






目录
OO第三单元作业总结
@
1. JML语言理论基础、应用工具链情况
JML是一种行为借口规范语言( behavioral interface specification language, BISL)。这类的规范通常被称作面向模型,既规定了方法或抽象数据类型的接口,也规定了它们的行为。JML主要基于Leavens等其他开发者的工作。
目前JML的应用工具主要有jml-launcher、jml and jml-gui、jmlc and jmlc-gui、jmldoc and jmldoc-gui、jmle等。官网上有着详细的说明:
一般而言,JML有两种主要的用法:
1) 开展规格化设计。这样交给代码实现人员的将不是可能带有内在模糊性的自然语言描述,而是逻辑严格的规格。
2) 针对已有的代码实现,书写其对应的规格,从而提高代码的可维护性。这在遗留代码的维护方面具有特别重要的意义。
2. 部署SMT Solver
略
3. 部署JMLUnitNG/JMLUnit
我使用的测试代码如下:
// Try.java
import org.omg.CORBA.DynAnyPackage.InvalidValue;
public class Try {
/* @ public normal_behaviour
@ requires (a < 1000 && b < 1000);
@ ensures \result = a + b;
@ also
@ public exceptional_behaviour
@ requires (a >= 1000 || b >= 1000);
@ signal_only InvalidValue;
*/
public static int add(int a, int b) throws InvalidValue {
if (a >= 1000 || b >= 1000) {
throw new InvalidValue();
}
return a + b;
}
public static void main(String[] args) {
try {
int add1 = add(200, 300);
int add2 = add(500, 1000);
int add3 = add(1000, 500);
int add4 = add(1000, 1000);
} catch (InvalidValue e) {
e.printStackTrace();
}
}
}首先使用JMLUnitNG生成测试文件:
#!/bin/bash
java -jar /Users/wsz/我的文档/大二下/OO/jmlunitng.jar "$@"用javac命令编译后,生成的文件目录如下:
但是在用java命令运行Try_JML_Test时却出现无法找到主类的错误,很迷。所以尝试使用idea编译运行,结果如下:
很显然,我的函数通过了所有的测试,符合规格。
第一个racEnable fail是因为我没有用jmlc命令编译Try.java,因为我的jml包有internal error,如下所示:

这次尝试,让我开始熟悉使用JMLUnitNG测试我的代码,打开了新世界的大门?。
4. 作业架构梳理
4.1 第一次作业
第一次作业比较简单,除了distinctNode以外,其他的函数基本上把题目意思理解清楚就能够很快写完。
