







郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布!
1、Abstract:
本文主要介绍的是2015年以来关于深度图像/视频编码的代表性工作,主要可以分为两类:深度编码方案以及基于传统编码方案的深度工具。对于深度编码方案,像素概率建模和自动编码器是两种方法,分别可以看作是预测编码方案和变换编码方案。对于深度工具,有几种使用深度学习来执行帧内预测、帧间预测、跨通道预测、概率分布预测、变换、后处理、环内滤波器、上/下采样以及编码优化的建议技术。为了倡导基于深度学习的视频编码研究,本文对我们开发的视频编解码器即深度学习视频编码(Deep Learning Video Coding,DLVC)进行了案例研究。DLVC具有两个深度工具,分别为基于CNN的环路滤波器(CNN-based in-loop filter,CNN-ILF)以及基于CNN的块自适应分辨率编码(CNN-based block adaptive resolution coding,CNN-BARC)。这两种工具都有助于显著提高压缩效率。在随机存取和低延迟配置下,利用这两种深度工具以及其他非深度编码工具,DLVC比HEVC平均节省39.6%和33.0%的比特。
2、Introduction:
A. Image/Video Coding:
有损图像/视频编码解决方案的评价分为两个方面:一是压缩效率,通常用比特数(编码率)来衡量,越低越好;二是产生的损失,通常用重建图像/视频的质量来衡量,与原始图像/视频相比,越高越好。
目前,H.265/HEVC已于2013年正式发布,代表着最先进的图像/视频编码技术。随着视频技术的进步,特别是超高清晰度(ultra-high definition,UHD)视频的普及,迫切需要进一步提高压缩效率,以便在有限的存储空间和有限的传输带宽中容纳UHD视频。因此,在HEVC、MPEG和VCEG组成联合视频专家组(the Joint Video Experts Team,JVET)后,对先进的视频编码技术进行了探索,并开发了联合探索模型(Joint Exploration Model,JEM)进行了研究。此外,自2018年以来,JVET团队一直致力于开发一种新的视频编码标准,即多功能视频编码(Versatile Video Coding,VVC),作为HEVC的继承者。与HEVC相比,VVC可以在保持相同质量的同时节省约50%的比特,特别是对于UHD视频,从而提高压缩效率。然而,值得注意的是,VVC的改进可能以牺牲乘法编码/解码的复杂性为代价。
B. Deep Learning for Image/Video Coding:
本文旨在对最新的基于深度学习的图像/视频编码报告(截至2018年底)进行全面回顾,并对我们开发的原型视频编解码器即深度学习视频编码(DLVC)进行案例研究,以使感兴趣的读者了解现状。读者也可以参考[84]获取关于同一主题的最近发表的评论论文。
C. Preliminaries:
在本文中,我们考虑了自然图像/视频的编码方法,即人们通过日常相机或手机拍摄的图像/视频。虽然这些方法通常都适用,但它们是专门为自然图像/视频设计的,对于其他类型(如生物医学、遥感)来说,它们可能表现不太好。
