 Kafka架构与原理
Kafka架构与原理




 本文介绍了Kafka的基本架构和工作原理,包括其作为分布式消息系统的特性,如消息存储、高吞吐率、分布式特性和实时处理能力。文章还详细解释了Kafka中的关键组件,如Producer、Consumer、Broker以及它们如何通过Topics、Partitions和Replications协同工作。
本文介绍了Kafka的基本架构和工作原理,包括其作为分布式消息系统的特性,如消息存储、高吞吐率、分布式特性和实时处理能力。文章还详细解释了Kafka中的关键组件,如Producer、Consumer、Broker以及它们如何通过Topics、Partitions和Replications协同工作。
接下来的这些博客,主要内容来自《Learning Apache Kafka Second Edition》这本书,书不厚,200多页。接下来摘录出本书中的重要知识点,偶尔参考一些网络资料,并伴随着一些动手实践,算是一篇读书笔记吧。
本文是第一篇,主要从整体上梳理Kafka的基本架构和原理。
一、什么是Kafka
Kafka是一个开源的,分布式的消息发布和订阅系统,它由Producer, Consumer和Broker组成。使用Kafka可以实时传递和处理一些Message。总的来说,Kafka有以下几个特点:
1. 消息存储
为了保证数据的完整性,Kafka将数据保存在硬盘上,并且对数据还有备份。Kafka可以在O(1)的时间复杂度内访问高达TB级别的数据。
2. 高吞吐率
Kafka本身就是为大数据的场景设计的,在一些简单的硬件上也可以实现高达几百MB的读写。
3. 分布式
Kafka可以分布的安装在多个节点上,Message以分区的形式保存在集群中。
4. 支持多client
Kafka系统可以支持多种形式的Client,包括Java,.NET, PHP, Ruby以及Python。
5. 实时
Producer产生的消息可以很快的被Consumer进行消费。
二、Kafka概览
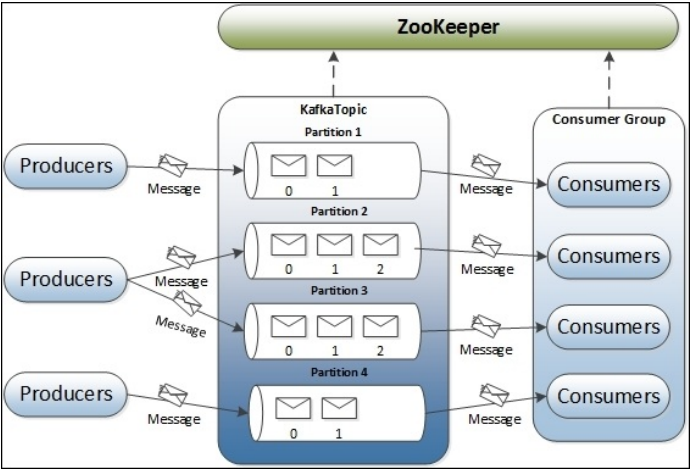
Kafka实质上是一个生产者-消费者系统。在Kafka中,Producer产生Message并发送到Kafka Topic中。Consumer则会从Kafka Topic中订阅并消费Message。Kafka集群中的各个节点被称为Broker,Topic都是保存在Broker上的。在Kafka系统中还会用到ZooKeeper,主要是Broker使用ZooKeeper记录一些状态信息,Consumer则通过ZooKeeper记录Message消费的Offset。整体架构如下图所示,其中涉及到的概念和组件,会在后续章节中进一步分析。
每个Partition对应一个物理log文件,这个log文件由一系列大小相等的segment组成。每一个Partition是一个有序的,可扩展的Message队列。当有message发送到partition中时,broker会将该message追加到最新的segment末尾。当接收到若干条message,或者经过若干时间后,这个segment就会flush到磁盘上。接下来Consumer才能去磁盘上消费其中的message。所有的Pattition都有一个标识message位置的序列号offset.
并且每个partition也可以配置若干replication,以保证其容错能力。根据replication的个数,每个partition有一个leader状态的replication,以及0个或多个follower状态的partition。有关message的读写操作,都由leader状态的replication来完成。follower会从leader同步数据,这些活跃的follower就被称为in-sync replicas(ISR),ZooKeeper中会记录每个partition的最新的ISR,当leader出现故障时,ZooKeeper会从ISR中选举出新的leader。