对于distinctNode,在我初次实现时,我只用了一个TreeSet去保存不同点的编号,如果删除一条路径,就把路径上的结点从TreeSet中删去。但是这回导致一个问题:当多条路径结点重叠时,这样处理就会导致distinctNode的结果比真实值小——因为删去一条路径不代表这条路径上所有的结点都应该被删去,因为可能改结点还存在于其他路径上。
考虑到这种情况后,我该为用一个HashMap去记录distinctNode的情况。其中,key为node的编号,value为图中使用node的path的条数。当加入一条路径时,将路径上所有的node的value加1(如果之前不存在则在HashMap中创建node的key,并将value设置为1)。当删除一条路径时,将路径上所有结点的value减1,如果减1后的结果为0,则从HashMap中删去这个key。这样,当查询DistinctNode时,只需要返回HashMap中有多少个Key就可以了。
4.2 第二次作业
4.2.1 算法设计
第二次作业在第一次作业的基础上,加入了最短路径的计算。最短路径的计算主要有Floyd和dijkstra两个算法。当然,因为这次作业的路径权都相同,所以也可以用BFS计算。但是考虑到下次作业可能会给路径添加不同的权重,所以我果断地排除了BFS的实现。又考虑到Floyd算法复杂度只有在稠密图时比N次dijkstra的算法复杂度低,而测试数据中难以做到当结点的数量很多时,还能是稠密图,所以我决定使用dijkstra算法。
为了优化性能,我主要使用了两个方法:
- 保存dijkstra算法运行中的中间结果。
例如,如果我现在要计算的是从结点1到结点3的最短路径,但在求解过程中我还求解出了结点1到结点2的最短路径,这时候我会将运算过程中求得的结果用HashMap保存下来。当下次询问结点1到结点3的最短路径时,就可以直接返回结果; - 使用了“上下文机制”
当我求解结点1到结点3的最短路径时,有很大可能在得到从结点1到结点3的最短路径结果时,还存在结点到结点1的最短路径未知。如果继续让dijkstra求解过程运行完,则可能会浪费很多性能,因为如果之后没有询问到结点1到这些剩余结点的最短路径,则后面的计算就是多余的。然而,如果在求解完结点1到结点3的最短路径后,立马停止dijkstra求解,则如果下一次询问到结点1到其他结点的最短路径时,如果该最短路径未知,则需要重新从结点1开始进行dijkstra,这无疑也是巨大的性能浪费。
考虑到这两种情况,受到OS中进程上下文的启发,我设计了一种dijkstra上下文的结构。例如,当我求解结点1到结点3的最短路径时,可能当我得到结点1到结点3的最短距离时,从结点1到结点4的最短路径还是未知的。这是,我会将此时的dijkstra算法的中间结果保存下来,并停止当前的dijkstra算法。当下次询问到结点1到结点4的最短距离时,就可以使用之前保存的上下文,在上一次运行的基础上,求解结点1到结点4的最短路径,而不需要从结点1重新求解。这样就可以克服之前提到的两种方法的缺点。
4.2 架构设计
这一次作业,我为了增加架构的灵活性,使用了对象组合的方式而不是继承。具体来说,我的MyGraph类并没有选择继承上一次作业的MyPathContainer类,而是在MyGraph类中设置了一个私有的MyPathContainer类对象,用来实现有关路径的功能。
同时,为了支持新增的功能,我将图的结构抽象成了一个GraphStructure的类,里面实现了图的构建和最小路径的计算等功能。同时在GraphStructure的实现中,我又将dijkstra算法的运算过程单独抽象成了一个类。这样能够使我的代码更加符合模块化设计的标准。