目前,几乎所有的自然图像/视频都是数字格式。灰度数字图像可以表示为Dm x n,其中m和n是图像的行数(高度)和列数(宽度),D是单个图片元素(像素)的定义域。例如,D={0,1,……,255}是一种常用设置,其中|D|=256=28。因此,像素值可以用一个8位整数表示;因此,未压缩的灰度数字图像每像素有8位(bits-per-pixel,bpp),而压缩后的比特更少。
因为人类的视觉对亮度比色度更敏感,所以YCbCr(YUV)颜色空间比RGB采用的要多得多,U和V通道通常采用下采样以实现压缩。现有的无损编码方法对自然图像的压缩比可以达到1.5~3,明显低于实际需求。因此,引入有损编码来压缩更多的数据,但代价是造成损失。损失可以通过原始图像和重建图像之间的差异来测量,例如,对灰度图像使用均方误差(mean-squared-error,MSE)。此外,重建图像与原始图像相比的质量可以通过峰值信号音调比(peak signal-tonoise ratio,PSNR)来测量。对于彩色图像/视频,通常单独计算Y、U、V的PSNR值。对于视频,通常分别计算不同帧的PSNR值,然后取其平均值。在PSNR的替代中还有其他质量指标,如结构相似性(structural similarity,SSIM)和多尺度SSIM(multi-scale SSIM,MS-SSIM)[126]。
为了比较不同的无损编码方案,只需比较压缩比或结果率(bpp、bps等)。为了比较不同的有损编码方案,有必要同时考虑码率和质量。例如,计算几个不同质量水平下的相对码率,然后对码率进行平均,这是一种常用的方法;平均相对码率被称为Bjontegaard’s delta-rate (BD-rate)[13]。评价图像/视频编码方案还有其他重要方面,包括编码/解码的复杂性、可扩展性、鲁棒性等。
3、Review of deep schemes:
在本节中,我们将回顾一些具有代表性的深度编码方案。一般来说,深度图像编码有两种方法,即像素概率建模和自动编码器。这两种方法在几个深度学习方案中结合在一起。此外,我们还讨论了深度视频编码方案和特殊用途编码方案,其中特殊用途编码方案又可以进一步分为感知编码和语义编码。
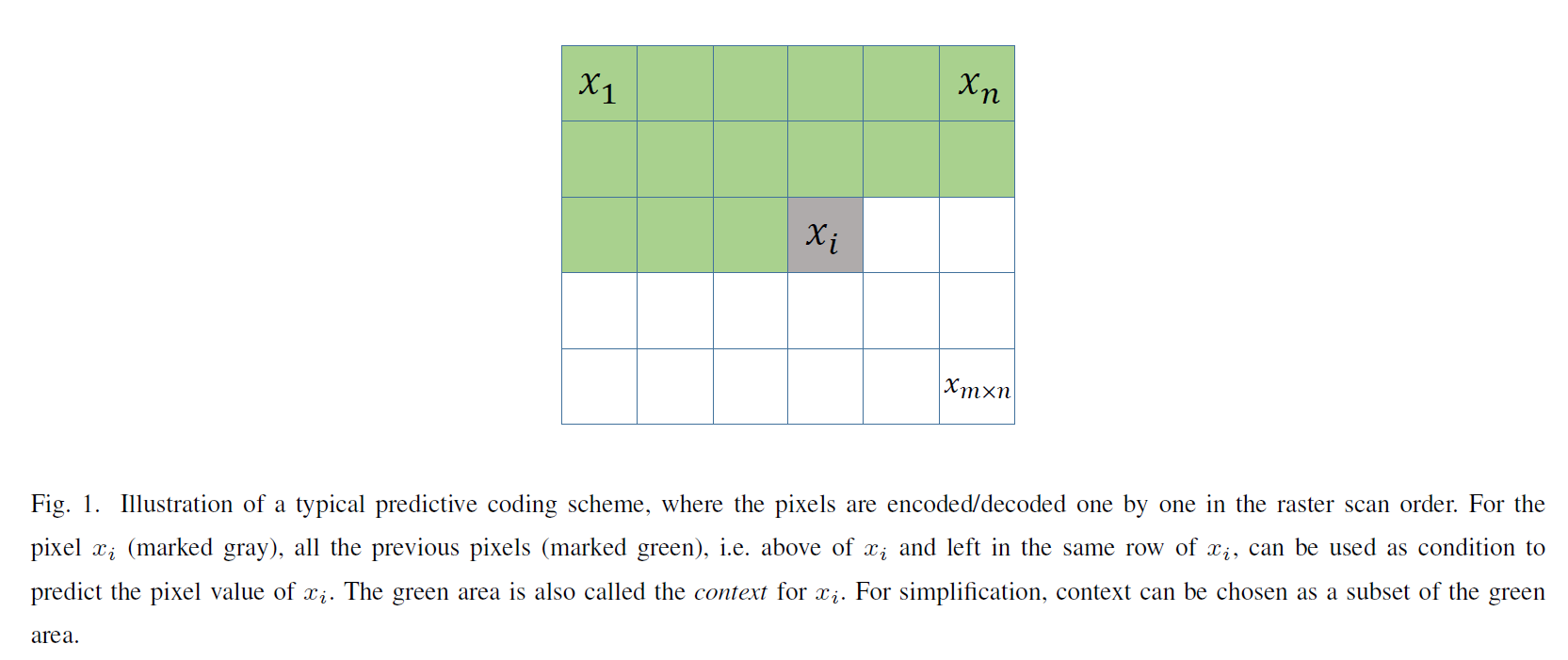
A. Pixel Probability Modeling:
根据香农的信息理论[102],无损编码的最优方法可以达到的最小值为- log2p(x),其中p(x)是符号x的概率。为了达到这一目标,人们发明了许多无损编码方法,并且认为算术编码[129]是最理想的方法之一。给定概率 p(x) ,算术编码确保编码码率尽可能接近 - log2p(x) 。因此,剩下的问题是找出概率,但这对于自然图像/视频来说是非常困难的,因为它具有很高的维度。
估计 p(x) 的一种方法是将图像分解为 m x n 像素,并逐个估计这些像素的概率(例如以光栅扫描顺序)。这是一种典型的预测编码策略,注意:
![]()
如图1所示,这里 xi 的条件也称为 xi 的上下文。当图像较大时,条件概率很难估计。简化是为了减少上下文的范围,例如:
![]()
其中。 k 是一种预设定的常数。
