






--题外话:最近发现了一些问题,一些高搜索量的东西相当一部分没有价值。发现大部分是一些问题的错误日志。而我是个比较爱贴图的。搜索引擎的检索会将我们的博文文本分词。所以图片内容一般是检索不到的,也就是说同样的问题最好是帖错误代码,日志,虽然图片很直观,但是并不利与传播。希望大家能够优化一部分博文的内容,这样有价值的东西传播量可能会更高。
本文主要是记录Elasticsearch5.3.1 IK分词,同义词/联想搜索设置,本来是要写fscrawler的多种格式(html,pdf,word...)数据导入的,但是IK分词和同义词配置还是折腾了两天,没有很详细的内容,这里决定还是记录下来。IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了3个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IK Analyzer 3.0则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。所以IK跟ES本来是天生一对,当然是对于中文来说,起码对于英文分词来说,空格分词就足够简单粗暴。中文检索为了达到更好的检索效果分词效果还是很重要的,所以IK分词插件有必要一试。
一、IK分词的安装:
1、下载IK分词器:https://github.com/medcl/elasticsearch-analysis-ik/releases 我这里下载的是5.3.2的已经编译的版本,因为这里没有5.3.1的版本。
2、在Elasticsearch的plugins目录下新建目录analysis-ik: mkdir analysis-ik
3、将IK分词器的压缩包解压到analysis-ik目录下:
- [rzxes@rzxes analysis-ik]$ unzip elasticsearch-analysis-ik-5.3.2.zip 查看目录结构如下:

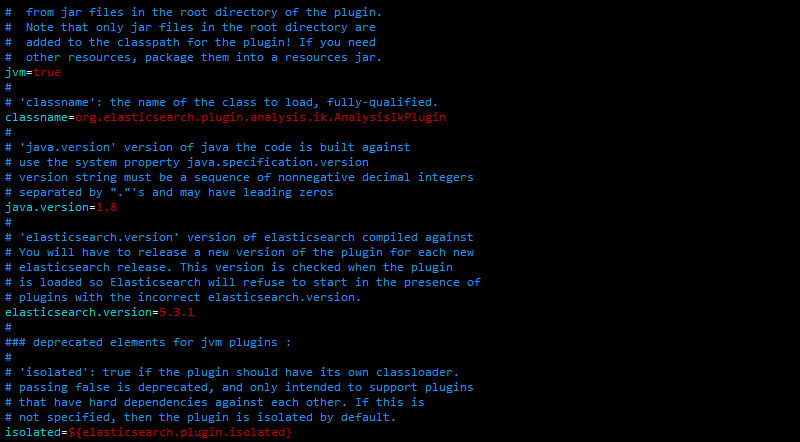
4、编辑plugin-sescriptor.properties:
- 修改一些配置,主要是修改elasticsearch.version,因为下载的是5.3.2的而我本身是5.3.1的elasticsearch所以这里修改对应即可。
5、启动Elasticsearch测试IK分词:[rzxes@rzxes elasticsearch-5.3.1]$ bin/elasticsearch
- 如下图可以看到loaded plugin [analysis-ik],说明已经加载了插件

- IK分词支持两种分析器Analyzer:
ik_smart,ik_max_word, 两种分词器Tokenizer:ik_smart,ik_max_word,ik_max_word: 会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”,会穷尽各种可能的组合;
ik_smart: 会做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
- 试验一下能否进行分词:调用Elasticsearch的分词器API
- standard分词器【analyzer=standard】http://192.168.230.150:9200/_analyze?analyzer=standard&pretty=true&text=hello word西红柿 结果如下:
-
{ "tokens" : [ { "token" : "hello", "start_offset" : 0, "end_offset" : 5, "type" : "<ALPHANUM>", "position" : 0 }, { "token" : "word", "start_offset" : 6, "end_offset" : 10, "type" : "<ALPHANUM>", "position" : 1 }, { "token" : "西", "start_offset" : 10, "end_offset" : 11, "type" : "<IDEOGRAPHIC>", "position" : 2 }, { "token" : "红", "start_offset" : 11, "end_offset" : 12, "type" : "<IDEOGRAPHIC>", "position" : 3 }, { "token" : "柿", "start_offset" : 12, "end_offset" : 13, "type" : "<IDEOGRAPHIC>", "position" : 4 } ] }
- 采用IK分词器【analyzer=ik_smart】http://192.168.230.150:9200/_analyze?analyzer=ik_smart&pretty=true&text=hello word西红柿 结果如下:
-
{ "tokens" : [ { "token" : "hello", "start_offset" : 0, "end_offset" : 5, "type" : "ENGLISH", "position" : 0 }, { "token" : "word", "start_offset" : 6, "end_offset" : 10, "type" : "ENGLISH", "position" : 1 }, { "token" : "西红柿", "start_offset" : 10, "end_offset" : 13, "type" : "CN_WORD", "position" : 2 }, { "token" : "9f", "start_offset" : 13, "end_offset" : 15, "type" : "LETTER", "position" : 3 } ] } - 采用IK分词器【analyzer=ik_max_word】http://192.168.230.150:9200/_analyze?analyzer=ik_max_word&pretty=true&text=hello word中华人民
-
{ "tokens" : [ { "token" : "hello", "start_offset" : 0, "end_offset" : 5, "type" : "ENGLISH", "position" : 0 }, { "token" : "word", "start_offset" : 6, "end_offset" : 10, "type" : "ENGLISH", "position" : 1 }, { "token" : "中华人民", "start_offset" : 10, "end_offset" : 14, "type" : "CN_WORD", "position" : 2 }, { "token" : "中华", "start_offset" : 10, "end_offset" : 12, "type" : "CN_WORD", "position" : 3 }, { "token" : "华人", "start_offset" : 11, "end_offset" : 13, "type" : "CN_WORD", "position" : 4 }, { "token" : "人民", "start_offset" : 12, "end_offset" : 14, "type" : "CN_WORD", "position" : 5 } ] }
- 致此IK分词就安装成功了,非常简单只需要下载编译包解压就可以了,至于修改配置是对于版本不对应的情况。
二、配置同义词对应:
- 配置同义词是为了能够检索一个词的时候相关词也能够检索到。关联词和同义词可以合二为一配置在这个文件里。
- 新建同义词文件:在Elasticsearch的confg目录下新建文件夹analysis并在其下创建文件synonyms.txt,这一步可以直接在conf目录下创建synonyms.txt并不影响,只需要在后面建立缩印的时候指定路径就行。 mkdir analysis vim synonyms.txt

