






Summarize
Spark Streaming实现了对实时流数据的高吞吐量、地容错的数据处理API。它的数据来源有很多种:Kafka、Flume、Twitter、ZeroMQ、TCP Scoket等。架构图如下:

Streaming接收实时流输入的数据,将其按批划分,然后交给Spark Enigne分批处理。如下图所示:

StreamingContext
和SparkContext相似。要使用Spark的流处理就必须创建StreamingContext对象。
DStream
DStream是Spark Streaming的是一个抽象类,离散流。她表示一个连续的流。是Spark的一个不可变的分布式数据抽象。
DStream上都用的到任何操作都会转换成底层的RDDs操作。而这些底层RDDs转换是由Spark Engine计算的。
DStream Transformation
离散流转换。DStream支持多种变换的基本SparkRDD使用。下面表格会介绍DStream中的一个基本转换方法:
| Tramsformation | decs |
| map | 讲元DStream通过一个函数返回一个新的DStream |
| filter |
|
| glom |
|
| repartition | 通过创建分区的数量改变平行这个DStream的层次 |
| reduce | 使用函数计算,将原来DStream中的每个RDD进行元素聚合,返回一个新的DStream |
| count |
|
| foreach |
|
| transform | 通过源DStream的每个RDD应用RDD2RDD函数返回一个新的DStream |
| ...... |
|
UpdateStateByKey 有状态操作
UpdateStateByKey在有新的数据信息进入或更新时,可以让用户保持想要的任何状。使用这个功能需要完成两步:
1)定义状态:可以是任意数据类型
2)定义状态更新函数:用一个函数指定如何使用先前的状态,从输入流中的新值更新状态。
对于有状态操作,要不断的把当前和历史的时间切片的RDD累加计算,随着时间的流失,计算的数据规模会变得越来越大。
转换操作 无状态
对于无状态的操作,每一次操作都只是计算当前时间切片的内容,例如每次只计算1s的时间所产生的RDD数据
Window操作
Window操作是针对特定时间并以特定时间间隔为单位进行滑动的操作。比如在1s为时间切片的情况下,统计最近10min的SparkStreaming产生的数据。并且没2min更新一次。
NetworkWordCount
NetworkWordCount是一个单词统计的测试类位于:org.apache.spark.examples.streaming下。源码如下:
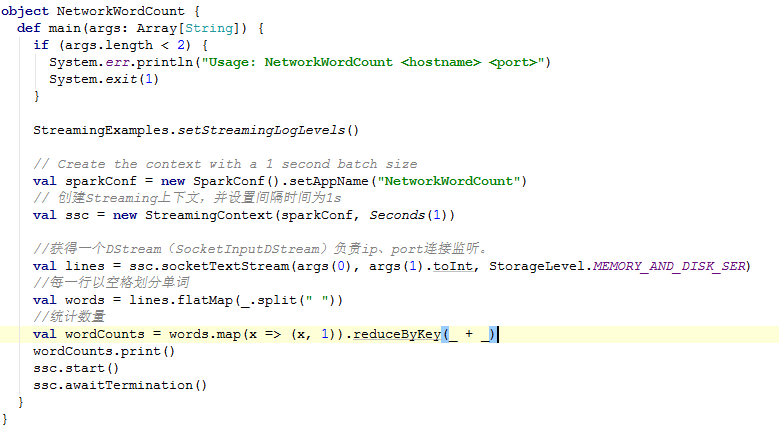
下面开始深入分析这段代码:
创建TCP Socket
在上述源码中ssc.socketTextStream(...)创建了TCP Scoket。里面有3个参数:
1)主机名
2)端口
3)stoageLevel,这是个存储对象,默认是放内存和磁盘并且是2份。这个可以自己设置。
继续跟踪socketTextStream中的socketStream方法,发现里面new了一个SocketInputDStream。
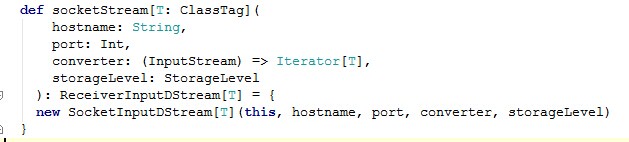
SocketInputDStream就是一个DStream了。从源码中可以看出:
SocketInputDStream extendsReceiverInputDStream。而ReceiverInputDStream又extends DStream。
Ok,继续说SocketInputDStream。SocketInputDStream重写了ReceiverInputDStream中的getReceiver方法:

这里是new了一个SocketReceiver。
SocketReceiver中的onStart调用了receive这个方法:

下面看receive的具体实现:
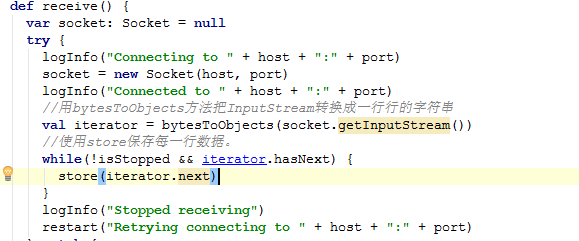
这里有个关键的方法store(iterator.next),OK,跟踪进去。

Executor是ReciverSupervisor类型。这个pushSingle就是push数据列表到backend数据存储中。
到了这里,回到NetworkWordCount最初的源码。

可以发现lines的类型就是SocketInputDStream,然后对他进行一些转换操作(flatMap、map)。这些转换操作都是SocketInputDStream特有的。
最后一步操作就是reduceByKey(_+ _)。这里的reduceByKey(_+ _)和RDD的一样都是调用了combineByKey方法。那不一样的地方就是它调用了ShuffledDStream。源码如下:
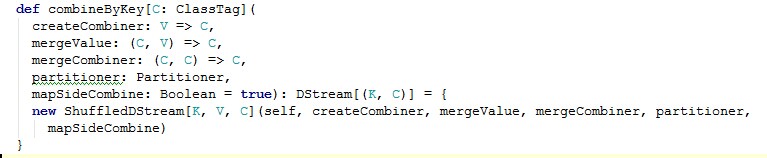
Ok,继续跟踪ShuffledDStream。ShuffledDStream继承了DStream并且实现了compute方法。

这个方法根据validTime获取RDD进行reduceByKey。再次回到NetworkWordCount。这里有个print方法:
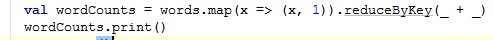
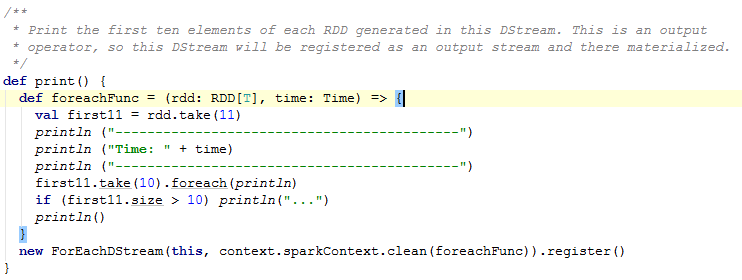
这也是一个转换。在这个DStream中产生的RDD遍历1到10个元素打印。这是一个输出操作,所以这个DStream将注册一个输出流并且物化。源码如下:
启动StreamingContext
再次回到NetworkWordCount。面前分源码分析,数据切割动作转换做看完了。现在开始启动StreamingContext。ssc.start()。跟踪源码如下:
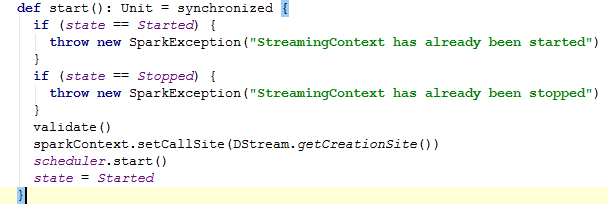
这里重点要看的是scheduler.start()这行。scheduler是JobScheduler实例化变量。继续进入start方法。
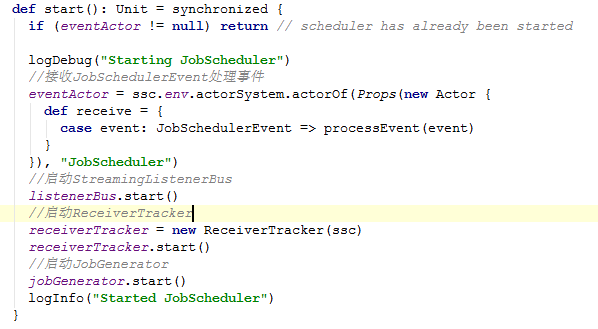
解下逐渐进入三个start方法
StreamingListenerBus这是个事件监听器,比较简单。
启动ReceiverTracker
ReceiverTracker的start源码如下:
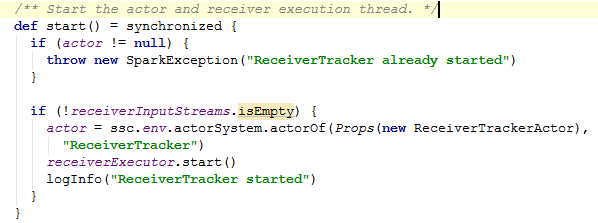
1)第一个if判断actor是否为空,为null则抛出异常。
2)第二的if,if(!receiverInputStreams.isEmpty).。这里要判断receiverInputStreams。receiverInputStreams是在SocketInputDStream的父类InputDStream当中,当实例化InputDStream的时候在DStreamGraph里面添加了InputStrem。

