






前言
很早便规划的浅谈分词算法,总共分为了五个部分,想聊聊自己在各种场景中使用到的分词方法做个总结,种种事情一直拖到现在,今天抽空赶紧将最后一篇补上。前面几篇博文中我们已经阐述了不论分词、词性标注亦或NER,都可以抽象成一种序列标注模型,seq2seq,就是将一个序列映射到另一个序列,这在NLP领域是非常常见的,因为NLP中语序、上下文是非常重要的,那么判断当前字或词是什么,我们必须回头看看之前说了什么,甚至之后说了什么,这也符合人类在阅读理解时的习惯。由于抽象成了Seq2Seq的模型,那么我们便可以套用相关模型来求解,比如HMM、CRF以及深度中的RNN,本文我们就来聊聊LSTM在分词中的应用,以及使用中的一些trick,比如如何添加字典等。
目录
浅谈分词算法(1)分词中的基本问题
浅谈分词算法(2)基于词典的分词方法
浅谈分词算法(3)基于字的分词方法(HMM)
浅谈分词算法(4)基于字的分词方法(CRF)
浅谈分词算法(5)基于字的分词方法(LSTM)
循环神经网络
在之前的博文马里奥AI实现方式探索 ——神经网络+增强学习,我阐述了关于神经网络的历程,以及最近这波人工智能浪潮的起始CNN,即卷积神经网络的概念。卷积神经网络给图像领域带来了质的飞越,也将之前由李飞飞教授建立的ImageNet比赛提升到了新的高度,图像识别领域,计算机第一次超越了人类,从而引爆了最近两三年来对人工智能、深度学习的持续关注。
当CNN在图像领域火爆之后,自然作为人工智能三大领域之一的NLP,也很快拿来使用,即著名的Text-CNN,大家感兴趣的可以去看看这篇论文Convolutional Neural Networks for Sentence Classification,对NLP领域也具有重要的里程碑意义,现在引用量也达到了3436。
但是CNN有个比较严重的问题是,其没有序列的概念在里面,如果我们将一个句子做好embedding丢到CNN中做分类模型,那么CNN更多的是将这个句子看做一个词袋(bag-of-words bag),这样在NLP领域重要的语序信息就丢失了,那么我们便引出了RNN,即循环神经网络或说递归神经网络(这里值得注意的是,如果是对语句做分类模型,那么用CNN进行不同kernel的卷积,然后拼接是可以提取到一些语序信息,这其中也涉及到各种变种的CNN,大家可以多查查资料)。
对于循环神经网络,其实与CRF、HMM有很多共通之处,对于每一个输入\(x_t\),我们通过网络变换都会得到一个状态\(h_t\),对于一个序列来说,每一个token(可以是字也可以是词,在分词时是字)都会进入网络迭代,注意网络中的参数是共享的。这里不可免俗的放上经典图像吧: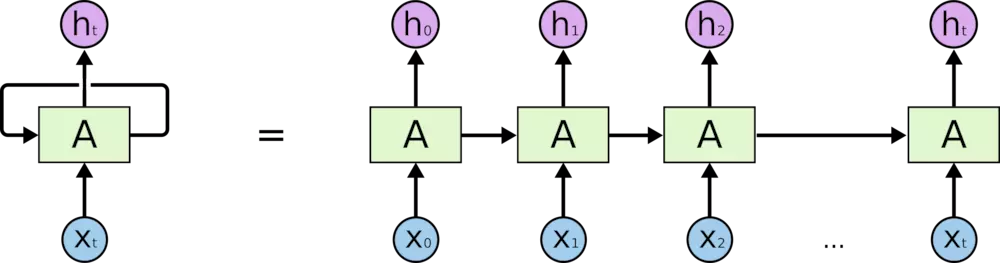
这里将循环神经网络展开,就是后面那样。大家注意下图中的\(A\),在RNN中就是一个比较简单的前馈神经网络,在RNN中会有一个严重的问题,就是当序列很长的时候,BP算法在反馈时,梯度会趋于零,即所谓的梯度消失(vanishing gradient)问题,这便引出了LSTM(Long Short Term Memory)。
LSTM本质上还是循环神经网络,只不过呢它把上面我们提到的\(A\)换了换,加了三个门,其实就是关于向量的几个变换表达式,来规避这种梯度消失问题,使得LSTM的逻辑单元能够更好的保存序列信息,同样不可免俗上下面这张经典的图片: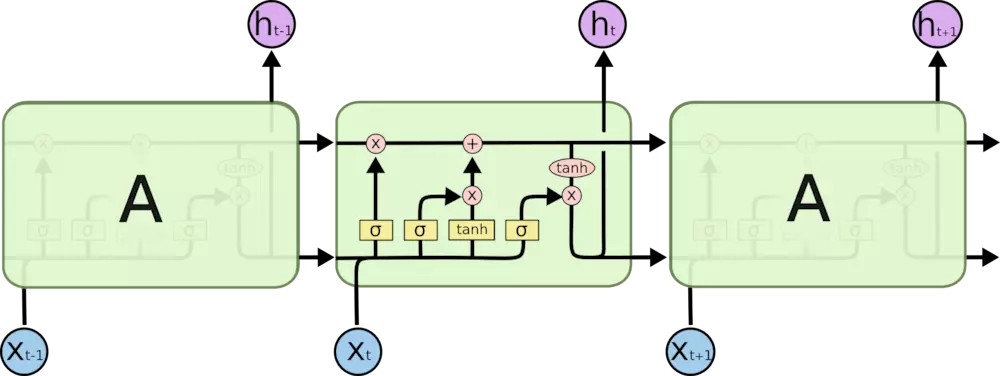
图中对应了四个表达式如下:
遗忘门:
\[f_t=\sigma (W_f\cdot [h_{t-1},x_t]+b_f\]
输入门:
\[i_t=\sigma (W_i\cdot [h_{t-1},x_t]+b_i\]
\[\widetilde{C}=tanh(W_C\cdot [h_{t-1},x_t]+b_C\]
状态更新:
\[C_t=f_t*C_{t-1}+i_t*\widetilde{C}_t\]
输出门:
\[O_t=\sigma (W_o[h_{t-1},x_t]+b_o)\]
\[h_t=O_t*tanh(C_t)\]
一般呢LSTM都是一个方向将序列循环输入到网络之中,然而有时候我们需要两头关注序列的信息,这样便引出了Bi-LSTM,即双向LSTM,很简单,就是对于一个序列,我们有两个LSTM网络,一个正向输入序列,一个反向输入序列,然后将输出的state拼接在一起,供后续使用。
到这里我们简单的说了下关于循环神经网络的事情,下面我们看下在分词中应用LSTM
基于LSTM的分词
前文以及之前的系列博文,我们已经熟悉分词转换为Seq2Seq的思路,那么对于LSTM,我们需要做的是将一串句子映射成为Embedding,然后逐个输出到网络中,得到状态输出,进行序列标注。我们采用TensorFlow来开发。
