






前天帮同学写作业,顺便简单了解了下XML的一些东西,用的是C#做XML的处理。当然,学的时候只是为了满足使用,不免有些偏颇,不够全面,权当是在这里做个笔记吧。
帮朋友做的东西主要是完成这样的功能:从指定的目录中选定XML文档,然后把其中的树形结构提取出来,把每条边的信息存在指定的表中。每个XML被转换为一张表。前面的都是些准备工作,后面是在转换好的表上,做不同表之间的相似度分析。PS:朋友做数据挖掘的,刚入门……
分几个模块来说吧:
一、XML文档的导入
XML的导入分两种DOM和SAX。前者是直接在内存里把XML文档中的树搬过来,后者则是动态处理。由于处理的文档不是很大,直接使用了DOM来做。

 XMLEdge
XMLEdge
class
XMLEdge
{
public XmlNode Father;
public XmlNode Child;
public XMLEdge(XmlNode Father, XmlNode Child)
{
this .Father = Father;
this .Child = Child;
}
public XMLEdge()
{
this .Father = null ;
this .Child = null ;
}
public string GetEdge()
{
string InFo = "" ;
return InFo + " < " + Father.Name + " ---> " + Child.Name + " >\r\n " ;
}
public void SetFather(XmlNode f)
{
this .Father = f;
}
public void SetChild(XmlNode c)
{
this .Child = c;
}
{
public XmlNode Father;
public XmlNode Child;
public XMLEdge(XmlNode Father, XmlNode Child)
{
this .Father = Father;
this .Child = Child;
}
public XMLEdge()
{
this .Father = null ;
this .Child = null ;
}
public string GetEdge()
{
string InFo = "" ;
return InFo + " < " + Father.Name + " ---> " + Child.Name + " >\r\n " ;
}
public void SetFather(XmlNode f)
{
this .Father = f;
}
public void SetChild(XmlNode c)
{
this .Child = c;
}
XML文档提取
1
class
XMLObject
2 {
3 XmlDocument xDoc = null ; // the source file;
4
5 List < XMLEdge > XMLEdgeSet = new List < XMLEdge > (); // the target list;
6
7
8 public void GetSourceXMLDocument( string filename)
9 {
10 xDoc = new XmlDocument();
11 xDoc.Load(filename);
12 }
13
14 public void Transform(XmlNode xNode)
15 {
16 if (xNode.HasChildNodes)
17 {
18 foreach (XmlNode _xNode in xNode.ChildNodes)
19 {
20 if ( _xNode.NodeType == XmlNodeType.Element)
21 {
22 XMLEdgeSet.Add( new XMLEdge(xNode, _xNode));
23 Transform(_xNode);
24 }
25 }
26 }
27 }
28
29 public void GetTargetList()
30 {
31 foreach (XmlNode xNode in xDoc.ChildNodes)
32 {
33 Transfer(xNode);
34 }
35 }
36
37 public void DisplayEdges()
38 {
39 foreach (XMLEdge e in XMLEdgeSet)
40 {
41 e.GetEdge();
42 }
43 }
44
45
46 public string GetAllInfo()
47 {
48 string AllInfo = "" ;
49 foreach (XMLEdge xe in XMLEdgeSet)
50 {
51 AllInfo += xe.GetEdge();
52 }
53 return AllInfo;
54 }
55
56 public List < XMLEdge > GetEdgeList()
57 {
58 return XMLEdgeSet;
59 }
60 }
2 {
3 XmlDocument xDoc = null ; // the source file;
4
5 List < XMLEdge > XMLEdgeSet = new List < XMLEdge > (); // the target list;
6
7
8 public void GetSourceXMLDocument( string filename)
9 {
10 xDoc = new XmlDocument();
11 xDoc.Load(filename);
12 }
13
14 public void Transform(XmlNode xNode)
15 {
16 if (xNode.HasChildNodes)
17 {
18 foreach (XmlNode _xNode in xNode.ChildNodes)
19 {
20 if ( _xNode.NodeType == XmlNodeType.Element)
21 {
22 XMLEdgeSet.Add( new XMLEdge(xNode, _xNode));
23 Transform(_xNode);
24 }
25 }
26 }
27 }
28
29 public void GetTargetList()
30 {
31 foreach (XmlNode xNode in xDoc.ChildNodes)
32 {
33 Transfer(xNode);
34 }
35 }
36
37 public void DisplayEdges()
38 {
39 foreach (XMLEdge e in XMLEdgeSet)
40 {
41 e.GetEdge();
42 }
43 }
44
45
46 public string GetAllInfo()
47 {
48 string AllInfo = "" ;
49 foreach (XMLEdge xe in XMLEdgeSet)
50 {
51 AllInfo += xe.GetEdge();
52 }
53 return AllInfo;
54 }
55