- 向文件synonyms.txt添加如下内容: 注意‘"逗号"一定是英文的
-
西红柿,番茄 =>西红柿,番茄 社保,公积金 =>社保,公积金 - 启动Elasticsearch,此时同义词就会被加载进来。
三、测试同义词是否生效:
- 创建index:自定义分词器和过滤器并引用IK分词器。
-
curl -XPUT 'http://192.168.230.150:9200/index' -d' { "index": { "analysis": { "analyzer": { "by_smart": { "type": "custom", "tokenizer": "ik_smart", "filter": ["by_tfr","by_sfr"], "char_filter": ["by_cfr"] }, "by_max_word": { "type": "custom", "tokenizer": "ik_max_word", "filter": ["by_tfr","by_sfr"], "char_filter": ["by_cfr"] } }, "filter": { "by_tfr": { "type": "stop", "stopwords": [" "] }, "by_sfr": { "type": "synonym", "synonyms_path": "analysis/synonyms.txt" } }, "char_filter": { "by_cfr": { "type": "mapping", "mappings": ["| => |"] } } } } }' - 创建mapping:定义一个字段title,并且设置分词器analyzer和查询分词器search_analyzer.
-
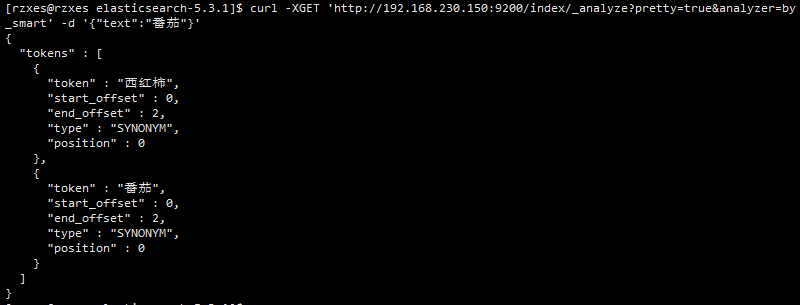
curl -XPUT 'http://192.168.230.150:9200/index/_mapping/typename' -d' { "properties": { "title": { "type": "text", "index": "analyzed", "analyzer": "by_max_word", "search_analyzer": "by_smart" } } }' - 使用自定义分词器分词: curl -XGET 'http://192.168.230.150:9200/index/_analyze?pretty=true&analyzer=by_smart' -d '{"text":"番茄"}' 结果如下:分词西红柿会通过同义词创建相关索引。
- 添加数据:
-
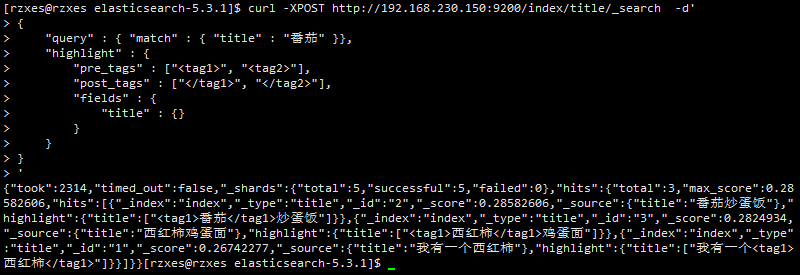
curl -XPOST http://192.168.230.150:9200/index/title/1 -d'{"title":"我有一个西红柿"}' curl -XPOST http://192.168.230.150:9200/index/title/2 -d'{"title":"番茄炒蛋饭"}' curl -XPOST http://192.168.230.150:9200/index/title/3 -d'{"title":"西红柿鸡蛋面"}' - 检索数据:我们从index索引中检索关键字"番茄"并用标签标记命中的关键字。
-
curl -XPOST http://192.168.230.150:9200/index/title/_search -d' { "query" : { "match" : { "title" : "番茄" }}, "highlight" : { "pre_tags" : ["<tag1>", "<tag2>"], "post_tags" : ["</tag1>", "</tag2>"], "fields" : { "title" : {} } } } '
结果如下:命中了三条数据,命中了"番茄"和他的同义词"西红柿".
- 致此,IK分词以及同义词的配置就完成了,。
三、存在的故障和问题:
- 非常感谢写这边http://blog.csdn.net/u012859681/article/details/60147864文章的博友,我写的很大一部分是参考他的,但是其中有些问题试验不通过。可能是自身配的问题,大家可以多方参考。
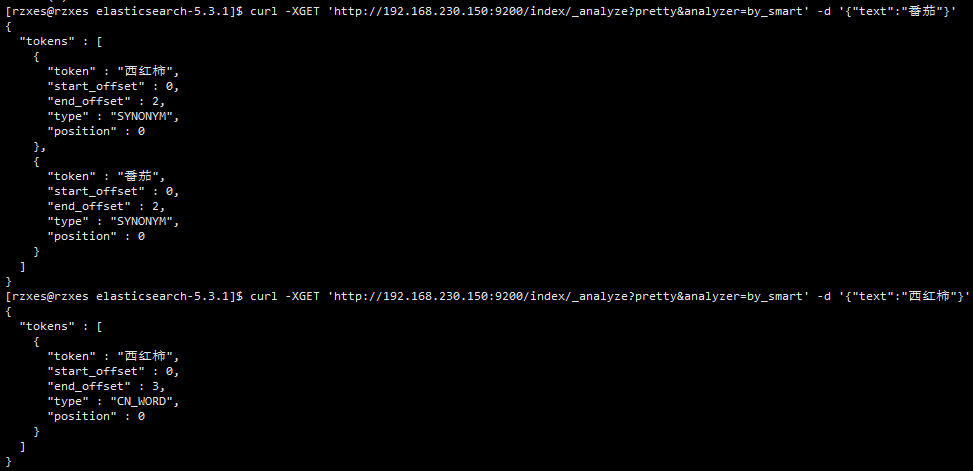