4.3第三次作业
4.3.1 算法设计
第三次作业的算法,较第二次作业而言,更加复杂。但经过一番思考后,我把这次作业新增加的功能:最小票价、最小换乘次数和最小不满意度都转化为了最短路径问题,统一使用dijkstra算法求解。
4.3.2 架构设计
由以上分析可知,由于几种要求都能够转化为最短路径问题,所以在设计架构时,我沿用了上一次作业的GraphStructure类,为其增加了一些适应这次作业的新功能,例如设置边的长度、拆点等等。计算最短路径的OriginGraph,最小票价的PriceGraph,最小换乘次数的TransferGraph和最小不满意度的UnpleasantGraph都继承自GraphStructure类,它们之间的区别在于边的权值不同。然后MySubwaySystem类中创建了originGraph, priceGraph, transferGraph和unpleasantGraph对象,用来实现对应的功能。具体的架构如下图所示: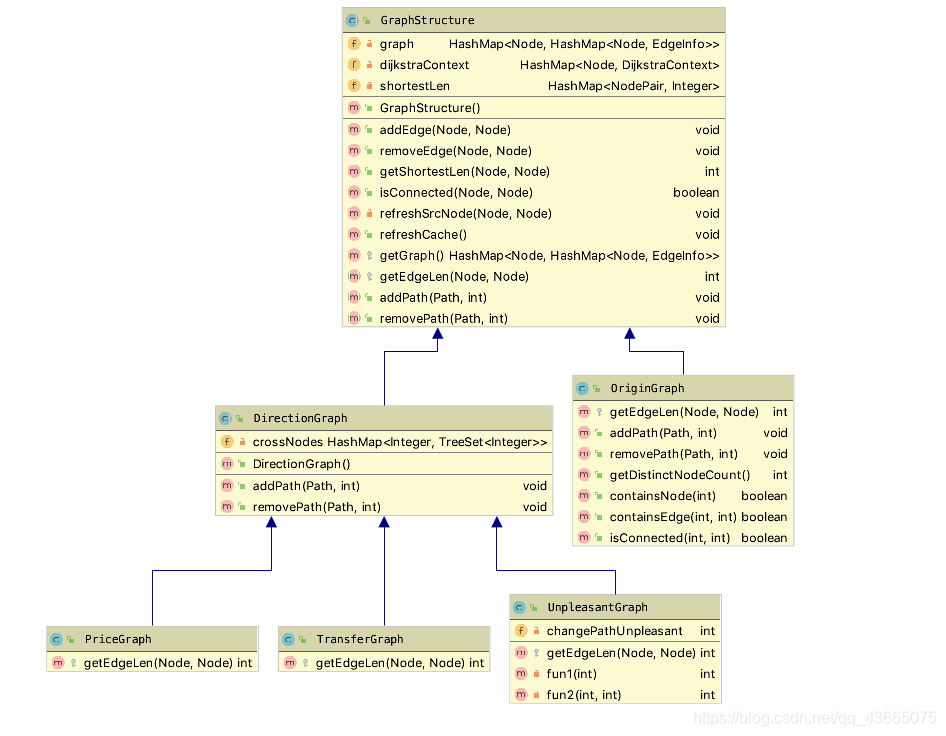
其实这次作业,一开始我的设计并不是这样的。我第一次写的时候,将OriginGraph, PriceGraph, TransferGraph和UnpleasantGraph都写成不想关的类。由于它们之间的功能又很多重叠的地方,所以很多代码也是相同的。这就导致了代码量很大,而且维护的成本很高。我的第一个版本的作业写完后,一直有bug调不出来。考虑到由于架构设计的不好,找bug的成本太高,所以我决定重写一个版本,第二个版本将四个图结构相同的部分抽象出来,通过继承共用代码。虽然第二个版本刚写出来的时候也有bug,但因为架构简单明了,所以很快就把bug找出来并且更正了。这个经历告诉我,优秀的架构对实现、维护都有很大的帮助。
5. bug及修复情况
这三次作业,我强测都没有出现bug。在互测中,第三次作业被刀了ctle。我把数据下载下来运行发现,我的程序用时45s左右,而同屋大佬的程序最快可以到2s以内。通过手动加时间戳的方式,我发现我的程序运行时间绝大部分都花费在dijkstra的计算上。由于我采用的是拆点的方式处理路径之间的交汇情况,所以导致有时候点的个数会非常多,从而大大降低了代码的性能。在修复bug时,我使用了评论区中不拆点的方法,并用Floyd计算。测试证明,在架构不变的情况下,用拆点+dijkstra需要45s的数据,用这种方法只需要2s以内的时间。说明拆点带来的复杂度增加是非常惊人的。
6.关于规格撰写和理解的心得体会
经过这一个单元的学习,我这个以前从来没有听说过规格的小白也算是入了门。个人感觉,规格的作用主要体现在功能要求者和实现者之间的协作上。因为规格化语言具有比自然语言严谨、不具有二义性的特点,可以确保功能要求者的意思完整无误地传达给实现者。同时,功能要求者还可以使用相关工具,利用规格生成测试用例来检验实现者是否完整地实现了其要求的功能。
但是,规格也有它的弱点。因为为了追求严谨性和规范性,有些本来用自然语言几句话就能表达清楚的功能,用jml写可能需要很多行才能描述清楚,不仅功能要求者写起来复杂,功能实现者理解起来也费力。
所以个人的感觉是,在代码撰写中,如果功能表达比较容易产生二义性,则应该使用规格撰写。如果是较为容易表达的功能,则不妨使用自然语言描述,更加清晰易懂。















 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