众所周知,深度学习擅长解决回归和分类问题。因此,在给定上下文 x1, ... , xi-1 的情况下,建议使用经过训练的深度网络来估计概率 p(xi | x1, ... , xi-1) 。早在2000年就有人提出了这种策略[12]用于其他类型的高维数据,但直到最近才应用于图像/视频。例如,在[58]中,考虑二值图像的概率估计, xi 取 +1 或 -1 ,可以预测每个像素的概率值 p(xi = +1 | x1, ... , xi-1) 。这篇文章提出了一种神经自回归分布估计方法(the neural autoregressive distribution estimator,NADE),即对每个像素使用一个隐层的前馈网络,并在这些网络中共享参数。参数共享也有助于加速每个像素的计算。在[37]中也有类似的工作,其中前馈网络也有跳过隐层的连接,并且参数也被共享。[58]和[37]都对二值化的MNIST数据集(http://yann.lecun.com/exdb/mnist/.)进行了实验。Uria等人[116]将NADE扩展到实值NADE(real-valued NADE,RNADE),其中概率p(xi | x1, ... , xi-1)由高斯混合分布构成,前馈网络需要为高斯混合模型输出一组参数,而不是NADE中的单个值。他们的前馈网络有一个隐层和参数共享,但隐层加入了重新缩放以避免饱和,并使用校正线性单元(rectified linear unit,ReLU)[90]而不是sigmoid。他们还考虑到拉普拉斯混合分布而不是高斯混合分布。他们在 8 x 8 的自然图像进行了实验,其中将像素值加入噪声,转换为真实值。在[117]中,NADE和RNADE通过使用不同的像素顺序以及网络中使用更多隐层来改进。在[120]中,通过使用深度GMM来增强高斯混合模型(the Gaussian mixture model,GMM),RNADE得到了改进。
先进网络的设计是提高像素概率建模的重要课题。在[109]中,提出了基于多维长短期存储器(long short-term memory,LSTM)的网络,以及对条件高斯尺度混合的混合。后者是GMM的一个推广,用于概率建模。LSTM是一种递归神经网络(RNNs),被认为擅长对序列数据进行建模。LSTM的空间变体被用于图像。然后在[118]中,研究了几个不同的网络,包括RNNs和CNNs,分别被称为PixelRNN和PixelCNN。对于PixelRNN,提出了两种LSTM变体,称为行LSTM和对角线BiLSTM,后者专门为图像设计。PixelRNN整合了残差连接[40]来帮助训练高达12层的深度网络。对于PixelRNN,为了适应上下文的形状(见图1),提出了屏蔽卷积(masked convolutions)。PixelCNN也有15层的深度。与之前的作品相比,PixelRNN和PixelCNN更专注于自然图像:他们将像素视为离散值(例如0,1,……,255),并预测离散值的多项式分布;他们处理彩色图像(在RGB颜色空间中);多尺度PixelRNN被提出;它们在CIFAR-10和ImageNet数据集上工作得很好。相当多的研究遵循了PixelRNN和PixelCNN的方法。在[119]中,门控PixelCNN(Gated PixelCNN)被提议改进PixelCNN,并达到与PixelCNN相当的性能,但其复杂性要低得多。在[99]中,PixelCNN++提出了对PixelCNN的以下改进:使用离散化的逻辑混合概率而不是256路多项式分布;下采样用于捕获多分辨率的结构;为加速训练引入了额外的短路连接;正则化采用随机失活(Dropout);一个像素包含RGB。在[18]中,提出了PixelSNAIL,其中随意卷积(casual convolutions)与自我注意力(self attention)相结合。
