






RAID 10
和RAID 01相反,RAID10是先做RAID1,再做RAID0,如下图所示:
RAID10和RAID01在读写速度上没有什么太大的差别,但是RAID10的数据安全性比较高,若下图左边那组RAID1中磁盘损坏了一个,另外一个也能用,右边那组RAID1再损坏一个数据也是恢复的,除非一组RAID1中的磁盘都坏掉了。
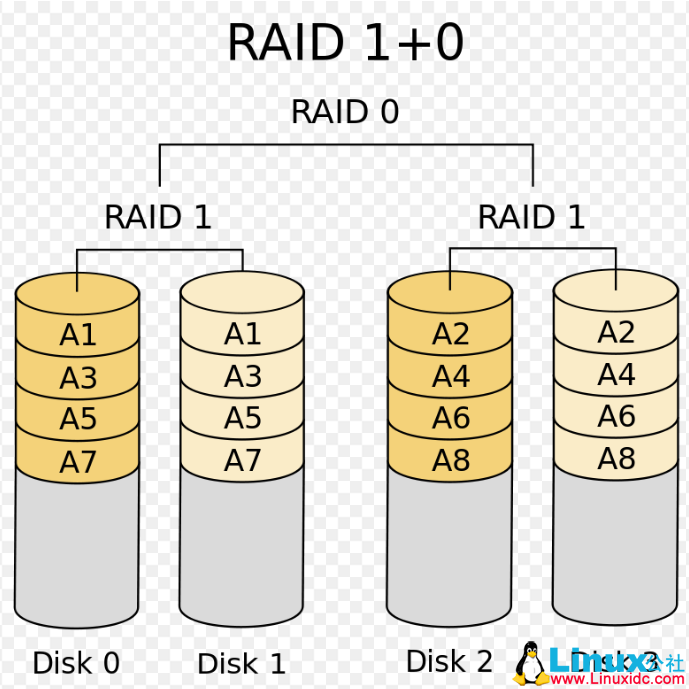
RAID 10的优缺点:
1)较高的容错能力
2)RAID10需要N个磁盘(N>=4)
RAID 50
RAID 50是RAID5和RAID0的组合,先做RAID5,再做RAID0,RAID 5至少需要3颗硬盘,因此要以多组RAID 5构成RAID 50,至少需要6颗硬盘,如下图。
在底层的任意一组或者多组的RAID5中出现了一个磁盘的损坏是可以接受的,但是若出现了2个或者以上的磁盘损坏,整个RAID50就会损坏。
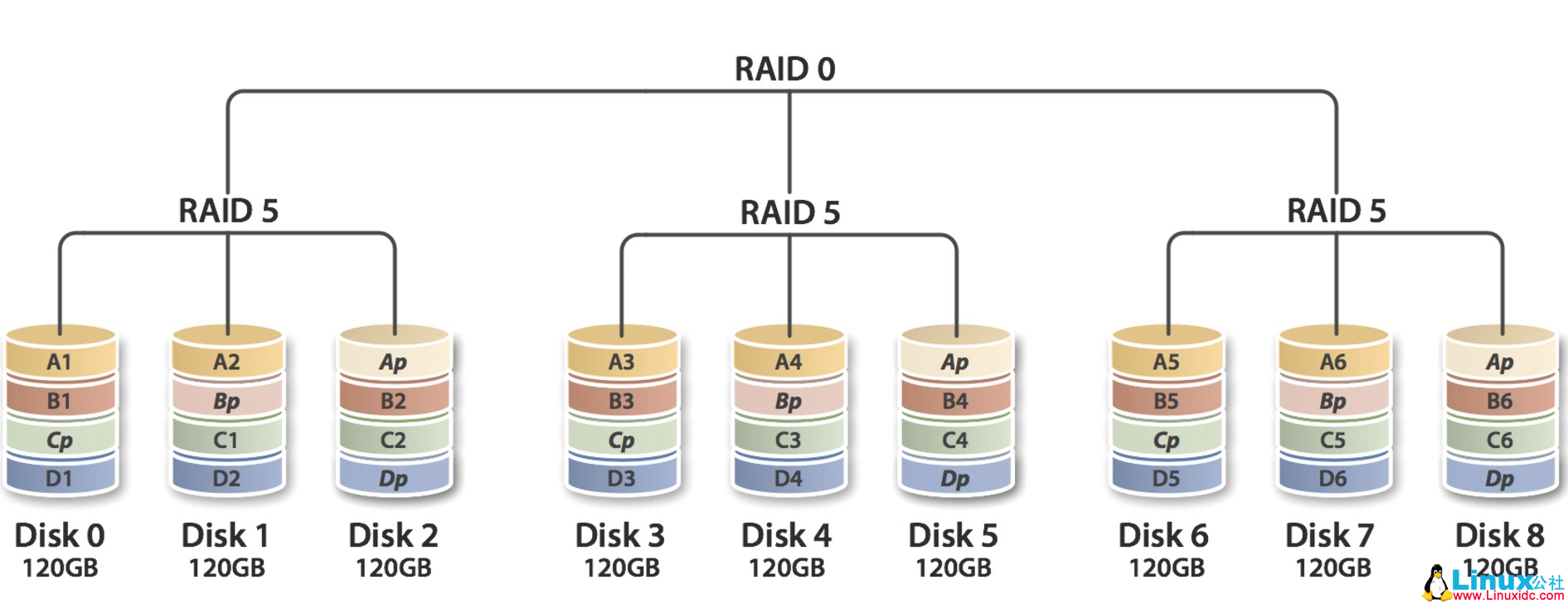
RAID50的优缺点:
1)较高的容错能力
2)RAID10需要N个磁盘(N>=6)
JBOD
Just a Bunch of Disks,能够将多块磁盘的空间合并起来的一个连续的空间,可靠性较低。
在Linux系统上实现Software RAID
在CentOS中,使用模块化得工具mdadm,如果没有可以使用:
yum -y install mdadm
基本用法如下:
命令的语法格式:mdadm [mode] [options]
-C:创建模式-n #: 使用#个块设备来创建此RAID;-l #:指明要创建的RAID的级别;-a {yes|no}:自动创建目标RAID设备的设备文件;-c CHUNK_SIZE: 指明块大小;-x #: 指明空闲盘的个数;-D:显示raid的详细信息
mdadm-D /dev/md#
管理模式:-f:标记指定磁盘为损坏-a:添加磁盘-r:移除磁盘
停止md设备:
mdadm-S /dev/md#
举例:创建一个可用空间为10G的RAID1设备,文件系统为ext4,有一个空闲盘,开机可自动挂载至/backup目录。
先来分析一下:RAID1为镜像磁盘阵列,最少需要2个磁盘,可用空间为10G,即磁盘最小大小为10G即可,我们这里就使用1块硬盘的不同分区来模拟各个磁盘,每个10G:
[root@localhost ~]# fdisk -l /dev/sdb
Disk/dev/sdb: 128.8 GB, 128849018880bytes255 heads, 63 sectors/track, 15665cylinders
Units= cylinders of 16065 * 512 = 8225280bytes
Sector size (logical/physical): 512 bytes / 512bytes
I/O size (minimum/optimal): 512 bytes / 512bytes
Disk identifier:0xf9b59c0fDevice Boot Start End Blocks Id System/dev/sdb1 1 1306 10490413+ 83Linux/dev/sdb2 1307 2612 10490445 83Linux/dev/sdb3 2613 3918 10490445 83 Linux
使用以下命令创建RAID1系统,-C为创建模式,/dev/md0设备文件名,-n 2:使用2个块设备创建此RAID,-x 1:指定1个空闲盘的,-l:指定硬盘RAID等级,-a yes:自动创建RAID的设备文件,/dev/adb{1,2,3}:指定磁盘位置
[root@localhost ~]# mdadm -C /dev/md0 -n 2 -x 1 -l 1 -c 128 -a yes /dev/sdb{1,2,3}
mdadm: Note: this array has metadata at the start and
may not be suitable as a boot device. If you plan to
store'/boot'on this device please ensure that
your boot-loader understands md/v1.x metadata, or use--metadata=0.90Continue creating array?y
mdadm: Defaulting to version1.2metadata
mdadm: array/dev/md0 started.
