






【1】sed工具(Stream Editor)——流编辑器
sed 本身也是一个管线(管道)命令,可以分析 standard input 的啦! 而且 sed 还可以将数据进行取代、删除、新增、截取特定行等等的功能呢!


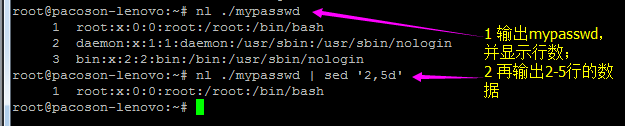
1.1)以行为单位的新增/删除功能
【玩玩荔枝呢】
【输出不是输出是 删除,删除】
1.2)以行为单位的取代与显示功能
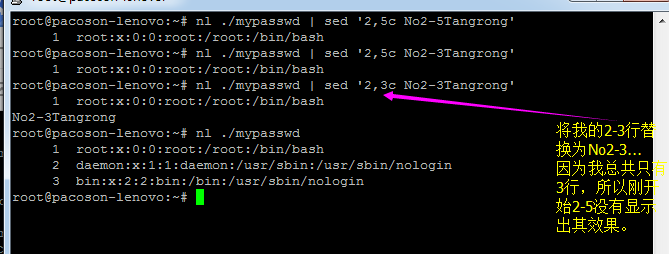
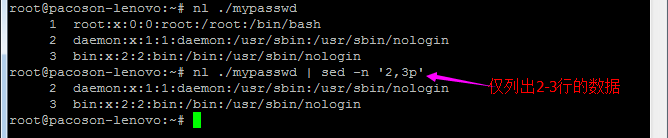
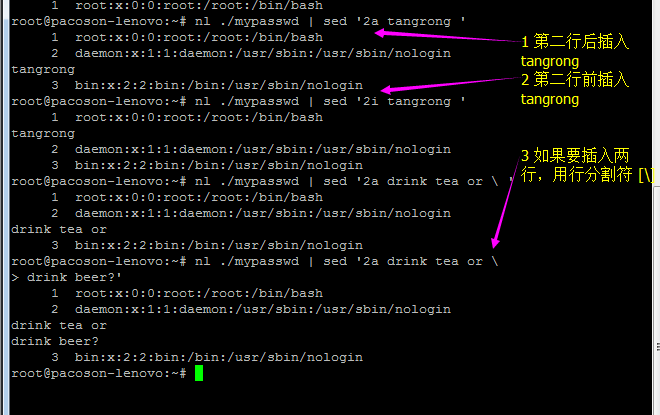
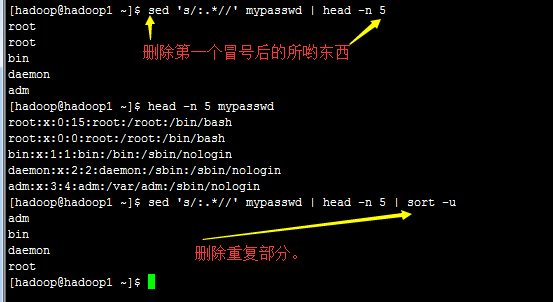
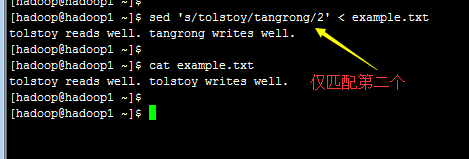
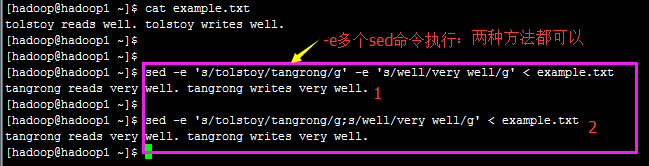
1.3) 部分数据的搜索并取代的功能(g=global)
【Attention】上表中特殊字体的部分为关键词,请记下来!至于三个斜线分成两栏就是新旧字符串的替换啦!

