






Flannel官网:https://github.com/coreos/flannel
Flannel是CoreOS团队针对Kubernetes设计的一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建的Docker容器都具有全集群唯一的虚拟IP地址
Flannel是 Kubernetes 中常用的网络配置工具,用于配置第三层(网络层)网络结构。
Flannel 需要在集群中的每台主机上运行一个名为 flanneld 的代理程序,负责从预配置地址空间中为每台主机分配一个网段。
Flannel 直接使用 Kubernetes API 或 ETCD 存储网络配置、分配的子网以及任何辅助数据(如主机的公网 IP)。数据包使用几种后端机制之一进行转发,包括 VXLAN 和各种云集成。
Flannel实质上是一种“覆盖网络(overlaynetwork)”,也就是将TCP数据包装在另一种网络包里面进行路由转发和通信,
Flannel目前已经支持udp、vxlan、host-gw、aws-vpc、gce和alloc路由等数据转发方式,默认的节点间数据通信方式是UDP转发。
数据从源容器中发出后,经由所在主机的docker0虚拟网卡转发到flannel0虚拟网卡,这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外一端。
Flannel通过Etcd服务维护了一张节点间的路由表。
源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直 接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的docker0虚拟网卡,
最后就像本机容器通信docker0路由到达目标容 器。
Flannel 可以与几种不同的后端搭配。一旦后端设置完成,就不应在运行时更改参考这里
一:VxLAN(Virtual extensible Local Area Network)虚拟可扩展局域网
使用内核的 VXLAN 封装数据包。 采用MAC in UDP封装方式,报文如下:

具体的实现方式为:
- 1、将虚拟网络的数据帧添加到VxLAN首部,封装在物理网络的UDP报文中
- 2、以传统网络的通信方式传送该UDP报文
- 3、到达目的主机后,去掉物理网络报文的头部信息以及VxLAN首部,并交付给目的终端
跨节点的Pod之间的通信就是以上的一个过程,整个过程中通信双方对物理网络是没有感知的。如下网络图:
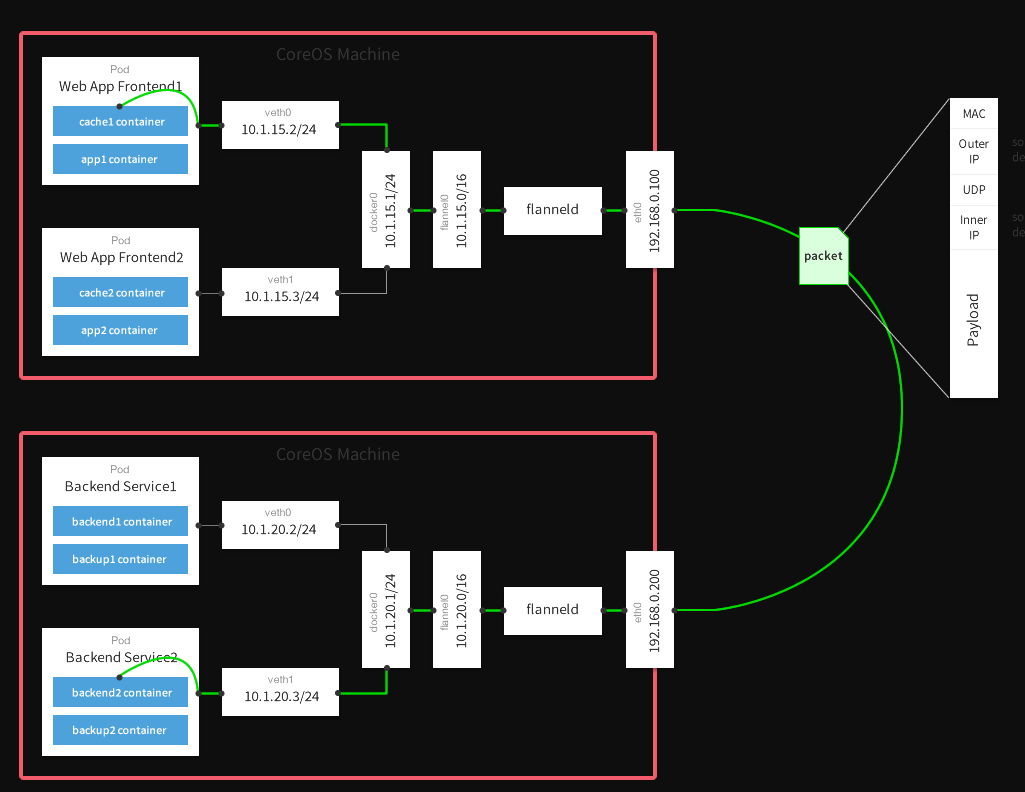
配置参数:
NetWork:flannel 使用CIDR格式的网络地址,为pod配置网络
比如下面网络规划到K8S 中
10.244.0.0/16 ->
master:10.244.0.0/24
node1:10.244.1.0/24
....
