







转自LDA数学八卦
在 Machine Learning 中,LDA 是两个常用模型的简称: Linear Discriminant Analysis 和 Latent Dirichlet Allocation,
在这篇文章中我们主要八卦的是后者。LDA 是一个在文本建模中很著名的模型,类似于 SVD, PLSA 等模型, 可以用于浅层语义分析,在文本语义分析中是一个很有用的模型。很不幸的是,这个模型中涉及的数学知识有点多,
包括 Gamma 函数, Dirichlet 分布, Dirichlet-Multinomial 共轭, Gibbs Sampling,
Variational Inference, 贝叶斯文本建模,PLSA 建模, 以及 LDA 文本建模。
这篇文章的主要目标,就是科普在学习理解LDA 模型中,需要了解的一些重要的数学知识。
预设的读者是做自然语言处理、机器学习、数据挖掘方向的工程师,
要读懂这篇科普,需要的数学基础知识基本上不超过陈希孺先生的《概率论与数理统计》这本书。
文章标题挂上“八卦”两字, 因为八卦意味着自由、不拘束、可以天马行空,细节处理上也难免有不严谨的地方;
当然我也希望八卦是相对容易理解的,即便他是关于数学的八卦。对于本文中的任何评论,
欢迎发信到我的新浪微博帐号 rickjin, 或者是邮箱 zhihuijin@gmail.com。
文本建模
我们日常生活中总是产生大量的文本,如果每一个文本存储为一篇文档,那
每篇文档从人的观察来说就是有序的词的序列 \(d=(w_1, w_2, \cdots, w_n)\)。
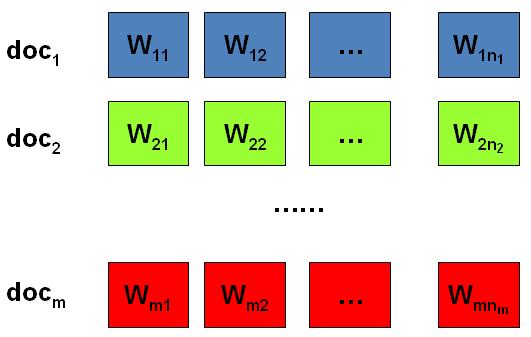
统计文本建模的目的就是追问这些观察到语料库中的的词序列是如何生成的。
统计学被人们描述为猜测上帝的游戏,人类产生的所有的语料文本我们都可以看成是一个伟大的上帝在
天堂中抛掷骰子生成的,我们观察到的只是上帝玩这个游戏的结果 ------ 词序列构成的语料,
而上帝玩这个游戏的过程对我们是个黑盒子。所以在统计文本建模中,我们希望猜测出上帝是如何玩这个游戏的,
具体一点,最核心的两个问题是
- 上帝都有什么样的骰子;
- 上帝是如何抛掷这些骰子的;
第一个问题就是表示模型中都有哪些参数,骰子的每一个面的概率都对应于模型中的参数;
第二个问题就表示游戏规则是什么,上帝可能有各种不同类型的骰子,
上帝可以按照一定的规则抛掷这些骰子从而产生词序列。