Embedding
关于Embedding,我们可以直接下载网上公开的Wiki数据集训练好的Embedding,一般维度是100,也可以自己根据场景,利用Word2Vec、Fasttext等训练自己的Embedding。
数据预处理
其实深度的好多模型已经很成熟,最麻烦的是数据的预处理,在数据预处理阶段核心要做的是将序列映射到Embedding文件对应的id序列,并且按照Batch来切分,一般根据数据集的大小会设置64、128、256等不同的batch大小,在向网络输入数据,进行epoch迭代时,注意进行必要的shuffle操作,对于结果提高很有用,shuffle类似如下:
def shuffle(char_data, tag_data, dict_data, len_data):
char_data = np.asarray(char_data)
tag_data = np.asarray(tag_data)
dict_data = np.asarray(dict_data)
len_data = np.asarray(len_data)
idx = np.arange(len(len_data))
np.random.shuffle(idx)
return (char_data[idx], tag_data[idx], dict_data[idx], len_data[idx])数据预处理我这里不多讲了,读者可以直接看github上开源的代码,有问题随时留言,我有空会来解答~
模型
我们的核心模型结构也很简单,将输入的id序列,通过Tensorflow 的查表操作,映射成对应的Embedding,然后输入到网络中,得到最终结果,进行Decode操作,得到每个字符的标记(BEMS),核心代码如下:
def __init__(self, config, init_embedding = None):
self.batch_size = batch_size = config.batch_size
self.embedding_size = config.embedding_size # column
self.hidden_size = config.hidden_size
self.vocab_size = config.vocab_size # row
# Define input and target tensors
self._input_data = tf.placeholder(tf.int32, [batch_size, None], name="input_data")
self._targets = tf.placeholder(tf.int32, [batch_size, None], name="targets_data")
self._dicts = tf.placeholder(tf.float32, [batch_size, None], name="dict_data")
self._seq_len = tf.placeholder(tf.int32, [batch_size], name="seq_len_data")
with tf.device("/cpu:0"):
if init_embedding is None:
self.embedding = tf.get_variable("embedding", [self.vocab_size, self.embedding_size], dtype=data_type())
else:
self.embedding = tf.Variable(init_embedding, name="embedding", dtype=data_type())
inputs = tf.nn.embedding_lookup(self.embedding, self._input_data)
inputs = tf.nn.dropout(inputs, config.keep_prob)
inputs = tf.reshape(inputs, [batch_size, -1, 9 * self.embedding_size])
d = tf.reshape(self._dicts, [batch_size, -1, 16])
self._loss, self._logits, self._trans = _bilstm_model(inputs, self._targets, d, self._seq_len, config)
# CRF decode
self._viterbi_sequence, _ = crf_model.crf_decode(self._logits, self._trans, self._seq_len)
with tf.variable_scope("train_ops") as scope:
