







快速排序是一种最坏情况时间复杂度为
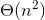 的排序算法。虽然最坏情况的时间复杂度很差,在在实际应用中是最好的选择,平均性能很好:期望时间复杂度
的排序算法。虽然最坏情况的时间复杂度很差,在在实际应用中是最好的选择,平均性能很好:期望时间复杂度
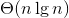 ,而且
,而且
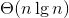 隐含的常数因子非常小。另外,它还能够进行原排序,在虚拟环境中也能很好工作。基于随机抽样的快速排序算法,在输入元素互异的情况下,期望运行时间为
隐含的常数因子非常小。另外,它还能够进行原排序,在虚拟环境中也能很好工作。基于随机抽样的快速排序算法,在输入元素互异的情况下,期望运行时间为
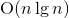 。
。
1.基本思想
快速排序利用了分治策略。分治策略可以分为3个步骤:
分解:将问题划分为一些子问题,子问题的形式与原问题一样,只是规模更小。
解决:递归的求解出子问题。如果子问题的规模足够小,则停止递归,直接求解。
合并:将子问题的解组合成原问题的解。
对一个典型的子数组A[p..r]进行快速排序的分治过程如下:
分解:数组A[p..r]被划分为两个(可能为空)子数组A[p..q-1]和A[q+1..r],使得A[p..q-1]中的每一个元素都小于等于A[q],而A[q+1..r]中的每个元素都大于A[q]。其中计算下标q也是划分过程的一部分。
解决:通过递归调用快速排序,对子数组A[p..q-1]和A[q+1..r]进行排序。
合并:因为子数组都是原址排序的,所以不需要合并操作。
2.详细过程
快速排序的伪代码如下:
 ,为了排序数组A的全部元素,初始调用QUICKSORT(A, 1, A.length)。
,为了排序数组A的全部元素,初始调用QUICKSORT(A, 1, A.length)。
其中最关键的部分就是数组的划分PARTITION,它实现了对子数组A[p..r]的原址重排。伪代码如下:
 。
。
这里的PARTITION程序选择x&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 602
602











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