使用 cat /proc/mdstat 查看RAID构建的进度和预期完成的时间:
unused devices: [root@localhost~]# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb3[2](S) sdb2[1] sdb1[0]10482176 blocks super 1.2 [2/2] [UU]
[=============>.......] resync = 68.6% (7200128/10482176) finish=0.2min speed=200001K/sec
unused devices:[root@localhost~]# cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sdb3[2](S) sdb2[1] sdb1[0]10482176 blocks super 1.2 [2/2] [UU]
unused devices:
查看RAID1的详情:
[root@localhost ~]# mdadm -D /dev/md0/dev/md0:
Version :1.2Creation Time : Sun Jul30 05:16:32 2017Raid Level : raid1
Array Size :10482176 (10.00 GiB 10.73GB)
Used Dev Size :10482176 (10.00 GiB 10.73GB)
Raid Devices :2Total Devices :3Persistence : Superblock is persistent
Update Time : Sun Jul30 05:17:25 2017State : clean
Active Devices :2Working Devices :3Failed Devices :0Spare Devices :1Name : localhost.localdomain:0(local to host localhost.localdomain)
UUID : a46c7642:a46e274a:05923aeb:4c1ae0e9
Events :17Number Major Minor RaidDevice State0 8 17 0 active sync /dev/sdb11 8 18 1 active sync /dev/sdb22 8 19 - spare /dev/sdb3
格式化RAID1为ext4文件系统:
[root@localhost ~]# mkfs.ext4 /dev/md0
mke2fs1.41.12 (17-May-2010)
文件系统标签=操作系统:Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe width=0blocks655360 inodes, 2620544blocks131027 blocks (5.00%) reserved forthe super user
第一个数据块=0Maximum filesystem blocks=2684354560
80 block groups
32768 blocks per group, 32768fragments per group8192inodes per group
Superblock backups stored on blocks:32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632正在写入inode表: 完成
Creating journal (32768blocks): 完成
Writing superblocks and filesystem accounting information: 完成
This filesystem will be automatically checked every35mounts or180 days, whichever comes first. Use tune2fs -c or -i to override.
将/dev/md0挂载到/backup目录下:
[root@localhost ~]# mount /dev/md0 /backup/[root@localhost~]#
[root@localhost~]# dfFilesystem 1K-blocks Used Available Use%Mounted on/dev/mapper/VolGroup-lv_root 51606140 1122252 47862448 3% /tmpfs953276 0 953276 0% /dev/shm/dev/sda1 495844 33466 436778 8% /boot/dev/mapper/VolGroup-lv_home 67708512 184084 64085020 1% /home/dev/md0 10317624 154100 9639416 2% /backup
可以使用 -f 将其中的某个磁盘模拟为坏的故障硬盘
[root@localhost backup]# mdadm /dev/md0 -f /dev/sdb1
mdadm: set/dev/sdb1 faulty in /dev/md0
再来看一下RAID1的详细信息,/dev/sdb3状态变为active
[root@localhost backup]# mdadm -D /dev/md0/dev/md0:
Version :1.2Creation Time : Sun Jul30 05:16:32 2017Raid Level : raid1
Array Size :10482176 (10.00 GiB 10.73GB)
Used Dev Size :10482176 (10.00 GiB 10.73GB)
Raid Devices :2Total Devices :3Persistence : Superblock is persistent
Update Time : Sun Jul30 05:37:02 2017State : clean
Active Devices :2Working Devices :2Failed Devices :1Spare Devices :0Name : localhost.localdomain:0(local to host localhost.localdomain)
UUID : a46c7642:a46e274a:05923aeb:4c1ae0e9
Events :38Number Major Minor RaidDevice State2 8 19 0 active sync /dev/sdb31 8 18 1 active sync /dev/sdb20 8 17 - faulty /dev/sdb1
使用 -r 选项能够移除坏的硬盘
[root@localhost backup]# mdadm /dev/md0 -r /dev/sdb1
mdadm: hot removed/dev/sdb1 from /dev/md0
好的,我们再来添加一块分区当做磁盘
[root@localhost backup]# fdisk /dev/sdb
WARNING: DOS-compatible mode is deprecated. It's strongly recommended to
switch off the mode (command 'c') and change display units to
sectors (command'u').