node255:10.244.255.0/24
SubnetLen: 把NetWrok切分为子网供各节点使用时,使用多长的掩码进行切分,默认24位
SubnetMin:10.244.10.0/24 定义起始的第一个子网
SubnetMax:10.244.100.0/24 定义最大到那个子网
Type 和选项:
Type:字符串,vxlan
VNI:数字,要使用的 VXLAN Identifier (VNI) 。默认是 1。
Port:数字,用于发送封装的数据包 UDP 端口。默认值由内核决定,目前是 8472。
GBP:布尔值,启用 基于 VXLAN 组的策略。默认是 false。
DirectRouting:布尔值,当主机位于同一子网时,启用直接路由(类似 host-gw)。VXLAN 将仅用于将数据包封装到不同子网上的主机。默认为 false
在K8S 集群,查看flannel的运行状态,前提是安装了这个插件
[root@k8s-master k8s]# kubectl get daemonset -n kube-system |egrep flannel
kube-flannel-ds-amd64 3 3 3 3 3 beta.kubernetes.io/arch
[root@k8s-master k8s]# kubectl get pods -n kube-system -o wide |egrep flannel|awk '{print $1,$6,$7}'
kube-flannel-ds-amd64-cmdzj 10.211.55.13 k8s-node2
kube-flannel-ds-amd64-h9r4z 10.211.55.12 k8s-node1
kube-flannel-ds-amd64-mb865 10.211.55.11 k8s-master
可以看到,在每个节点上都启动一个flannel的Pod,来维护各节点pod的网络
kubectl get configmap kube-flannel-cfg -o yaml -n kube-system
通过查看cm资源查看flannel的配置信息
安装了Flannel以后各节点的变化:
[root@k8s-master k8s]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.0 netmask 255.255.255.255 broadcast 0.0.0.0
[root@k8s-master k8s]# ifconfig cni
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.0.1 netmask 255.255.255.0 broadcast 0.0.0.0
[root@k8s-node1 ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.1.0 netmask 255.255.255.255 broadcast 0.0.0.0
[root@k8s-node1 ~]# ifconfig cni
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.1.1 netmask 255.255.255.0 broadcast 0.0.0.0
[root@k8s-node2 ~]# ifconfig flannel.1
flannel.1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.2.0 netmask 255.255.255.255 broadcast 0.0.0.0
[root@k8s-node2 ~]# ifconfig cni
cni0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1450
inet 10.244.2.1 netmask 255.255.255.0 broadcast 0.0.0.0
可以看到每个节点都多了几个虚拟的网络接口
需要注意的是cni0虚拟网桥,仅作用于本地Pod之间的通信,flanneld为每个Pod创建一对veth虚拟设备,一端放在容器接口上,一端放在cni0桥上。
flannel.1是一个tun虚拟网卡,接收不在同一主机的Pod的数据,然后将收到的数据转发给flanneld进程
查看CNI网桥信息
[root@k8s-master ~]# brctl show cni0
bridge name bridge id STP enabled interfaces
cni0 8000.0a580af40001 no veth020fafae
当kubelet创建容器时,将为此容器创建虚拟网卡vethxxx,并桥接到cni0网桥,下图就是veth的情况:
POD 通信方式验证:
查看K8S 各节点的应用Pod
[root@k8s-master k8s]# kubectl get pods -o wide|egrep myapp-deploy |awk '{print $1,$6,$7}'
myapp-deploy-675558bfc5-7jbg7 10.244.2.127 k8s-node2
myapp-deploy-675558bfc5-b47ng 10.244.2.126 k8s-node2
myapp-deploy-675558bfc5-d7h6k 10.244.1.15 k8s-node1
1.pod1和pod2在同一节点上:
由cni0网桥直接转发请求到pod2,不需要经过flannel,当然节点访问本地的Pod也是这样的
pod1 ip 10.244.2.127 pod2 ip 10.244.2.126
[root@k8s-master ~]# kubectl exec -it myapp-deploy-675558bfc5-7jbg7 -- ping 10.244.2.126
[root@k8s-node2 ~]# tcpdump -i cni0 -vnn host 10.244.2.126
tcpdump: listening on cni0, link-type EN10MB (Ethernet), capture size 262144 bytes
21:54:59.699556 IP (tos 0x0, ttl 64, id 19518, offset 0, flags [DF], proto ICMP (1), length 84)
10.244.2.127 > 10.244.2.126: ICMP echo request, id 11520, seq 26, length 64
21:54:59.699610 IP (tos 0x0, ttl 64, id 23415, offset 0, flags [none], proto ICMP (1), length 84)
10.244.2.126 > 10.244.2.127: ICMP echo reply, id 11520, seq 26, length 64
[root@k8s-node2 ~]# tcpdump -i flannel.1 -vnn host 10.244.2.126
没有数据包!!!!