荔枝要求
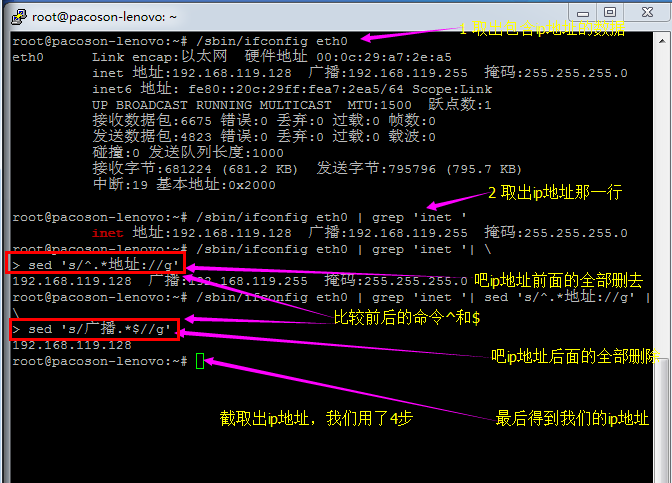
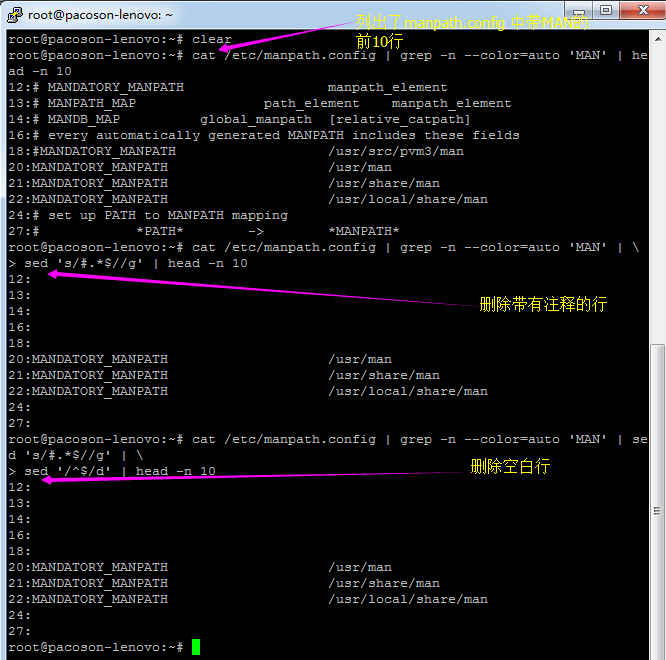
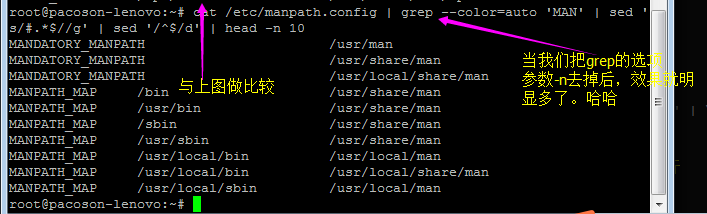
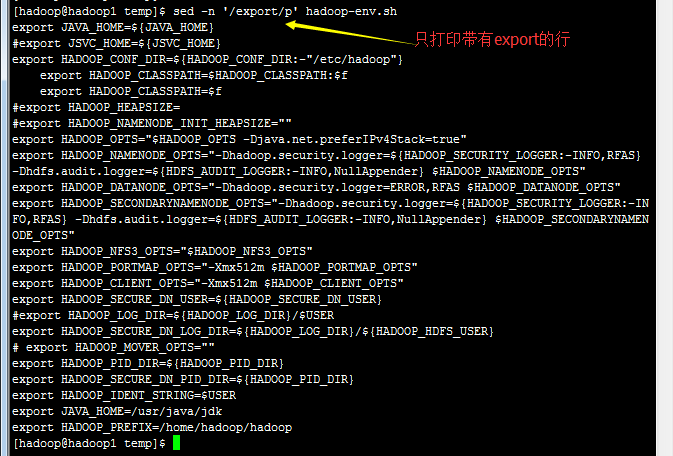
假设我只要 MAN 存在的那几行数据, 但是含有 # 在内的批注我不想要,而且空白行我也不要!此时该如何处理呢?
