







Redis基础数据结构有哪些?
一、String(字符串)
在任何一种编程语言里,字符串String都是最基础的数据结构, 那你有想过Redis中存储一个字符串都进行了哪些操作嘛?
在Redis中String是可以修改的,称为动态字符串(Simple Dynamic String简称SDS)(快拿小本本记名词,要考的),说是字符串但它的内部结构更像是一个ArrayList,内部维护着一个字节数组,并且在其内部预分配了一定的空间,以减少内存的频繁分配。
Redis的内存分配机制是这样:
- 当字符串的长度小于 1MB时,每次扩容都是加倍现有的空间。
- 如果字符串长度超过 1MB时,每次扩容时只会扩展 1MB 的空间。
这样既保证了内存空间够用,还不至于造成内存的浪费,字符串最大长度为512MB.。

上图就是字符串的基本结构,其中content里面保存的是字符串内容,0x0作为结束字符不会被计算len中。
分析一下字符串的数据结构
struct SDS{ T capacity; //数组容量 T len; //实际长度 byte flages; //标志位,低三位表示类型 byte[] content; //数组内容}capacity和len两个属性都是泛型,为什么不直接用int类型?因为Redis内部有很多优化方案,为更合理的使用内存,不同长度的字符串采用不同的数据类型表示,且在创建字符串的时候len会和capacity一样大,不产生冗余的空间,所以String值可以是字符串、数字(整数、浮点数) 或者 二进制。
1、应用场景:
存储key-value键值对,这个比较简单不细说了
2、字符串(String)常用的命令:

set [key] [value] 给指定key设置值(set 可覆盖老的值)get [key] 获取指定key 的值del [key] 删除指定keyexists [key] 判断是否存在指定keymset [key1] [value1] [key2] [value2] ...... 批量存键值对mget [key1] [key2] ...... 批量取keyexpire [key] [time] 给指定key 设置过期时间 单位秒setex [key] [time] [value] 等价于 set + expire 命令组合setnx [key] [value] 如果key不存在则set 创建,否则返回0incr [key] 如果value为整数 可用 incr命令每次自增1incrby [key] [number] 使用incrby命令对整数值 进行增加 number二、list(列表)
Redis中的list和Java中的LinkedList很像,底层都是一种链表结构,list的插入和删除操作非常快,时间复杂度为 0(1),不像数组结构插入、删除操作需要移动数据。
像归像,但是redis中的list底层可不是一个双向链表那么简单。
当数据量较少的时候它的底层存储结构为一块连续内存,称之为ziplist(压缩列表),它将所有的元素紧挨着一起存储,分配的是一块连续的内存;当数据量较多的时候将会变成quicklist(快速链表)结构。
可单纯的链表也是有缺陷的,链表的前后指针prev和next会占用较多的内存,会比较浪费空间,而且会加重内存的碎片化。在redis 3.2之后就都改用ziplist+链表的混合结构,称之为quicklist(快速链表)。
下面具体介绍下两种链表
ziplist(压缩列表)
先看一下ziplist的数据结构,
struct ziplist{ int32 zlbytes; //压缩列表占用字节数 int32 zltail_offset; //最后一个元素距离起始位置的偏移量,用于快速定位到最后一个节点 int16 zllength; //元素个数 T[] entries; //元素内容 int8 zlend; //结束位 0xFF}int32 zlbytes: 压缩列表占用字节数 int32 zltail_offset: 最后一个元素距离起始位置的偏移量,用于快速定位到最后一个节点
`int16 zllength`:元素个数`T[] entries`:元素内容`int8 zlend`:结束位 0xFF压缩列表为了支持双向遍历,所以才会有ztail_offset这个字段,用来快速定位到最后一 个元素,然后倒着遍历
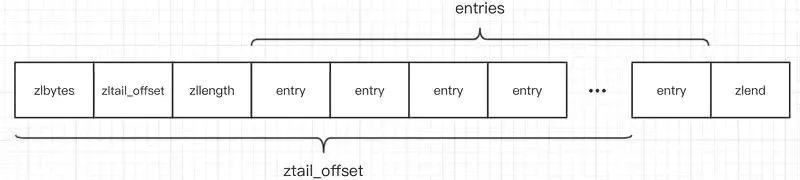
entry的数据结构:
struct entry{ int prevlen; //前一个 entry 的长度 int encoding; //元素类型编码 optional byte[] content; //元素内容}entry它的prevlen字段表示前一个entry的字节长度,当压缩列表倒着遍历时,需要通过这 个字段来快速定位到下一个元素的位置。
1、应用场景:
由于list它是一个按照插入顺序排序的列表,所以应用场景相对还较多的,例如:
- 消息队列:lpop和rpush(或者反过来,lpush和rpop)能实现队列的功能
- 朋友圈的点赞列表、评论列表、排行榜:lpush命令和lrange命令能实现最新列表的功能,每次通过lpush命令往列表里插入新的元素,然后通过lrange命令读取最新的元素列表。
2、list操作的常用命名:
rpush [key] [value1] [value2] ...... 链表右侧插入rpop [key] 移除右侧列表头元素,并返回该元素lpop [key] 移除左侧列表头元素,并返回该元素llen [key] 返回该列表的元素个数lrem [key] [count] [value] 删除列表中与value相等的元素,count是删除的个数。 count>0 表示从左侧开始查找,删除count个元素,count<0 表示从右侧开始查找,删除count个相同元素,count=0 表示删除全部相同的元素(PS: index 代表元素下标,index 可以为负数, index= 表示倒数第一个元素,同理 index=-2 表示倒数第二 个元素。)lindex [key] [index] 获取list指定下标的元素 (需要遍历,时间复杂度为O(n))lrange [key] [start_index] [end_index] 获取list 区间内的所有元素 (时间复杂度为 O(n))ltrim [key] [start_index] [end_index] 保留区间内的元素,其他元素删除(时间复杂度为 O(n))三、hash (字典)
Redis中的Hash和 Java的HashMap更加相似,都是数组+链表的结构,当发生 hash 碰撞时将会把元素追加到链表上,值得注意的是在Redis的Hash中value只能是字符串.
hset books java "Effective java" (integer) 1hset books golang "concurrency in go" (integer) 1hget books java "Effective java"hset user age 17 (integer) 1hincrby user age 1 #单个 key 可以进行计数 和 incr 命令基本一致 (integer) 18Hash和String都可以用来存储用户信息 ,但不同的是Hash可以对用户信息的每个字段单独存储;String存的是用户全部信息经过序列化后的字符串,如果想要修改某个用户字段必须将用户信息字符串全部查询出来,解析成相应的用户信息对象,修改完后在序列化成字符串存入。而 hash可以只对某个字段修改,从而节约网络流量,不过hash内存占用要大于String,这是hash的缺点。
1、应用场景:
- 购物车:hset [key] [field] [value]命令, 可以实现以用户Id,商品Id为field,商品数量为value,恰好构成了购物车的3个要素。
- 存储对象:hash类型的(key, field, value)的结构与对象的(对象id, 属性, 值)的结构相似,也可以用来存储对象。
2、hash常用的操作命令:
hset [key] [field] [value] 新建字段信息hget [key] [field] 获取字段信息hdel [key] [field] 删除字段hlen [key] 保存的字段个数hgetall [key] 获取指定key 字典里的所有字段和值 (字段信息过多,会导致慢查询 慎用:亲身经历 曾经用过这个这个指令导致线上服务故障)hmset [key] [field1] [value1] [field2] [value2] ...... 批量创建hincr [key] [field] 对字段值自增hincrby [key] [field] [number] 对字段值增加number四、set(集合)
Redis中的set和Java中的HashSet有些类似,它内部的键值对是无序的、唯一 的。它的内部实现相当于一个特殊的字典,字典中所有的value都是一个值 NULL。当集合中最后一个元素被移除之后,数据结构被自动删除,内存被回收。
1、应用场景:
- 好友、关注、粉丝、感兴趣的人集合: 1)sinter命令可以获得A和B两个用户的共同好友; 2)sismember命令可以判断A是否是B的好友; 3)scard命令可以获取好友数量; 4) 关注时,smove命令可以将B从A的粉丝集合转移到A的好友集合
- 首页展示随机:美团首页有很多推荐商家,但是并不能全部展示,set类型适合存放所有需要展示的内容,而srandmember命令则可以从中随机获取几个。
- 存储某活动中中奖的用户ID ,因为有去重功能,可以保证同一个用户不会中奖两次。
2、set的常用命令:
sadd [key] [value] 向指定key的set中添加元素smembers [key] 获取指定key 集合中的所有元素sismember [key] [value] 判断集合中是否存在某个valuescard [key] 获取集合的长度spop [key] 弹出一个元素srem [key] [value] 删除指定元素五、zset(有序集合)
zset也叫SortedSet一方面它是个set,保证了内部 value 的唯一性,另方面它可以给每个 value 赋予一个score,代表这个value的排序权重。它的内部实现用的是一种叫作“跳跃列表”的数据结构。
1、应用场景:
zset可以用做排行榜,但是和list不同的是zset它能够实现动态的排序,例如: 可以用来存储粉丝列表,value 值是粉丝的用户 ID,score 是关注时间,我们可以对粉丝列表按关注时间进行排序。
zset还可以用来存储学生的成绩,value值是学生的 ID,score是他的考试成绩。 我们对成绩按分数进行排序就可以得到他的名次。
2、zset有序集合的常用操作命令:
zadd [key] [score] [value] 向指定key的集合中增加元素zrange [key] [start_index] [end_index] 获取下标范围内的元素列表,按score 排序输出zrevrange [key] [start_index] [end_index] 获取范围内的元素列表 ,按score排序 逆序输出zcard [key] 获取集合列表的元素个数zrank [key] [value] 获取元素再集合中的排名zrangebyscore [key] [score1] [score2] 输出score范围内的元素列表zrem [key] [value] 删除元素zscore [key] [value] 获取元素的score
作者:前程有光
链接:https://juejin.im/post/5ede2833f265da76c11347bd














 4332
4332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