Unigram Model
假设我们的词典中一共有 \(V\) 个词 \(v_1, v_2, \cdots v_V\),那么最简单的 Unigram Model 就是认为上帝是按照如下的游戏规则产生文本的。
算法:Unigram Model
- 上帝只有一个骰子,这个骰子有 \(V\) 个面, 每个面对应一个词, 各个面的概率不一;
- 每抛一次骰子,抛出的面就对应的产生一个词;
如果一篇文档中有 \(n\) 个词,上帝就是独立的抛\(n\)次骰子产生这\(n\) 个词;
上帝的这个唯一的骰子各个面的概率记为 \(\vec{p} = (p_1, p_2, \cdots, p_V)\),所以每次投掷骰子类似于一个抛钢镚时候的贝努利实验,只是贝努利实验中我们抛的是一个两面的骰子,而此处抛的是一个\(V\)面的骰子,我们把抛这个\(V\)面骰子的实验记为记为 $w\sim Mult(w|\vec{p}) $。
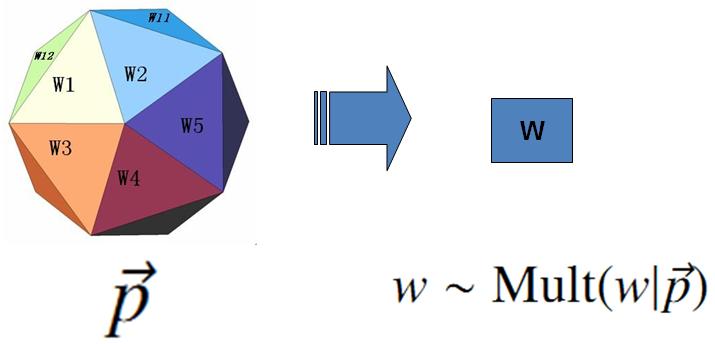
对于一篇文档\(d=\vec{w}=(w_1, w_2, \cdots, w_n)\), 该文档被生成的概率就是
\[ p(\vec{w}) = p(w_1, w_2, \cdots, w_n) = p(w_1)p(w_2) \cdots p(w_n) \]
而文档和文档之间我们认为是独立的, 所以如果语料中有多篇文档\(\mathcal{W}=(\vec{w_1}, \vec{w_2},...,\vec{w_m})\),则该语料的概率是
\[p(\mathcal{W})= p(\vec{w_1})p(\vec{w_2})\cdots p(\vec{w_m}) \]
在 Unigram Model 中, 我们假设了文档之间是独立可交换的,而文档中的词也是独立可交换的,所以一篇文档相当于一个袋子,里面装了一些词,而词的顺序信息就无关紧要了,这样的模型也称为词袋模型(Bag-of-words)。
假设语料中总的词频是\(N\), 在所有的 \(N\) 个词中,如果我们关注每个词 \(v_i\) 的发生次数 \(n_i\),那么 \(\vec{n}=(n_1, n_2,\cdots, n_V)\) 正好是一个多项分布
\[ p(\vec{n}) = Mult(\vec{n}|\vec{p}, N)= \binom{N}{\vec{n}} \prod_{k=1}^V p_k^{n_k} \]
此时, 语料的概率是
\[\begin{align*} p(\mathcal{W})&= &p(\vec{w_1})p(\vec{w_2}) \cdots p(\vec{w_m})\\ &=&\prod_{k=1}^V p_k^{n_k} \end{align*} \]
当然,我们很重要的一个任务就是估计模型中的参数\(\vec{p}\),也就是问上帝拥有的这个骰子的各个面的概率是多大,按照统计学家中频率派的观点,使用最大似然估计最大化\(P(\mathcal{W})\),于是参数\(p_i\)的估计值就是
\[ \hat{p_i} = \frac{n_i}{N} .\]
对于以上模型,贝叶斯统计学派的统计学家会有不同意见,他们会很挑剔的批评只假设上帝拥有唯一一个固定的骰子是不合理的。在贝叶斯学派看来,一切参数都是随机变量,以上模型中的骰子 \(\vec{p}\)不是唯一固定的,它也是一个随机变量。所以按照贝叶斯学派的观点,上帝是按照以下的过程在玩游戏的
贝叶斯 Unigram Model假设
- 帝有一个装有无穷多个骰子的坛子,里面有各式各样的骰子,每个骰子有 \(V\) 个面;
上帝从坛子里面抽了一个骰子出来,然后用这个骰子不断的抛,然后产生了语料中的所有的词;
上帝的这个坛子里面,骰子可以是无穷多个,有些类型的骰子数量多,有些类型的骰子少,所以从概率分布的角度看,坛子里面的骰子\(\vec{p}\) 服从一个概率分布 \(p(\vec{p})\),这个分布称为参数\(\vec{p}\) 的先验分布。
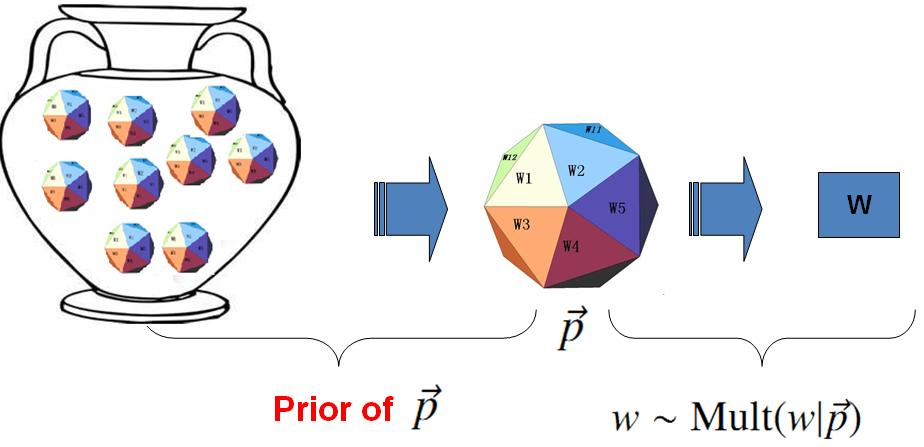
以上贝叶斯学派的游戏规则的假设之下,语料\(\mathcal{W}\)产生的概率如何计算呢?
由于我们并不知道上帝到底用了哪个骰子\(\vec{p}\),所以每个骰子都是可能被使用的,只是使用的概率由先验分布\(p(\vec{p})\)来决定。
对每一个具体的骰子\(\vec{p}\),由该骰子产生数据的概率是 \(p(\mathcal{W}|\vec{p})\),所以最终数据产生的概率就是对每一个骰子\(\vec{p}\)上产生的数据概率进行积分累加求和
\[ p(\mathcal{W}) = \int p(\mathcal{W}|\vec{p}) p(\vec{p})d\vec{p} \]
在贝叶斯分析的框架下,此处先验分布\(p(\vec{p})\) 就可以有很多种选择了,注意到
\[ p(\vec{n}) = Mult(\vec{n}|\vec{p}, N) \]
实际上是在计算一个多项分布的概率,所以对先验分布的一个比较好的选择就是多项分布对应的共轭分布,即 Dirichlet 分布
\[ Dir(\vec{p}|\vec{\alpha})=\frac{1}{\Delta(\vec{\alpha})} \prod_{k=1}^V p_k^{\alpha_k -1},\quad \vec{\alpha}=(\alpha_1, \cdots, \alpha_V) \]
此处,\(\Delta(\vec{\alpha})\)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6552
6552











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