1.4)直接修改档案内容(危险动作)
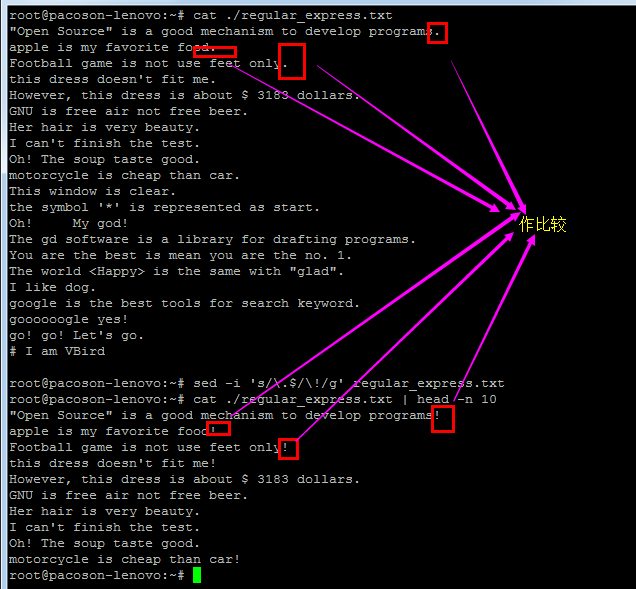
sed 甚至可以直接修改档案的内容呢!
【玩玩荔枝吧】

【Declaration】 以下内容总结于shell脚本学习指南
【1】sed——stream editor 流编辑器
贴一张鸟哥的图片


1.1)替换细节——s命令里以g结尾表示: glocal 全局

1.2)sed的运作
sed 读取每个文件,一次读一行,将读取的行放到内存的一个区域——称为模式空间。
1.3) 你还记得head吗?
head N file
count=$1
sed ${count}q "$2"
# $1=N, $2=file
1.4) 说替换
范围:可指定行的范围,以逗点隔开
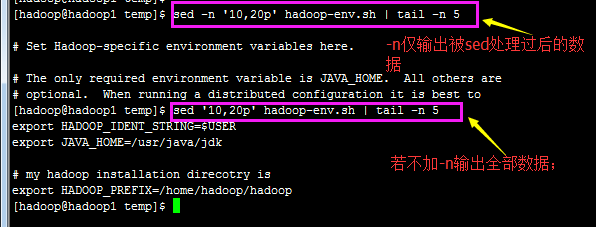
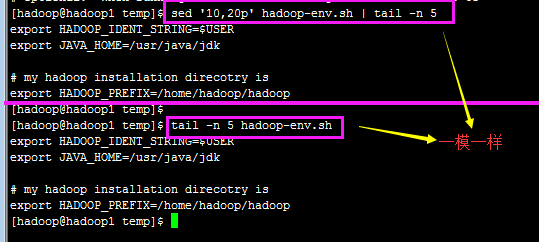
sed -n '10,20p' hadoop.sh 只打印10~20行
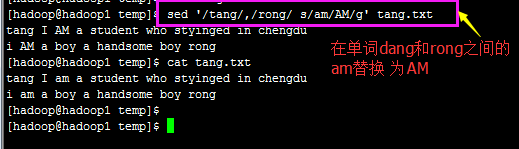
sed -n '/export/,/export/ s/word1/word2/g' 在export和export之间的行,用word2全局替换word1
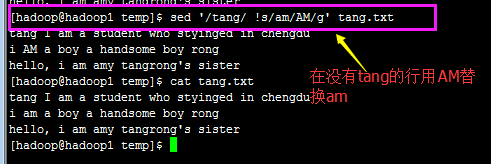
sed -n '/tang/ !s/am/AM/g' tang.txt 在没有tang的行用AM替换am;
1.5)有多少文本会改动
和有多少爱可以重来是一样的?呵呵了?
有多少文本会匹配 + 从哪儿开始匹配?