2.pod1和pod2在不同的节点上:
上面已经介绍了不同节点Pod通过第三方插件工作的模式
这里实例验证一下:
下面是从pod1 ping pod2的数据包流向
pod1 ----> node1 pod IP 10.244.1.15 cni0 10.244.1.1
pod2 ----> node2 pod IP 10.244.2.127 cni0 10.244.2.1
master上查看路由表信息:
[root@k8s-master ~]# ip route show
......
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink
......
抓包验证一下:
[root@k8s-master ~]#kubectl exec -it myapp-deploy-675558bfc5-d7h6k -- ping 10.244.2.127
抓包情况如下:
[root@k8s-node1 ~]# tcpdump -i flannel.1 -vnn host 10.244.2.127
22:33:49.295137 IP 10.244.1.15 > 10.244.2.127: ICMP echo request, id 837, seq 1, length 64
22:33:49.295933 IP 10.244.2.127 > 10.244.1.15: ICMP echo reply, id 837, seq 1, length 64
下面是这次ping数据包的wireshark解析出的协议数据:
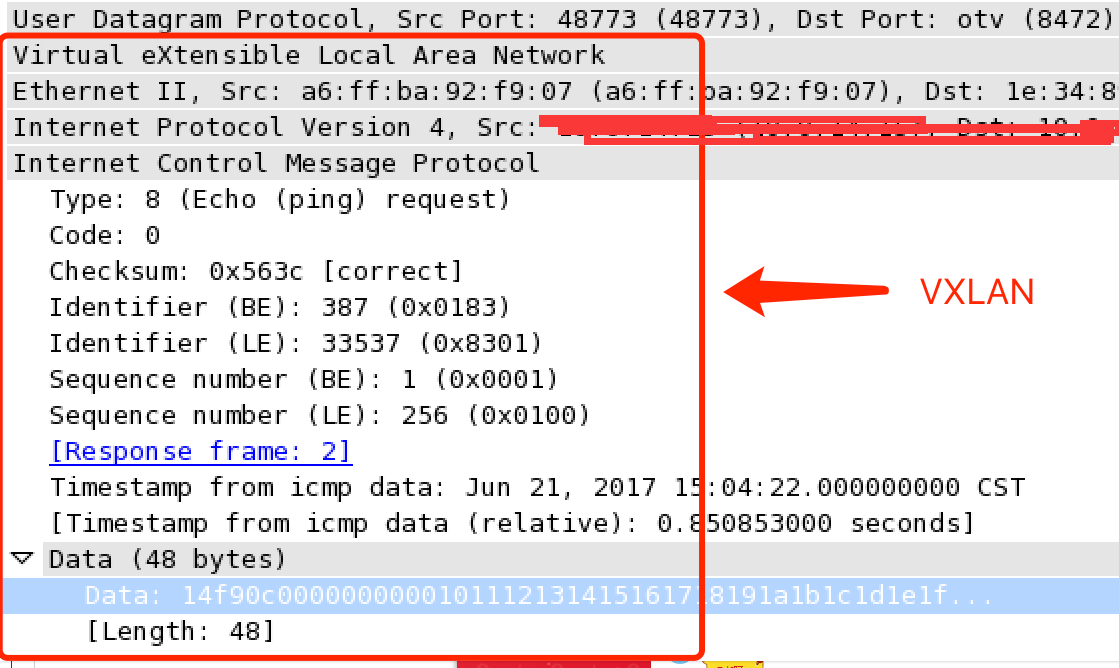
可以看到报文都是经过flannel.1网络接口进入2层隧道进而转发的,验证上面的通信方式,大概流程梳理一下
1. pod1向pod2发送ping,查找pod1路由表,把数据包发送到cni0(10.244.1.1)
2. cni0查找node1路由,把数据包转发到flannel.1
3. flannel.1虚拟网卡再把数据包转发到它的驱动程序flannel
4. flannel程序使用VXLAN协议封装这个数据包,向api-server查询目的IP所在的主机IP,node2(不清楚什么时候查询)
5. flannel查找到的node2 IP的UDP端口8472传输数据包
6. node2的flannel收到数据包后,解包,然后转发给flannel.1虚拟网卡
7. flannel.1虚拟网卡查找node2路由表,把数据包转发给cni0 (10.244.2.1),cni0网桥再把数据包转发给pod2
8. pod2响应给pod1的数据包与1-7步类似
总结:
发送到10.244.1.0/24和10.244.2.0/24网段的数据报文发给本机的flannel.1接口,
即进入二层隧道,然后对数据报文进行封装(
封装VxLAN首部-->UDP首部-->IP首部-->以太网首部),
到达目标Node节点后,由目标Node上的flannel.1进行解封装,可以看下图的工作流程
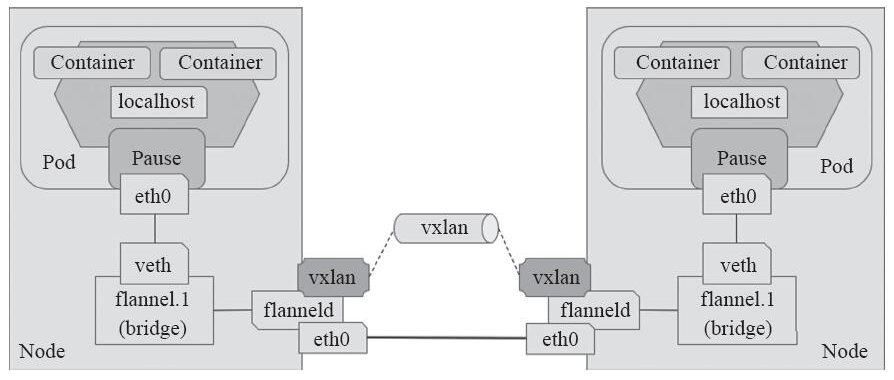
同理:节点访问另一个节点POD 工作方式和上面一样,这里抓 包验证一下:
master flannel.1 10.244.0.0/24
#master ping测试访问另一个节点Pod ip
[root@k8s-master ~]# ping 10.244.1.15
PING 10.244.1.15 (10.244.1.15) 56(84) bytes of data.
64 bytes from 10.244.1.15: icmp_seq=1 ttl=64 time=0.291 ms