# Gradients and SGD update operation for training the model.
self._lr = tf.Variable(0.0, trainable=False)
tvars = tf.trainable_variables() # all variables need to train
# use clip to avoid gradient explosion or gradients vanishing
grads, _ = tf.clip_by_global_norm(tf.gradients(self._loss, tvars), config.max_grad_norm)
self.optimizer = tf.train.AdamOptimizer(self._lr)
self._train_op = self.optimizer.apply_gradients(
zip(grads, tvars),
global_step=tf.contrib.framework.get_or_create_global_step())
self._new_lr = tf.placeholder(data_type(), shape=[], name="new_learning_rate")
self._lr_update = tf.assign(self._lr, self._new_lr)
self.saver = tf.train.Saver(tf.global_variables())代码逻辑很清晰,将各种输入得到后,embedding查表结束后,放入Bi-LSTM模型,得到的结果进行Decode,这里注意我们用了一个CRF进行尾部Decode,经过试验效果更好,其实直接上一层Softmax也ok。对于bilstm如下:
def _bilstm_model(inputs, targets, dicts, seq_len, config):
'''
@Use BasicLSTMCell, MultiRNNCell method to build LSTM model
@return logits, cost and others
'''
batch_size = config.batch_size
hidden_size = config.hidden_size
vocab_size = config.vocab_size
target_num = config.target_num # target output number
seq_len = tf.cast(seq_len, tf.int32)
fw_cell = lstm_cell(hidden_size)
bw_cell = lstm_cell(hidden_size)
with tf.variable_scope("seg_bilstm"): # like namespace
# we use only one layer
(forward_output, backward_output), _ = tf.nn.bidirectional_dynamic_rnn(
fw_cell,
bw_cell,
inputs,
dtype=tf.float32,
sequence_length=seq_len,
scope='layer_1'
)
# [batch_size, max_time, cell_fw.output_size]/[batch_size, max_time, cell_bw.output_size]
output = tf.concat(axis=2, values=[forward_output, backward_output]) # fw/bw dimension is 3
if config.stack: # False
(forward_output, backward_output), _ = tf.nn.bidirectional_dynamic_rnn(
fw_cell,
bw_cell,
output,
dtype=tf.float32,
sequence_length=seq_len,
scope='layer_2'
)
output = tf.concat(axis=2, values=[forward_output, backward_output])
output = tf.concat(values=[output, dicts], axis=2) # add dicts to the end
# outputs is a length T list of output vectors, which is [batch_size*maxlen, 2 * hidden_size]
output = tf.reshape(output, [-1, 2 * hidden_size + 16])
softmax_w = tf.get_variable("softmax_w", [hidden_size * 2 + 16, target_num], dtype=data_type())
softmax_b = tf.get_variable("softmax_b", [target_num], dtype=data_type())
logits = tf.matmul(output, softmax_w) + softmax_b
logits = tf.reshape(logits, [batch_size, -1, target_num])
with tf.variable_scope("loss") as scope:
# CRF log likelihood
log_likelihood, transition_params = tf.contrib.crf.crf_log_likelihood(
logits, targets, seq_len)
loss = tf.reduce_mean(-log_likelihood)
return loss, logits, transition_params注意这里做了两次LSTM,并将结果拼接在一起,而我们的损失函数是关于crf_log_likelihood。
如何添加用户词典
我们可以看到在整个模型训练好后,inference的过程是直接根据网络权重进行的,那么如何添加用户词典呢,这里我们采用的方式是将用户词典作为额外的特征拼接在Bi-LSTM结果的后面,就是在上面代码的output = tf.concat(values=[output, dicts], axis=2) # add dicts to the end这里,这个词典会分成四个部分,head、mid、single、tail,词头、词中、词尾以及单字词,这样对于用户词典是否出现用one-hot形式表达,不过实际使用过程中也还是存在切不出来的问题,读者可以考虑加强这部分特征。
整个代码我放在github上了,感兴趣的读者直接看源代码,有问题欢迎留言~
https://github.com/xlturing/machine-learning-journey/tree/master/seg_bilstm
终于写好这个系列了,之后谢谢最近在弄的Attention、Transformer以及BERT这一套在文本分类中的应用哈,欢迎大家交流。














 6714
6714











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