【Answers】:
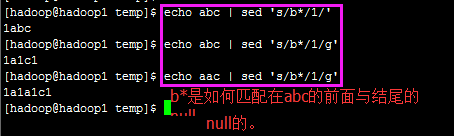
正则表达式可以匹配整个表达式输入文本中最长的,最左边的子字符串。除此之外,匹配的空null字符串,则被认为是比完全不匹配的还长。
如ab*c , 匹配ac, 而b* 成功匹配a c 间的null字符串。
by the way, POSIX指出:完全一致的匹配,指的是最左边开始匹配,针对每一子模式, 由左向右,必须匹配最长的可能字符串。
(子模式指的是在ERE下圆括号的部分)
【看个荔枝,you should got it】

【2】字段处理
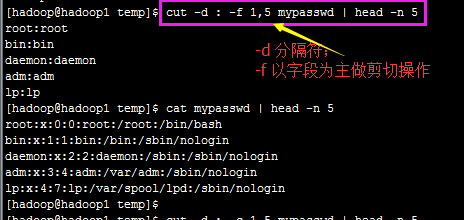
2.1)cut剪切文本
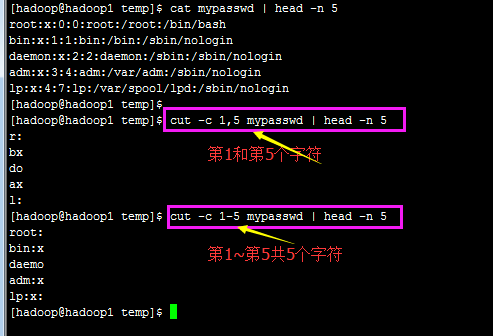
cut -c 以字符为主 做剪切操作 (startup 1)
cut -d 设置分隔符
cut -f 以字段为主 进行剪切操作 (startup 1)
【荔枝时间到】
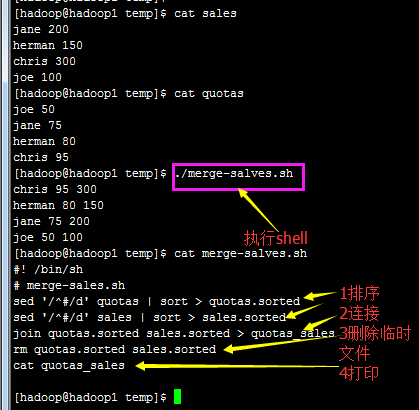
2.2)join连接文本
主要选项
- -1 field1 表明要结合 的 字段
- -2 field2 表明要结合 的 字段
- -o file.field 输出file的field字段,其他字段不打印
- -t seperator 分隔符
【3】使用awk重新编排字段
(以下内容转自鸟哥)
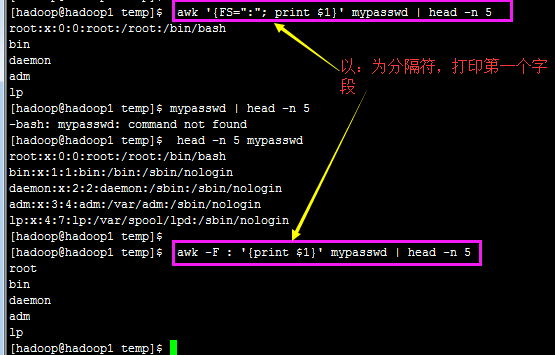
awk 主要是处理『每一行的字段内的数据』,而默认的『字段的分隔符为 “空格键” 或 “[tab]键” 』!
【Attention】注意awk的处理格式。
【相关说明】
以上面的例子来说, root 是 1,因为他是第一栏嘛!至于192.168.1.100是第三栏,所以他就是3 啦!后面以此类推~呵呵!还有个变数喔!那就是 0,0 代表『一整行资料』的意思~以上面的例子来说,第一行的 $0 代表的就是『root …. 』那一行啊!
3.1)awk的处理流程:
- 读入第一行,并将第一行的资料填入 0,1, $2…. 等变数当中;
- 依据 “条件类型” 的限制,判断是否需要进行后面的 “动作”;
- 做完所有的动作与条件类型;
- 若还有后续的『行』的数据,则重复上面 1~3 的步骤,直到所有的数据都读完为止。
经过这样的步骤,你会晓得, awk 是『以行为一次处理的单位』, 而『以字段为最小的处理单位』。
3.2)那么 awk 怎么知道我到底这个数据有几行?
有几栏呢?这就需要 awk 的内建变量的帮忙啦~

【荔枝时间到】
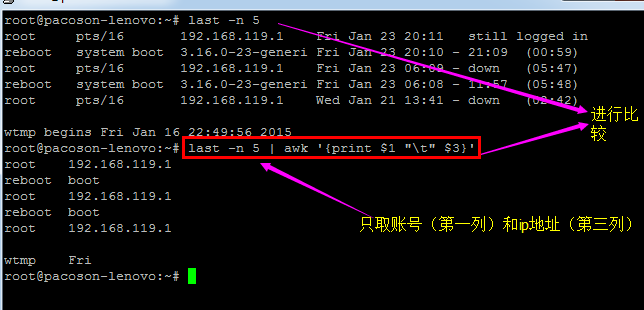
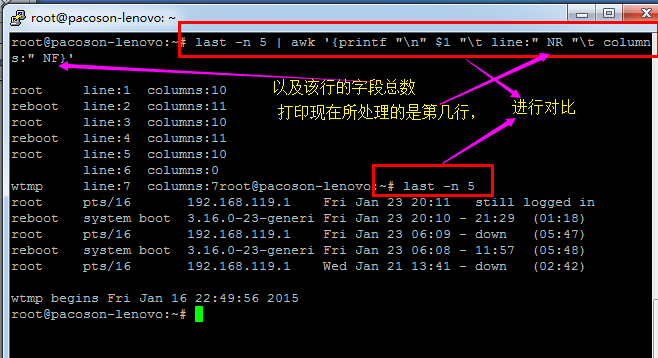
列出每一行的账号(就是 $1);
列出目前处理的行数(就是 awk 内的 NR 变量)
并且说明,该行有多少字段(就是 awk 内的 NF 变量)
【Attention】
要注意喔,awk 后续的所有动作是以单引号『 ’ 』括住的,由于单引号和双引号都必须是成对的, 所以, awk 的格式内容如果想要以 print 打印时,记得非变量的文字部分,包含上一小节 printf 提到的格式中,都需要使用双引号来定义出来喔(单引号里面内嵌双引号)!因为单引号已经是 awk 的指令固定用法了!
