






正则表达式的分组及在pandas中的实用操作
1. 正则表达式分组
1.1 分组的模式
1.2 分组的实际操作
1.2.1 邮箱号码匹配
1.2.2 标签信息匹配
2. pandas中的应用操作
2.1 导入库,读取文件数据,并输出指定的字段
2.2 提取数据,创建新字段
3. 小结
之前的博客中已经讲解了相关的正则表达式的一些基础的内容,可见:正则1,正则2,正则3,正则4这里补充一下正则表达式分组的相关内容以及结合pandas使用时候的实际操作
1. 正则表达式分组
1.1 分组的模式
字符
功能
(ab)
将括号中的字符作为一个分组
\num
引用分组的num匹配到的字符串
(?P)
分组起名
(?P=name)
引用别名为name分组匹配到的字符串
1.2 分组的实际操作
1.2.1 邮箱号码匹配
举个简单的应用就是匹配邮箱地址,由于存在不同类型的邮箱,这里只列举163,126和qq邮箱,执行操作如下
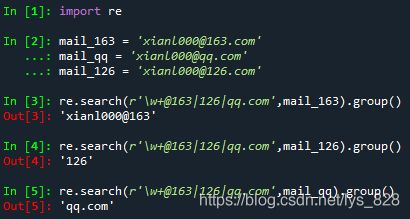
发现匹配的结果并不是我们希望得到的那样,因此这里就要用到分组匹配的方式,也就是将存在多种可能性结果匹配的方式进行分组,具体操作如下
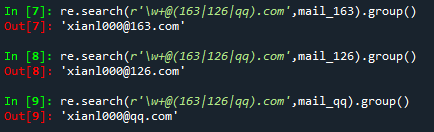
1.2.2 标签信息匹配
1) 数字分组命名
比如在爬虫过程中,有时候想偷懒不想分析网页的结构,这时候就可以直接使用正则表达式匹配标签,从而获得想要的内容,简单的举例如下
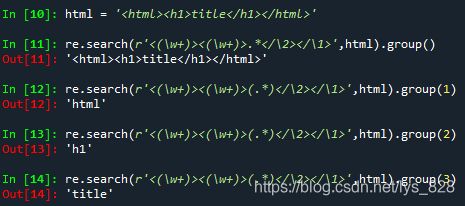
其中group()默认返回的满足匹配要求的字符串
分组后,如果要提取每个分组中的内容,可以按照默认的顺序进行数据的提取,从数字0开始
其中0代表匹配成功的全部的字符串的内容(等同于直接直接group(),也就是说0可以不写),之后1,2,3就是按照括号分组出现的次序,进行依次提取数据
2) 自定义分组命名
当要匹配或者分组的类容较多时候,如果再使用数字命名的方式,提取数据的时候就会显得很不方便(pandas中为了方便创建满足的字段),因此就有了自定义分组命名的需求,为了方便查看,没有直接截图,这里将运行结果复制粘贴到代码区
In [16]: re.search(r'\w+)>\w+)>(?P.*)(?P=biaoti)>(?P=wangye)>',html).group('wangye')
Out[16]: 'html'
In [17]: re.search(r'\w+)>\w+)>(?P.*)(?P=biaoti)>(?P=wangye)>',html).group('biaoti')
Out[17]: 'h1'
In [18]: re.search(r'\w+)>\w+)>(?P.*)(?P=biaoti)>(?P=wangye)>',html).group('neirong')
Out[18]: 'title'
注意:在自定义分组命名的时候,匹配的正则表达式要在命名字符的后面,分组括号的前面,名称可以自由选取
2. pandas中的应用操作
比如要分析房价的影响因素的时候,要从描述字段中提取房源所处的公交情况和具体的几室几厅时候,示例的文件数据内容如下
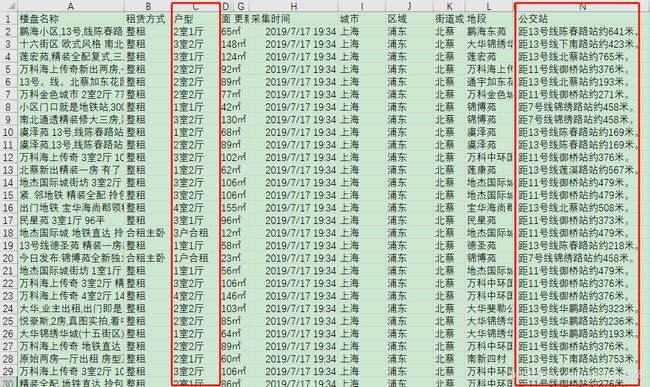
可以从数据中看出,这两个字段都是有大量相同的字符数据,因此可以直接使用正则表达式分组进行符合要求的数据提取,并利用自定义分组命名的方式创建新列(新字段),操作如下
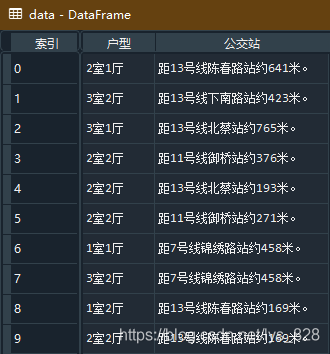
2.1 导入库,读取文件数据,并输出指定的字段
import pandas as pd
data = pd.read_csv(r'C:\Users\86177\Desktop\租房信息.csv')
data = data[['户型','公交站']]
data.head(10)
→ 输出的结果为:
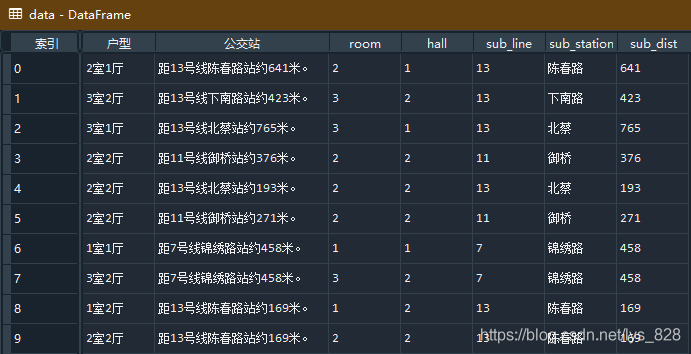
2.2 提取数据,创建新字段
room_type = data['户型'].str.extract('(?P\d+)室(?P\d+)厅')
subway = data['公交站'].str.extract('距(?P\d+)号线(?P\w+)站约(?P\d+)米。')
data = pd.concat([data, room_type, subway],axis = 1)
data.head(10)
→ 输出的结果为:(最终就直接多出来处理好的5个字段)
3. 小结
使用正则表达式分组的方式除了在爬虫中提取指定格式下的满足数据外,也可以使用在pandas中用于数据处理(提取满足数据并创建新列)
博客中使用的租房信息.csv文件已经上传至资源














 591
591











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