3)实例化actor。ReceiverTrackerActor,她负责注册Receiver、AddBlock、ReportError(报告错误)、注销Receiver四个事件
4)启动receiverExecutor。receiverExecutor.start()。这里的start调用的是ReceiverLauncher的start方法。而这个start方法运行源码如下:
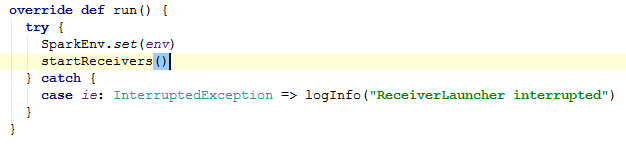
它调用的是startReceivers。到最后进入ssc.sparkContext.runJob(tempRDD,startReceiver)。然后开始DAG调度划分stage、任务调度等。具体源码如下,源码中也做了相应的注解:
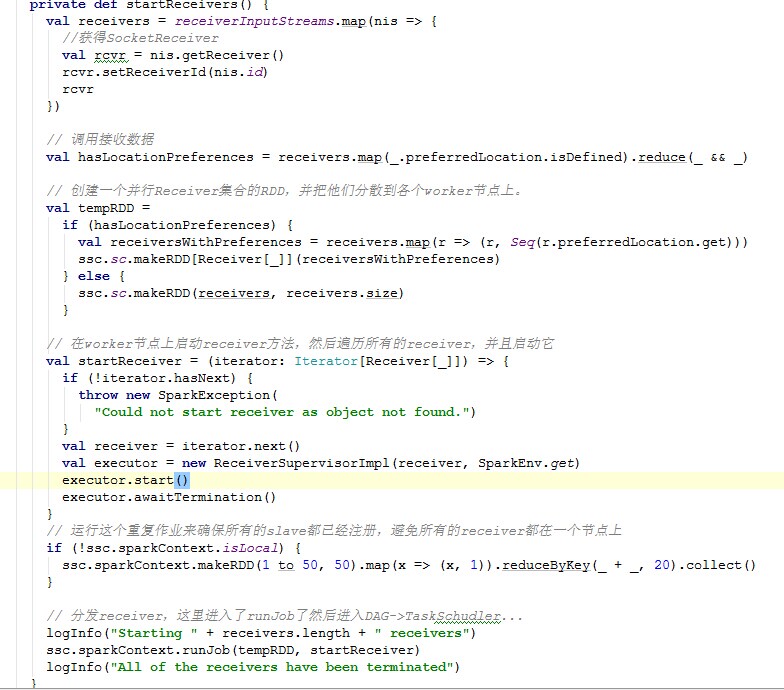
以上是启动startReceivers方法。在这里方法里面new了一个ReceiverSupervisorImpl。然后调用了它的start方法:
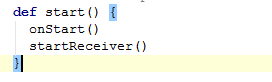
这里重点看startReceiver方法:

这里又调用了onReceiverStart方法,继续点击进去:

onStart方法启动了blockGenerator.start(),然后调用了receiver的onstart方法,开始接收数据。并把数据写入到Receiver-Supervisor。然后调用onReceiverStart()方法,发送RegisterReceiver消息给dirver驱动。
保存数据
保存接到的数据通过调用ReceiverSupervisor的pushSingle方法来保存。
......
启动JobGenerator
前面说了数据的接收和保存,回到JobSchudler中看jobGenerator.start()跟踪数据处理的源码。
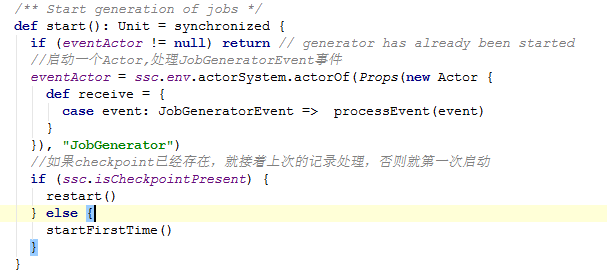
Ok,先进去startFirstTime方法。

Ok,关于时间这块比较绕口。。。。。
继续查看JobSchudler中看jobGenerator.start()。

进入processEvent事件:
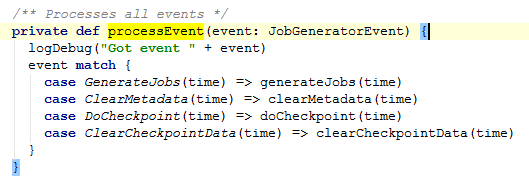
接下来具体看看上述的4个方法:
generateJobs:
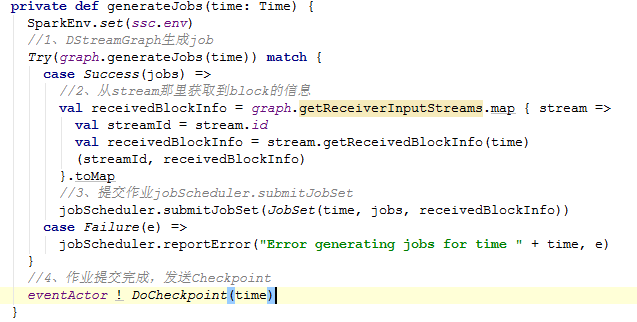
generateJobs方法中分为上述注解的几个步骤。
1、DStreamGraph怎么生成jobs,那么点击generateJobs方法。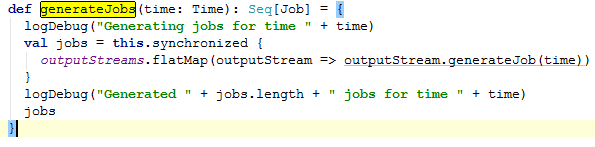
outputStream是在print里面添加的。继续点击generateJobs。方法如下:
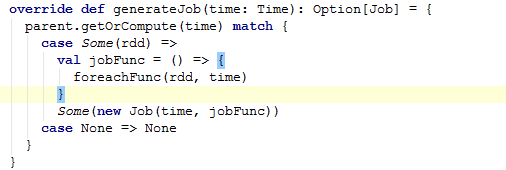
这个方法是ForEachDStream中的generateJob方法。ForEachDStream是DStream的子类。它重写了DStream中的generateJob方法。
该方法根据给定的时间参数产生一个SparkStreaming job.这是一种内部方法,它不应该被直接调用。这个方法默认的实现了创建一个job,并物化相应的RDD。DStream的子类可以重写来完成自己的工作。
继续跟踪,上面源码中通过getOrCompute方法获得RDD。点击getOrCompute方法。源码如下:
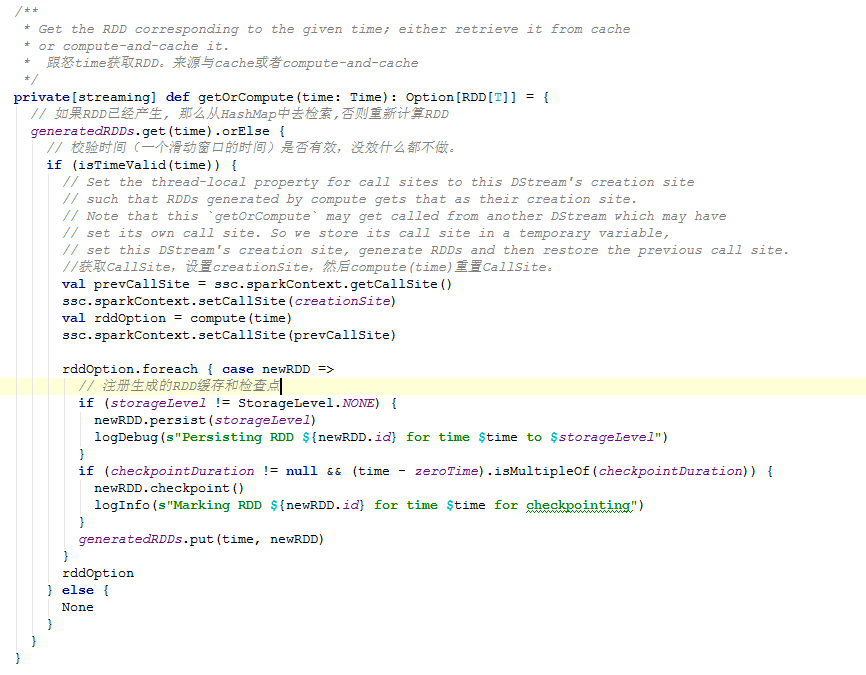
从上述代码中可以看到。她是通过DStream的compute函数的出来的RDD。这里的compute被ReceiverInputDStream中的compute来重写了。源码如下:
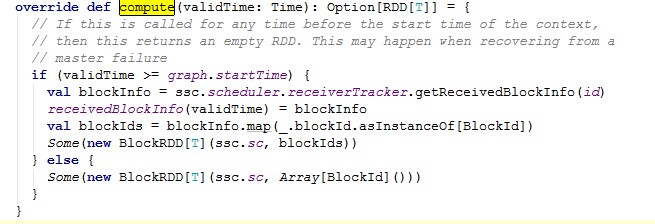
OK,再次回到generateJobs方法。看如下代码:

JobSet就是用来记录Job的完成情况的。点击submitJobSet方法

这里遍历jobs,通过jobExecutor这个线程池提交JobHandler。
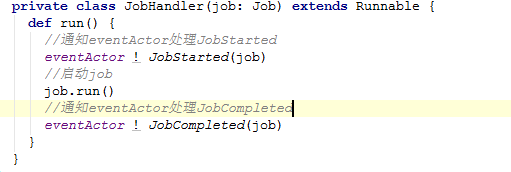
进入job.run这个方法。

在遍历BlockRDD的时候,在compute函数中获取该Block。然后、打印这个RDD结果
等待执行停止
再次回到NetworkWordCount。
ssc.awaitTermination()
等待执行停止。在执行过程中发生的任何异常将被抛出在这个线程。

Conf
| Property Name | Default | Meaning |
| spark.streaming.blockInterval | 200 | Interval (milliseconds) at which data received by Spark Streaming receivers is chunked into blocks of data before storing them in Spark. Minimum recommended - 50 ms. See the performance tuning section in the Spark Streaming programing guide for more details. |
| spark.streaming.receiver.maxRate | infinite | Maximum number records per second at which each receiver will receive data. Effectively, each stream will consume at most this number of records per second. Setting this configuration to 0 or a negative number will put no limit on the rate. See the deployment guide in the Spark Streaming programing guide for mode details. |
| spark.streaming.receiver.writeAheadLogs.enable | false | Enable write ahead logs for receivers. All the input data received through receivers will be saved to write ahead logs that will allow it to be recovered after driver failures. See the deployment guide in the Spark Streaming programing guide for more details. |
| spark.streaming.unpersist | true | Force RDDs generated and persisted by Spark Streaming to be automatically unpersisted from Spark's memory. The raw input data received by Spark Streaming is also automatically cleared. Setting this to false will allow the raw data and persisted RDDs to be accessible outside the streaming application as they will not be cleared automatically. But it comes at the cost of higher memory usage in Spark. |















 1139
1139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