【Attention】
注意喔,在 awk 内的 NR, NF 等变量要用大写,且不需要用钱字号 $ 啦!
【Complementary】
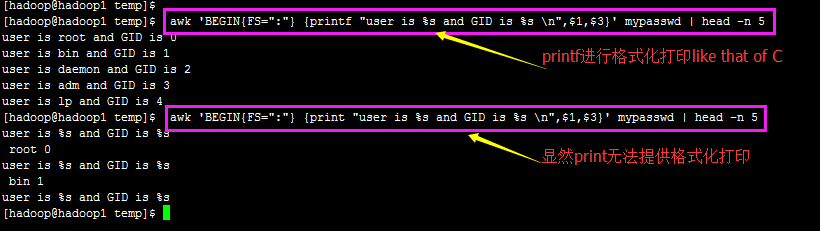
awk的print 语句会自动换行,就想C中的printf语句类似;
但是如果换做用printf来格式化打印字符串的话,就要通过\n转义序列的使用来进行换行功能。
3.3)awk的逻辑运算符号;
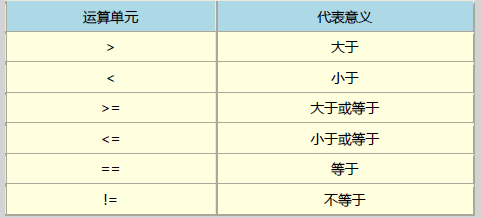
值得注意的是那个『 == 』的符号,因为:
逻辑运算上面亦即所谓的大于、小于、等于等判断式上面,习惯上是以『 == 』来表示;
如果是直接给予一个值,例如变量设定时,就直接使用 = 而已(=赋值变量符号)。
【荔枝又来了】
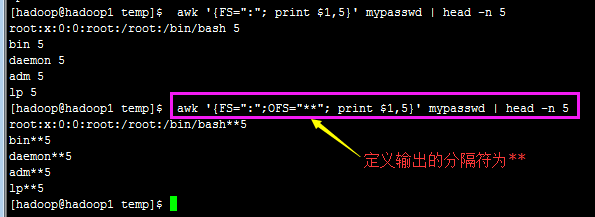
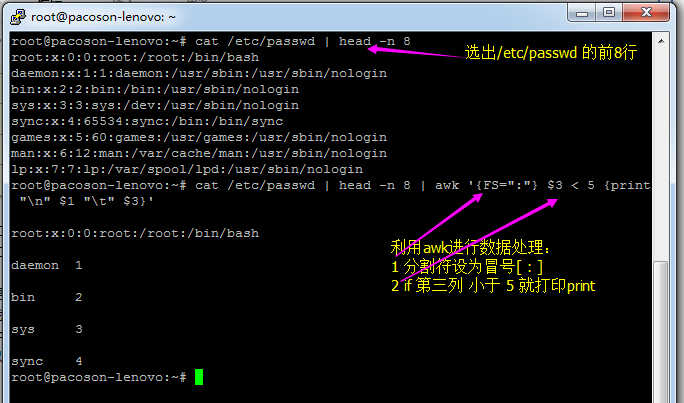
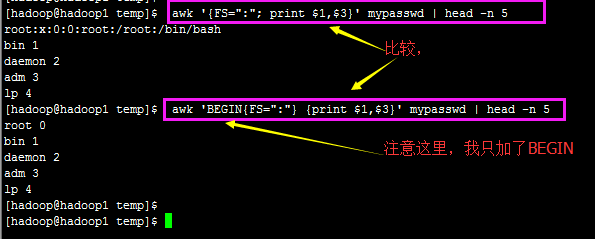
好了,我们实际来运用一下逻辑判断吧!举例来说,在 /etc/passwd 当中是以冒号 “:” 来作为字段的分隔, 该档案中第一字段为账号,第三字段则是 UID。那假设我要查阅,第三栏小于 10 以下的数据,并且仅列出账号和第三栏, 那么可以这样做:
Problem: 有趣吧!不过,怎么第一行没有正确的显示出来呢?