上面提到的大多数工作都直接模拟像素概率。此外,像素概率可以通过显式或隐式表示作为条件概率建模。也就是说,我们可以估计:
![]()
其中 h 是附加条件。还要注意,p(x)=p(h)p(x|h),这意味着建模分为无条件的和有条件的。例如,在[119]中,附加条件可以是由另一个深度网络派生的图像类或高级图像表示。在[56]中,考虑了带有潜在变量的PixelCNN,其中潜在变量来自原始图像:它们可以是原始彩色图像的量化灰度版本,也可以是多分辨率图像金字塔。
对于实际的图像编码方案,在[64]中,采用了一个具有修剪卷积的网络来预测二进制数据的概率,而一个8位的灰度图像(大小为 m x n )被转换成一个 m x n x 8 的二进制立方体,由网络进行处理。该网络类似于PixelCNN,但是三维的。据报道,基于网络的修剪卷积算术编码(The trimmed convolutional network-based arithmetic encoding,TCAE)比以前的非深度无损编码方案(如TIFF、GIF、PNG、JPEG-LS和JPEG 2000-LS)要好。在 Kodak 图像集中,TCAE达到2.00的压缩比。不同的是,在[4]中,CNN用于小波变换域,而不是像素域,即CNN用于从相邻子带内的系数预测小波细节系数。
对于视频编码,在[52]中,PixelCNN被概括为视频像素网络(video pixel network,VPN),用于视频像素概率建模。VPN由CNN编码器(用于预测当前帧)和PixelCNN解码器(用于当前帧内的预测)。CNN编码器在所有层保留输入帧的空间分辨率,以最大化表示能力。采用扩张卷积扩大接收场,更好地捕捉全局运动。随着时间的推移,CNN编码器的输出与一个卷积LSTM相结合,该LSTM还保留了分辨率。PixelCNN解码器使用屏蔽卷积,并在离散像素值上采用多项式分布。
此外,Schiopu等人[101]研究一种无损图像编码方案,他们使用CNN预测像素值,而不是其分布。预测值从实际像素值中减去,从而产生残差,然后进行编码。此外,他们还考虑了CNN预测器和一些非CNN预测器中的自适应选择。
B. Auto-Encoder:
自动编码器源于Hinton和Salakhutdinov[42]的著名工作,通过训练一个由编码部分和解码部分组成的网络进行降维。编码部分将输入的高维信号转换为低维表示,解码部分从低维表示中恢复(不完全)高维信号。自动编码器实现了表示的自动学习,消除了手工制作功能的需要,这也是深度学习最重要的优点之一。
采用自动编码器网络进行有损图像编码似乎很简单:编码和解码都经过训练,我们只需要对学习到的表示进行编码。然而,传统的自动编码器没有针对压缩进行优化,直接使用一个训练好的自动编码器不是一种有效的手段[127]。当我们考虑到压缩需求时,有几个挑战:首先,对低维表示进行量化,然后进行编码,但量化步骤不可微,使得网络训练困难。第二,有损编码是为了在码率和质量之间实现更好的权衡,因此在训练网络时应考虑码率,但码率不容易计算或估计。第三,一个实用的图像编码方案需要考虑可变码率、可伸缩性、编码/解码速度、互操作性等因素。针对这些挑战,近年来进行了大量的研究。