- 故障1:讲道理如下两个结果应该是一样的,但是这里却是如下,可能是哪里有问题。。。【此故障已解决,机子脑抽了,睡一觉起来自己就好了】
- 问题2:有没有可以直接配置的,按这样来的话见建一次索引就要设置一次分词器,有没有直接修改默认配置的方法。????
- 以前好像是配置文件加下面两行:
index.analysis.analyzer.default.type" : "ik",
index.analysis.analyzer.default.use_smart" : "true"
但是爆了错:
5.x版本以后就不支持这种设置方式,因为考虑到后面的一些更新。Since elasticsearch 5.x index level settings can NOT be set on the nodes configuration like the elasticsearch.yaml, in system properties or command line arguments.In order to upgrade all indices the settings must be updated via the /${index}/_settings API. Unless all settings are dynamic all indices must be closed in order to apply the upgradeIndices created in the future should use index templates to set default values.
In order to upgrade all indices the settings must be updated via the /${index}/_settings API
没理解错的话说了半天还是要跟Index绑定。 - ES中文社区爆6.0可能会移除type,
- 以前好像是配置文件加下面两行:
- 问题3:synonyms.txt这个同义词配置文件中的格式有哪几种,分别表示什么??如故障1中的文章内提到的两种格式,一种有"=>",另一无"=>",但是第二种我试验有问题。【此问题已解决,两种配置都可用】如下所示:添加一行如下:儿童,青年,少年,幼年。不过这两种建立索引的方式有什么区别还没有弄明白。
-
儿童,青年,少年,幼年 西红柿,番茄 => 西红柿,番茄 社保,公积金 => 社保,公积金 -
重启ES再进行分词:curl -XGET 'http://192.168.230.150:9200/index/_analyze?pretty=true&analyzer=by_smart' -d '{"text":"青年"}' 结果如下:
-
[rzxes@rzxes elasticsearch-5.3.1]$ curl -XGET 'http://192.168.230.150:9200/index/_analyze?pretty=true&analyzer=by_smart' -d '{"text":"青年"}' { "tokens" : [ { "token" : "青年", "start_offset" : 0, "end_offset" : 2, "type" : "CN_WORD", "position" : 0 }, { "token" : "儿童", "start_offset" : 0, "end_offset" : 2, "type" : "SYNONYM", "position" : 0 }, { "token" : "少年", "start_offset" : 0, "end_offset" : 2, "type" : "SYNONYM", "position" : 0 }, { "token" : "幼年", "start_offset" : 0, "end_offset" : 2, "type" : "SYNONYM", "position" : 0 } ] }
四、联想检索:(这种检索名称纯属个人杜撰)
- 目标:搜索 "笔记本",出现"联想","戴尔","电脑"。。等等相关连的词。类似ML的相似度高的词。。或者推荐系统。
- 在这里只需要类比同义词,配置synonyms.txt。将检索词与关联词做对应就可以了。














 2410
2410











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