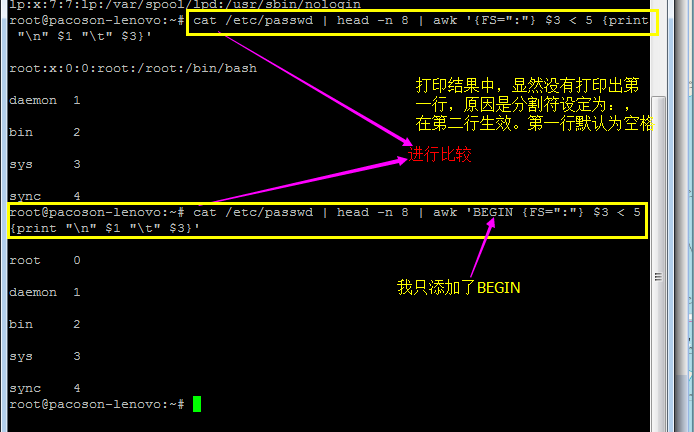
Reason:这是因为我们读入第一行的时候,那些变量 1,2… 默认还是以空格键为分隔的,所以虽然我们定义了 FS=”:” 了, 但是却仅能在第二行后才开始生效。
How to solve it ?那么怎么办呢?我们可以预先设定 awk 的变量啊! 利用 BEGIN 这个关键词喔!这样做:
(Attention:这里鸟哥要比shell脚本学习指南讲的要好得多)
3.4) Relative Specification:
(1)awk的指令间隔:所有 awk 的动作,亦即在 {} 内的动作,如果有需要多个指令辅助时,可利用分号『;』间隔(这就是刚才为什么会报awk语法错误的原因,因为少加了一个分号[;]), 或者直接以 [Enter] 按键来隔开每个指令,例如上面的范例中,鸟哥共按了三次 [enter] 喔!
(2) 逻辑运算当中,如果是『等于』的情况,则务必使用两个等号『==』!
(3) 格式化输出时,在 printf 的格式设定当中,务必加上 \n ,才能进行分行! 不过要用双引号吧\n包起来;
(4) 与 bash shell 的变量不同的是,在 awk 当中,变量是可以直接使用的,不需加上 $ 符号。
【Note】以上的 说明很是重要,牢记。
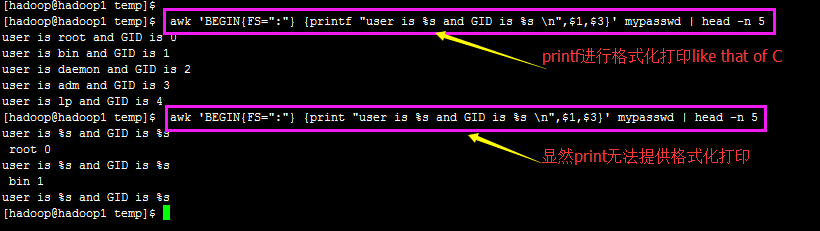
【print 与 printf 的 区别的例子】
(简单说就是print只能简单的打印字段列表并自动换行,而printf不能提供自动换行,但是可以进行格式化打印 like C language)
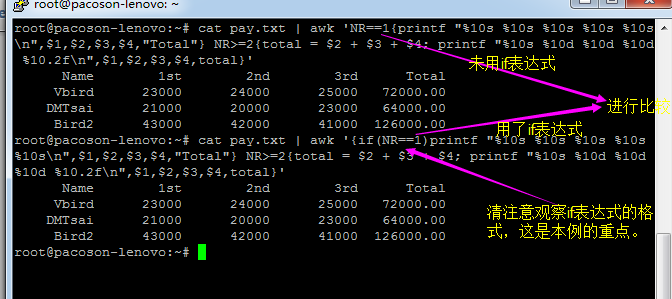

















 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