基于自动编码器的图像编码方案的概念图如下图所示,这是一种典型的变换编码策略。
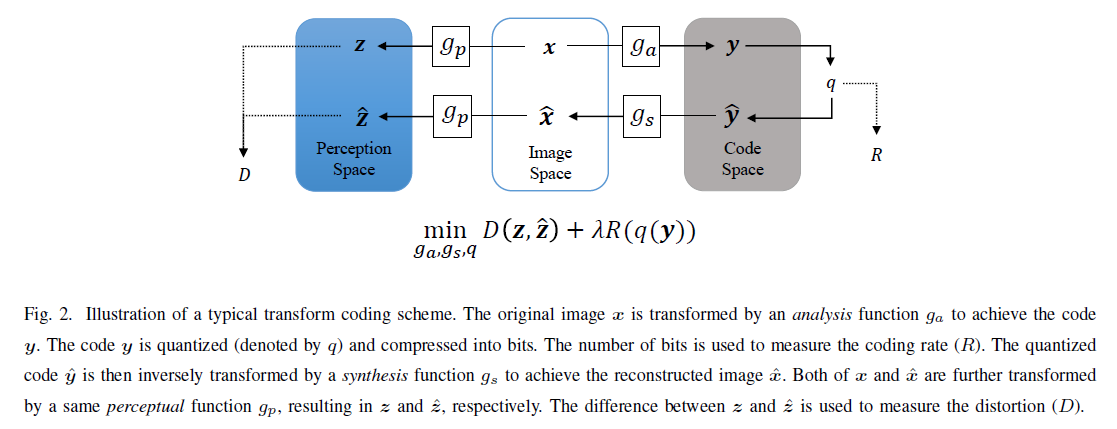
在网络结构上,RNN和CNN是应用最广泛的两类。最具代表性的作品包括:
- Toderici等人[111]提出了一种可变码率图像压缩的通用框架。他们使用二值化来生成代码,并且在训练过程中不考虑码率,即损失只是端到端的失真,用MSE度量。他们的框架确实提供了一个可扩展的编码功能,其中具有卷积和反卷积层的RNN(特别是LSTM),据报道性能良好。对 32 x 32 的缩略图,他们提供了在大规模数据集上的测试结果。后来,Toderici等人[112]提出了一个改进的版本,他们使用PixelRNN[118]这样的神经网络来压缩二进制代码;他们还引入了一个新的门控循环单元(gated recurrent unit,GRU),其灵感来自于残差网络(the residual network,ResNet)[40]。他们在使用MS-SSIM作为质量度量的Kodak图像集上得到了比JPEG更好的结果。Johnston等人[51]进一步改进基于RNN的方法,使用SSIM加权损失函数将隐藏状态启动引入RNN,并启动空间自适应比特率。他们在使用MS-SSIM作为质量度量的Kodak图像集上获得了比BPG更好的效果。Covell等人[22]通过训练允许停止代码的RNN来启用空间自适应比特率。
- Ball'e等人[9]提出了率失真优化图像压缩的通用框架。他们使用多变量量化来生成整数代码,并在训练期间考虑码率,即损失是率失真联合成本,其中失真可能是MSE或其他。为了估计码率,他们在训练过程中使用随机噪声代替量化,并使用噪声“代码”的差分熵作为码率的代表。对于网络结构,采用了广义除数归一化(the generalized divisive normalization,GDN)变换,该变换由线性映射(矩阵乘法)和非线性参数归一化组成。在[8]中验证了GDN对图像编码的有效性。后来,Ball'e等人[10]提出一个改进的版本,其中他们使用3个卷积层,每个卷积层后紧接着下采样和一个GDN操作来实现变换;相应地,使用3个逆GDN+上采样+卷积层来实现反变换。此外,他们还设计了一种算术编码方法来压缩整数码。他们在使用MSE作为质量度量的Kodak图像集上取得了比JPEG和JPEG 2000更好的结果。此外,Ball'e等人[11]通过在自动编码器中加入一个尺度超先验来改进他们的方案,这是受到变分自动编码器的启发[55]。他们使用另一个变换 ha 将 y 转换为 w=ha(y),对 w 进行量化和编码(作为边信息传输),并使用另一个反变换 hs 将解码后的 w ^ 转换为量化后的 y ^ 的估计标准偏差,然后在对 y ^ 进行算术编码时使用。在Kodak图像集上使用PSNR作为质量度量,他们的方法只比BPG稍差。
