






CSS 可以比较灵活选择控件的任意属性,一般情况下定位速度要比XPath 快,但对于初学者来说比较
难以学习使用,下面我们就详细的介绍CSS 的语法与使用。
一、CSS 选择器的常见语法: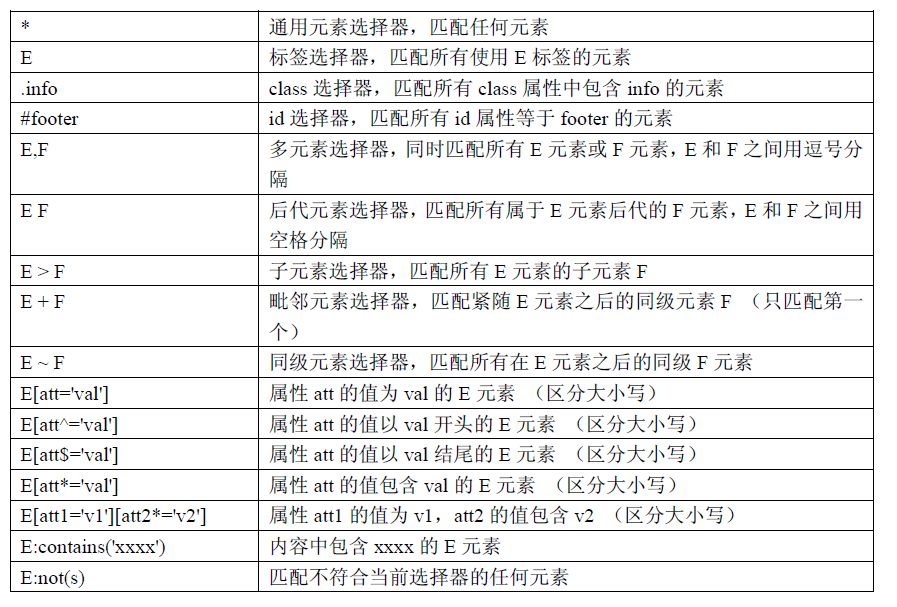
例如下面一段代码:
<div class="formdiv">
<form name="fnfn">
<input name="username" type="text"></input>
<input name="password" type="text"></input>
<input name="continue" type="button"></input>
<input name="cancel" type="button"></input>
<input value="SYS123456" name="vid" type="text">
<input value="ks10cf6d6" name="cid" type="text">
</form>
<div class="subdiv">
<ul id="recordlist">
<p>Heading</p>
<li>Cat</li>
<li>Dog</li>
<li>Car</li>
<li>Goat</li>
</ul>
</div>
</div>
通过CSS 语法进行匹配的实例:
| cssSelector | 匹配 |
| css=div | <div class="formdiv"> |
| css=div.formdiv | <div class="formdiv"> |
| css=#recordlist css=ul#recordlist | <ul id="recordlist"> |
| css=div.subdiv p | <p>Heading</p> |
| css=div.subdiv>ul>p | <p>Heading</p> |
| css=form+div | <div class="subdiv"> |
| css=p+li | <li>Cat</li> |
| css=p~li | <li>Cat</li> 得到4个li中的第一个 |
| css=form>input[name=username] | <input name="username" type="text"></input> |
| css=input[name$=id][value^=SYS] | <input value="SYS123456" name="vid" type="text"> |
| css=input[value*='SYS'] | <input value="SYS123456" name="vid" type="text"> |
| css=a:link | <a href="http://www.baidu.com">baidu</a> |
| css=input:first-child | <input name="username" type="text"></input> |
| css=input:last-child | <input value="ks10cf6d6" name="cid" type="text"> |
| css=li:nth-child(2) | <li>Cat</li> 因为这个li是ul下的第二个元素,所以是child(2) |
| css=:root | <html> |
二、css 中的结构性定位
结构性定位就是根据元素的父子、同级中位置来定位,css3标准中有定义一些结构性定位伪类如
nth-of-type,nth-child,但是使用起来语法很不好理解,这里就不做介绍了。
Selenium 中则是采用了来自Sizzle 的css3定位扩展,它的语法更加灵活易懂。
Sizzle Css3的结构性定位语法:


例如下面一段代码:
<div class="subdiv">
<ul id="recordlist">
<p>Heading</p>
<li>Cat</li>
<li>Dog</li>
<li>Car</li>
<li>Goat</li>
</ul>
</div>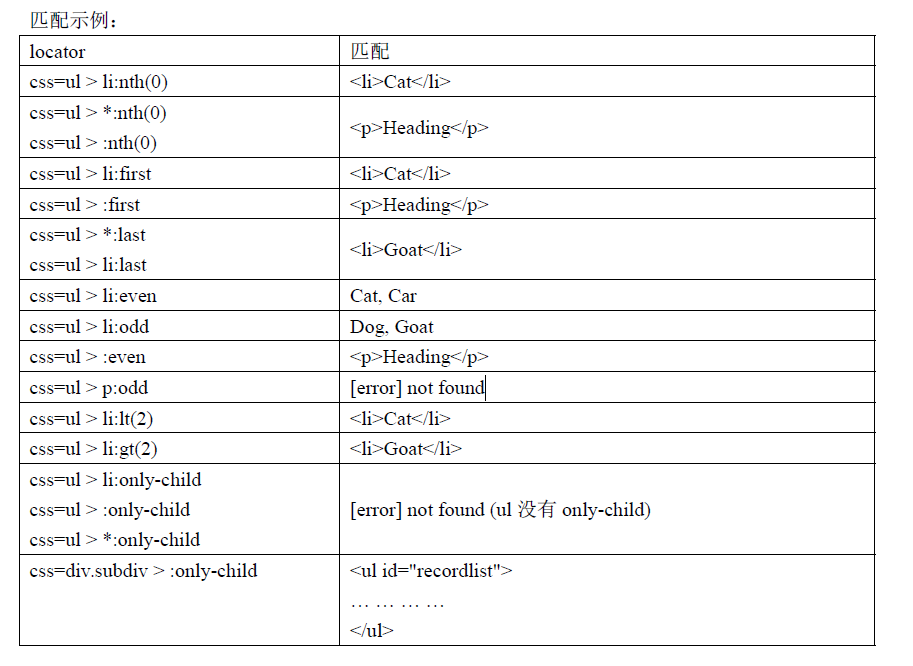
三、下面是一些XPATH 和CSS 的类似定位功能比较。
| 定位方式 | XPath | CSS |
| 标签 | //div | div |
| By id | //div[@id='recordlist'] | div#recordlist |
| By class | //div[@class='subdiv'] //div[contains(@class,'subdiv')] | div.subdiv |
| By 属性 | //input[@name='username'] | input[name=username] input[name^=user] input[name$=name] input[name*=erna] |
| 定位子元素 | //ul[@id='recordlist']/* //ul/p | ul#recordlist>* ul#recordlist>p |
| 定位后代元素 | //div[@class='subdiv']//p | div p |
| By index | //li[4] 定位第四个li | li:nth-child(5) |
| By content | //li[contains(text(),'Goa')] | li contains('Goa') 该方法 已经废弃 |
| 根据子元素回溯定位父元素 | //*[./a[@id='baiduUrl']] //div[.//p[text()='Heading']] 匹配到:<div class="subdiv"> | ? |
| 根据兄弟元素定位 | //ul[preceding-sibling::a[@id='baiduUrl']] //ul[preceding-sibling::a[//div[@class='subdiv']/a]] 都匹配到:<ul id="recordlist"> | a+ul a#baiduUrl+ul 匹配到:<ul id="recordlist"> |
通过对比,我们可以看到,CSS 定位语法比XPath 更为简洁,定位方式更多灵活多样;不过对CSS 理
解起来要比XPath 较难;但不管是从性能还是定位更复杂的元素上,CSS 优于XPath,笔者更推荐使用CSS
定位页面元素。















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









