,本发明更进一步的技术方案是:
所述的提取时间信息通过正则表达式实现。
本发明的优点:可以不基于规则提取,适用于大规模数据采集的业务场景;支持网页的发布时间、标题、正文内容的提取;不受网页排版、布局的影响。
附图说明
图1为本发明的结构框图。
具体实施方式
下面结合实施例,进一步说明本发明。
参见图1可知,本发明一种网页数据结构化提取的方法,网页数据结构化提取方法:
步骤1:网页源代码获取:获取html源代码信息为初始信息;
步骤2:解析页面标签:解析初始信息并遍历所有的页面标签;
步骤3:提取时间信息:提取html里面的时间信息;提取时间信息通过正则表达式实现。
步骤4:判断标题特征:解析页面标签,并判断具有标题特征的信息;
步骤5:提取信息:提取所有标签的文字长度,基于文字长度,计算文字密度,根据文字密度的分布提取正文内容;
步骤6:完成分析:完成对网页数据结构化提取的分析。
本发明的关键点:基于文字密度,提取正文内容的算法;不基于规则提取的数据处理流程。
由于以上所述仅为本发明的具体实施方式,但本发明的保护不限于此,任何本技术领域的技术人员所能想到本技术方案技术特征的等同的变化或替代,都涵盖在本发明的保护范围之内。














 9857
9857











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