64 bytes from 10.244.1.15: icmp_seq=2 ttl=64 time=0.081 ms
#ping后抓包情况如下
[root@k8s-master ~]# tcpdump -i flannnel.1 -nn host 10.244.1.15
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on flannel.1, link-type EN10MB (Ethernet), capture size 262144 bytes
22:22:35.737977 IP 10.244.0.0 > 10.244.1.15: ICMP echo request, id 29493, seq 1, length 64
22:22:35.738902 IP 10.244.1.15 > 10.244.0.0: ICMP echo reply, id 29493, seq 1, length 64
通过上面得知,默认用的flannel vxlan 使用叠加网络 模式
VXLAN由于额外的封包解包,导致其性能较差,所以Flannel就有了host-gw模式,即把宿主机当作网关,
除了本地路由之外没有额外开销,性能和calico差不多,由于没有叠加来实现报文转发,因为一个节点对应一个网络,也就对应一条路由条目。
VXLAN还有另外一种功能,VXLAN也支持类似host-gw的玩法,
如果两个节点在同一网段时使用host-gw通信,如果不在同一网段中,
即当前pod所在节点与目标pod所在节点中间有路由器,
就使用VXLAN这种方式
结合了Host-gw和VXLAN这就是VXLAN 的Direct routing(直接路由)模式
下面修改一下VXLAN 为使用直接路由模式
[root@k8s-master flannel]# kubectl edit configmap kube-flannel-cfg -n kube-system
注意:这样修改是不生效的 前面说过,运行的flannel修改配置是无用的
[root@k8s-master flannel]# ip route show
default via 10.211.55.1 dev eth0 proto dhcp metric 100
10.211.55.0/24 dev eth0 proto kernel scope link src 10.211.55.11 metric 100
10.244.0.0/24 dev cni0 proto kernel scope link src 10.244.0.1
10.244.1.0/24 via 10.244.1.0 dev flannel.1 onlink
10.244.2.0/24 via 10.244.2.0 dev flannel.1 onlink
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
172.18.0.0/16 dev br-18d0011e4542 proto kernel scope link src 172.18.0.1
下面这种方式比较暴力,生产环境要慎重:
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
修改文件kube-flannel.yml文件里面的net-conf.json
net-conf.json: |
{
"Network": "10.244.0.0/16",
"Backend": {
"Type": "vxlan",
"Directrouting": true
}
}
kubectl delete -f kube-flannel.yaml