除[9]外,一些工作还集中于处理不可微量化和/或码率估计。Theis等人[110]采用一种非常简单的方法进行量化:量化通常在前通中进行,但梯度直接通过后通中的量化层。令人惊讶的是,这项工作进展顺利。此外,他们将码率替换成了一个可微的上界。Dumas等人[29]考虑一个随机优胜者全得机制,其中 y 中具有最大绝对值的条目被保留,其他条目被设置为0;然后这些条目被统一量化和压缩。Agustsson等人[2]提出一种从软到硬的矢量量化方案,在该方案中,他们在训练过程中使用软量化(即分配一个表征给具有不同成员值的多个代码),而不是硬量化(即分配一个表征给仅一个代码),并且他们采用退火过程使软量化方法逐渐向硬量化转变。值得注意的是他们的计划利用了矢量量化而其他作品通常采用标量量化。Li等人[65]引入一个用于码率估计的重要性图,重要性图被量化为一个掩模,掩模决定每个位置保留多少比特,因此重要性图的和可以用作编码码率的粗略估计。
除[111]外,一些工作还考虑了可变码率的功能,对不同码率进行较少训练或者不进行训练。在[110]中,引入了比例参数,并针对不同的码率对预训练的自动编码器进行了微调。在[30]中提出了一种由学习得到的独特变换,以及针对不同码率的可变量化步骤。在[15]中,针对所有尺度对多尺度分解变换进行了训练和优化;并提供了码率分配算法,针对目标码率或目标质量因子,确定每个图像块的最佳尺度。此外,可伸缩编码在[146]中的考虑与在[111]中的不同。在[146]中,图像被分解成多个位平面,并被并行转换和量化;为了减少不同位平面之间的相关性,提出了双向组合选通单元。
有几项工作考虑了先进的网络结构和不同的损失函数。Theis等人[110]采用亚像素结构以提高计算效率。Rippel和Bourdev[97]提出了一个金字塔分解,然后是规模间校准网络,它是轻量级的,并且实时运行。除重建损失外,他们还使用了鉴别损失。Snell等人[104]使用MS-SSIM作为损失函数,而不是MSE或平均绝对误差(MAE)来训练自动编码器,他们发现MS-SSIM能够更好地校准感知质量。Zhou等[149]使用更深的网络设计编码器/解码器,并在解码器中使用单独的网络进行后处理。他们还将[11]中的高斯模型替换为拉普拉斯模型。
如前所述,像素概率模型表示预测编码,自动编码器表示变换编码。这两种策略可以结合起来提高压缩效率。Mentzer等人[87]提出了一种实用的无损图像编码方案,利用多层次的自动编码器学习像素概率建模的条件。Mentzer等人[86]将像素概率建模(a 3D PixelCNN)集成到自动编码器中,以估计编码码率,并对PixelCNN和自动编码器进行联合训练。Baig等人[6]在可变码率压缩框架[111]中引入局部上下文图像,该框架实际上是根据块的上下文预测块,假设块按光栅扫描顺序逐个编码/解码。将预测信号加到网络输出信号上,实现 x^ ,即变换编码网络处理预测残差。Minen等人[89]另外考虑各区块之间的码率分配。同样,但以不同的方式,Minnen等人[88]在[11]基础上改进,通过增加超先验与上下文,即他们不仅使用 w^ 而且还使用上下文来预测每次进入 y^ 的概率。他们的方法在使用PSNR作为质量度量的Kodak图像集上优于BPG,这代表了到2018年底的最新技术。Lee等人[60]将上下文自适应熵模型引入超先验W^。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 3409
3409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