56 public List < XMLEdge > GetEdgeList()
57 {
58 return XMLEdgeSet;
59 }
60 }
XMLEdge是XML中树上的一条边,标记了父节点和子节点。
使用XMLObject类,里面包装一个XML文档对象,以及一个保存XML文档中的边的List<XMLEdge>。最后,XML文档对象的所有边会存在List<XMLEdge>中。
核心的是Transform方法,利用C#中的类库,递归地把所有的边记录下来。
二、提取信息的处理
简单的相似度分析,用一个二维数组来记录每个各个文档之间的相似度。建立一个公共的XMLEdge的表EdgeInfo,对于一个XMLObject新转化成的表,和EdgeInfo一起扫描,如果包含EdgeInfo中没有的XMLEdge,将该条边添加到EdgeInfo中,并将二维数组中的对应位置置1,如果该条边已经在EdgeInfo中,则在对应的二维数组的位置加一。最后将二维数据记录的结果输出。
ScanEdge
class
ScanEdges
{
public XMLObjectSet Xos = new XMLObjectSet();
// static DoubleArray[] XmlDocInfo = new DoubleArray[100];
static int [,] XmlDocInfo = new int [ 100 , 100000 ];
static XMLEdge[] EdgeInfo = new XMLEdge[ 1000000 ];
static int DocNum;
static int Num = 0 ;
public void SetXmlObjectSet(XMLObjectSet _xos)
{
this .Xos = _xos;
}
public void initArray()
{
for ( int i = 0 ; i < 100 ; i ++ )
{
for ( int c = 0 ; c < 10000 ; c ++ )
XmlDocInfo[i,c] = 0 ;
}
for ( int i = 0 ; i < 100 ; i ++ )
{
EdgeInfo[i] = new XMLEdge();
}
}
public void scan()
{
int j = 0 ;
foreach (XMLObject xmldoc in Xos.GetObjectList())
{
foreach (XMLEdge edge in xmldoc.GetEdgeList())
{
bool jump = false ;
for ( int i = 0 ; i < Num; i ++ )
{
if (edge.Father.Name == EdgeInfo[i].Father.Name && edge.Child.Name == EdgeInfo[i].Child.Name)
{
XmlDocInfo[j,i] += 1 ;
jump = true ;
}
}
if (jump == false )
{
EdgeInfo[Num].SetFather(edge.Father) ;
EdgeInfo[Num].SetChild(edge.Child) ;
XmlDocInfo[j,Num] += 1 ;
Num ++ ;
}
}
j ++ ;
}
DocNum = j;
}
public string display()
{
string result = "" ;
for ( int k = 0 ;k < DocNum;k ++ )
{
for ( int m = 0 ; m < Num; m ++ )
{
int temp = XmlDocInfo[k,m];
result += temp.ToString();
}
result += " \r\n " ;
}
return result;
}
public void Clear ()
{
Xos.Refresh();
initArray();
}
}
{
public XMLObjectSet Xos = new XMLObjectSet();
// static DoubleArray[] XmlDocInfo = new DoubleArray[100];
static int [,] XmlDocInfo = new int [ 100 , 100000 ];
static XMLEdge[] EdgeInfo = new XMLEdge[ 1000000 ];
static int DocNum;
static int Num = 0 ;
public void SetXmlObjectSet(XMLObjectSet _xos)
{
this .Xos = _xos;
}
public void initArray()
{
for ( int i = 0 ; i < 100 ; i ++ )
{
for ( int c = 0 ; c < 10000 ; c ++ )
XmlDocInfo[i,c] = 0 ;
}
for ( int i = 0 ; i < 100 ; i ++ )
{
EdgeInfo[i] = new XMLEdge();
}
}
public void scan()
{
int j = 0 ;
foreach (XMLObject xmldoc in Xos.GetObjectList())
{
foreach (XMLEdge edge in xmldoc.GetEdgeList())
{
bool jump = false ;
for ( int i = 0 ; i < Num; i ++ )
{
if (edge.Father.Name == EdgeInfo[i].Father.Name && edge.Child.Name == EdgeInfo[i].Child.Name)
{
XmlDocInfo[j,i] += 1 ;
jump = true ;
}
}
if (jump == false )
{
EdgeInfo[Num].SetFather(edge.Father) ;
EdgeInfo[Num].SetChild(edge.Child) ;
XmlDocInfo[j,Num] += 1 ;
Num ++ ;
}
}
j ++ ;
}
DocNum = j;
}
public string display()
{
string result = "" ;
for ( int k = 0 ;k < DocNum;k ++ )
{
for ( int m = 0 ; m < Num; m ++ )
{
int temp = XmlDocInfo[k,m];
result += temp.ToString();
}
result += " \r\n " ;
}
return result;
}
public void Clear ()
{
Xos.Refresh();
initArray();
}
}
最后贴个简单的例子吧
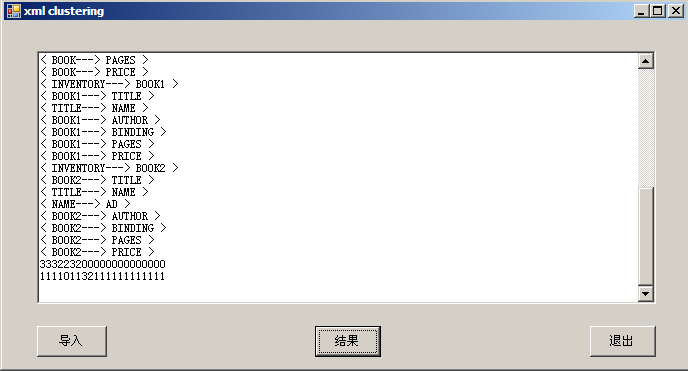
the end :)















 350
350











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