Command (mforhelp): n
Command action
e extended
p primary partition (1-4)
p
Selected partition4First cylinder (3919-15665, default 3919):
Using default value3919Last cylinder,+cylinders or +size{K,M,G} (3919-15665, default 15665): +10G
Command (mfor help): wThe partition table has been altered!Calling ioctl() to re-read partition table.
WARNING: Re-reading the partition table failed with error 16: 设备或资源忙.
The kernel still uses the old table. The new table will be used at
the next reboot or after you run partprobe(8) or kpartx(8)
咦,有告警!因为当前的磁盘已经有分区被挂载当根文件系统的目录上了,内核没有识别,我们来查看/proc/parttions,果真没有识别
[root@localhost backup]# cat /proc/partitions
major minor #blocks name8 16 125829120sdb8 17 10490413sdb18 18 10490445sdb28 19 10490445sdb38 0 125829120sda8 1 512000sda18 2 125316096sda2253 0 52428800 dm-0
253 1 4096000 dm-1
253 2 68788224 dm-2
9 0 10482176 md0
使用以下命令通知内核强制重读以下磁盘分区表
[root@localhost backup]# partx -a /dev/sdb
添加/dev/sdb4到RAID1
[root@localhost backup]# mdadm /dev/md0 -a /dev/sdb4
mdadm: added/dev/sdb4
查看RAID1的详细信息,/dev/sdb4成功被加入
[root@localhost backup]# mdadm -D /dev/md0/dev/md0:
Version :1.2Creation Time : Sun Jul30 05:16:32 2017Raid Level : raid1
Array Size :10482176 (10.00 GiB 10.73GB)
Used Dev Size :10482176 (10.00 GiB 10.73GB)
Raid Devices :2Total Devices :3Persistence : Superblock is persistent
Update Time : Sun Jul30 05:51:52 2017State : clean
Active Devices :2Working Devices :3Failed Devices :0Spare Devices :1Name : localhost.localdomain:0(local to host localhost.localdomain)
UUID : a46c7642:a46e274a:05923aeb:4c1ae0e9
Events :40Number Major Minor RaidDevice State2 8 19 0 active sync /dev/sdb31 8 18 1 active sync /dev/sdb23 8 20 - spare /dev/sdb4
设置开机可以自动挂载只/backup目录下,修改配置文件/etc/fstab即可
#
#/etc/fstab
# Created by anaconda on Fri Jul28 06:34:35 2017#
# Accessible filesystems, by reference, are maintained under'/dev/disk'# Seeman pages fstab(5), findfs(8), mount(8) and/or blkid(8) for more info#/dev/mapper/VolGroup-lv_root / ext4 defaults 1 1UUID=bc67ad74-46b3-4abc-b8a7-c4fb7cd6552a /boot ext4 defaults 1 2
/dev/mapper/VolGroup-lv_home /home ext4 defaults 1 2
/dev/mapper/VolGroup-lv_swap swap swap defaults 0 0tmpfs/dev/shm tmpfs defaults 0 0devpts/dev/pts devpts gid=5,mode=620 0 0sysfs/sys sysfs defaults 0 0proc/proc proc defaults 0 0
/dev/md0 /backup ext4 defaults 0 0
小知识点:
在查看RAID创建过程的进度时候,可加上watch命令动态查看创建RAID的进度
watch [options] 'COMMAND'
选项
-n# :指定刷新间隔,单位秒
watch -n1 'cat /proc/mdstat'
















 8591
8591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