kubectl apply -f kube-flannel.yaml
[root@k8s-node2 ~]# ip route show
default via 10.211.55.1 dev eth0 proto dhcp metric 100
10.211.55.0/24 dev eth0 proto kernel scope link src 10.211.55.12 metric 100
10.244.0.0/24 via 10.211.55.11 dev eth0
10.244.1.0/24 via 10.211.55.13 dev eth0
10.244.2.0/24 dev cni0 proto kernel scope link src 10.244.2.1
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
进入Pod 然后ping另一个节点的Pod
kubectl exec -it myapp-deploy-675558bfc5-7jbg7 -- ping 10.244.1.15
然后在节点 抓包
[root@k8s-node1 ~]# tcpdump -i eth0 -vnn icmp
tcpdump: listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
19:35:30.710956 IP (tos 0x0, ttl 63, id 37511, offset 0, flags [DF], proto ICMP (1), length 84)
10.244.2.127 > 10.244.1.15: ICMP echo request, id 4608, seq 0, length 64
19:35:30.711178 IP (tos 0x0, ttl 63, id 51914, offset 0, flags [none], proto ICMP (1), length 84)
10.244.1.15 > 10.244.2.127: ICMP echo reply, id 4608, seq 0, length 64
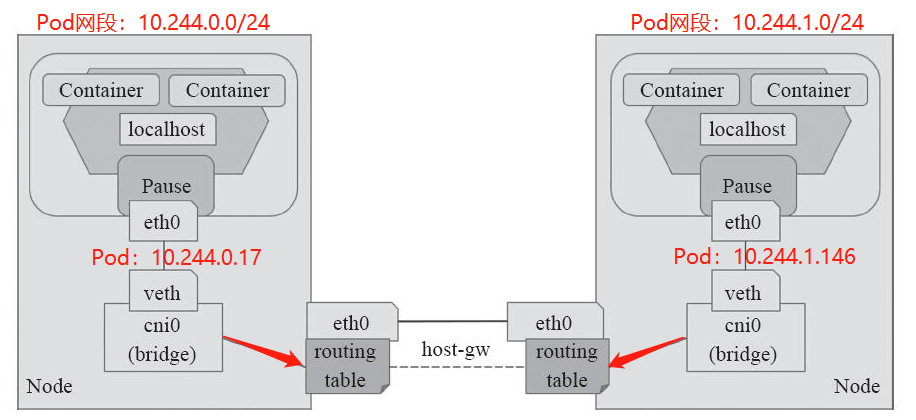
二:Host-GW:Host Gateway
优点: 性能好,依赖少,并且易于设置。
缺点:要求各节点在同一个网络下,小规模集群使用。
Type:
Type:字符串,host-gw
工作模式流程图如下
三:UDP
不可用于生产环境。仅在内核或网络无法使用 VXLAN 或 host-gw 时,用 UDP 进行 debug。
Type 和选项:
Type:字符串,udpPort:数字,用于发送封装数据包的 UDP 端口号,默认是 8285
Vxlan 优化:在同一网络,直接用hostGW这种方式,如果不在同一网络用Vxlan (叠加网络模式)
总的来说,flannel更像是经典的桥接模式的扩展。我们知道,在桥接模式中,每台主机的容器都将使用一个默认的网段,容器与容器之间,主机与容器之间都能互相通信。要是,我们能手动配置每台主机的网段,使它们互不冲突。接着再想点办法,将目的地址为非本机容器的流量送到相应主机:如果集群的主机都在一个子网内,就搞一条路由转发过去;若是不在一个子网内,就搞一条隧道转发过去。这样以来,容器的跨网络通信问题就解决了。而flannel做的,其实就是将这些工作自动化了而已。















 3099
3099











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