一个Topic中的message只能被同一Consumer Group中唯一一个Consumer进行消费,能同时消费某一Topic的Consumer只能分属于不同的Consumer Group。Consumer从一个Partition中顺序的消费message,并且会维持一个offset标记message的消费位置。Message虽然存储在Broker中,但是Broker并不会存储Message的消费状态,每个Consumer自行管理自己的Message消费信息。
三、Kafka消息机制
这里主要涉及三个概念,Topic,Partition,Replication。
在Kafka中,Message都有一个属于的Topic,Message只能发送到指定的Topic中。Topic是一个逻辑上的概念,每个Topic有一个或多个Parititon,这些Partition分布在Broker上,并且是真正的Message存储组件,Topic的每一个Partition对应一个磁盘上的Log文件。
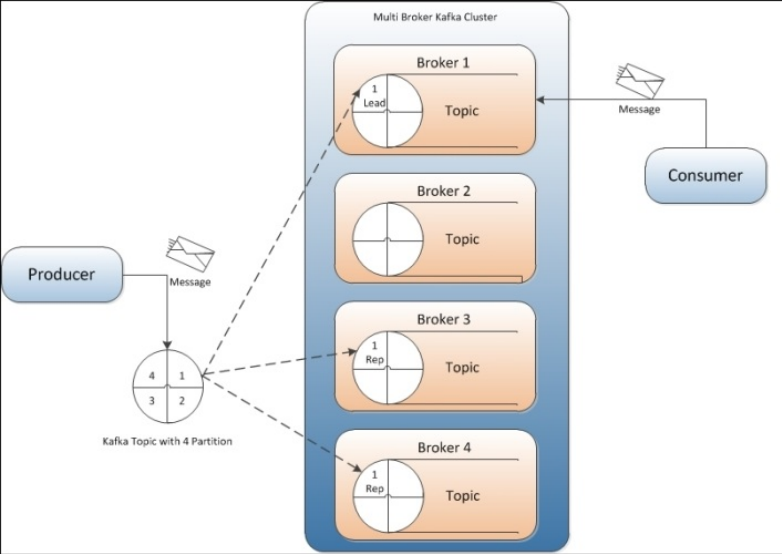
Message发送到哪个Partition是由Producer来决定的。上图中所示的Topic有4个Partition,Producer产生一条Message时,便决定了该Message应该发送到Partition-1。同时,为了保证Kafka集群的容错能力,对应该Partition有3个Replication,其中一个为Lead状态,如Broker-1,有两个Follower状态,如上图中的Broker-3和Broker-4所示。由于Kafka有了Replication机制,所以当前Partition-1,可以允许失败两次,当有Replication失败时,会由ZooKeeper很快选举出新的Lead状态的Replication。Consumer只从Lead状态的那个Replication读取Message。
在这里,我们并不能说Kafka集群中的某个Broker是Leader,某个Broker是Follower,因为Leader和Follower都是针对Replication来说的。对于Partition-1,可能当前的Leader Replication位于Broker-1上,但是对于Partition-2,Leader的Replication就可能位于Broker-2上了。
Kafka中的读写操作,都是由Leader来完成的。其他in-sync replicas(ISR)与Leader进行数据备份。备份方式有以下两种:
1、同步Replication
在这种模式下,Producer计算出对应的Partition后便从ZooKeeper获取Leader状态的Replication,并把Message发送到该Replication。当这条Message写入到Log文件后,所有的Follower开始pull该Message到自己的Log文件中,这个过程完成后Follower会向Leader发送一条确认消息,表示当前Message已经正确备份。当备份过程完成,并且Leader获取到所有期望的确认消息后,Leader再向Producer发送一条确认消息,表示当前Message已经正确的写入了。
2、异步Replication
异步模式与同伴模式唯一的不同在于,当Leader将Message写入自己的Log文件后,就马上向Producer发送一条确认消息,而不会等待接收到所有Follower发送的确认消息才进行该操作。
当任何一个Follower失败时,Leader会将该该Follower从ISR中移除。当失败的Follower恢复正常后,该Follower首先会把失败时的offset之后的数据都清除掉,任何从此次开始对Leader进行数据同步,直到追上最新的message,这个Follower才会从新加入到ISR中。
当Leader失败时,会由ZooKeeper从所有的Follower中选举出某个Follower为新的Leader。
Kafka中最重要的两个组件,Producer和Consumer会在接下来的博客中进行分析。由于Producer和Consumer都提供了API接口,所以,接下来的博客也会根据这些接口实现一些简单的代码。


















 1547
1547

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









